 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVanishing Curvature and the Power of Adaptive Methods in Randomly Initialized Deep Networks
Paper and Code
Jun 07, 2021
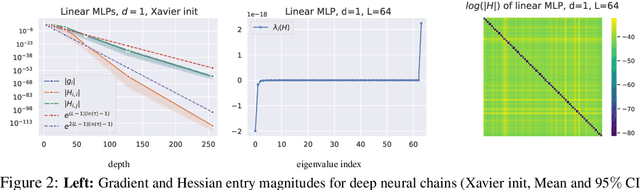

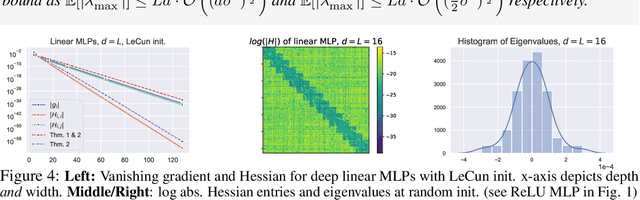
This paper revisits the so-called vanishing gradient phenomenon, which commonly occurs in deep randomly initialized neural networks. Leveraging an in-depth analysis of neural chains, we first show that vanishing gradients cannot be circumvented when the network width scales with less than O(depth), even when initialized with the popular Xavier and He initializations. Second, we extend the analysis to second-order derivatives and show that random i.i.d. initialization also gives rise to Hessian matrices with eigenspectra that vanish as networks grow in depth. Whenever this happens, optimizers are initialized in a very flat, saddle point-like plateau, which is particularly hard to escape with stochastic gradient descent (SGD) as its escaping time is inversely related to curvature. We believe that this observation is crucial for fully understanding (a) historical difficulties of training deep nets with vanilla SGD, (b) the success of adaptive gradient methods (which naturally adapt to curvature and thus quickly escape flat plateaus) and (c) the effectiveness of modern architectural components like residual connections and normalization layers.