 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the Effect of Class Imbalance on the Learning Dynamics
Paper and Code

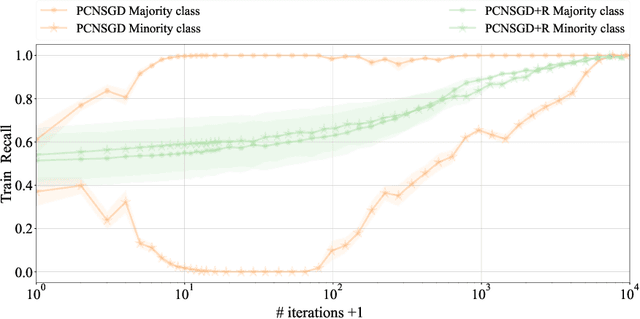
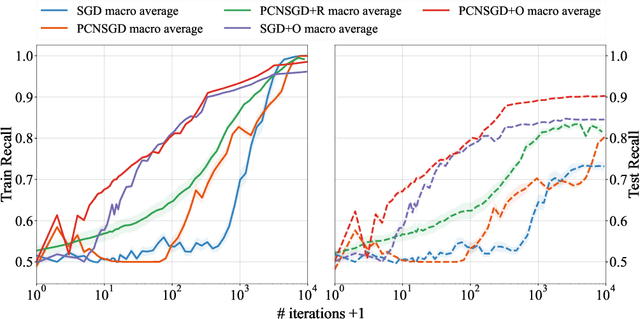
Data imbalance is a common problem in the machine learning literature that can have a critical effect on the performance of a model. Various solutions exist - such as the ones that focus on resampling or data generation - but their impact on the convergence of gradient-based optimizers used in deep learning is not understood. We here elucidate the significant negative impact of data imbalance on learning, showing that the learning curves for minority and majority classes follow sub-optimal trajectories when training with a gradient-based optimizer. The reason is not only that the gradient signal neglects the minority classes, but also that the minority classes are subject to a larger directional noise, which slows their learning by an amount related to the imbalance ratio. To address this problem, we propose a new algorithmic solution, for which we provide a detailed analysis of its convergence behavior. We show both theoretically and empirically that this new algorithm exhibits a better behavior with more stable learning curves for each class, as well as a better generalization performance.