 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInitial Guessing Bias: How Untrained Networks Favor Some Classes
Paper and Code
Jun 01, 2023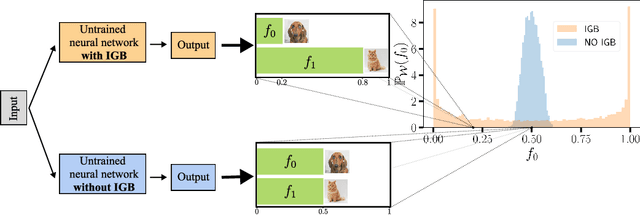
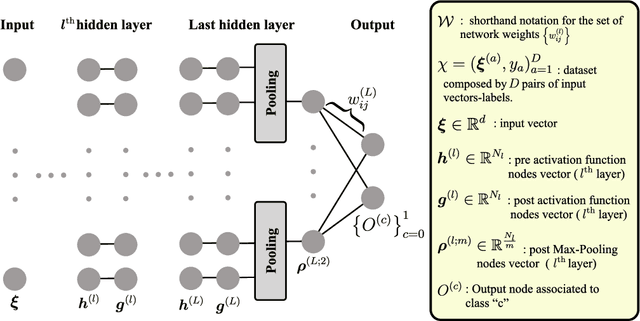


The initial state of neural networks plays a central role in conditioning the subsequent training dynamics. In the context of classification problems, we provide a theoretical analysis demonstrating that the structure of a neural network can condition the model to assign all predictions to the same class, even before the beginning of training, and in the absence of explicit biases. We show that the presence of this phenomenon, which we call "Initial Guessing Bias" (IGB), depends on architectural choices such as activation functions, max-pooling layers, and network depth. Our analysis of IGB has practical consequences, in that it guides architecture selection and initialization. We also highlight theoretical consequences, such as the breakdown of node-permutation symmetry, the violation of self-averaging, the validity of some mean-field approximations, and the non-trivial differences arising with depth.