 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Image Classification using Entailment Cone Embeddings
Apr 25, 2020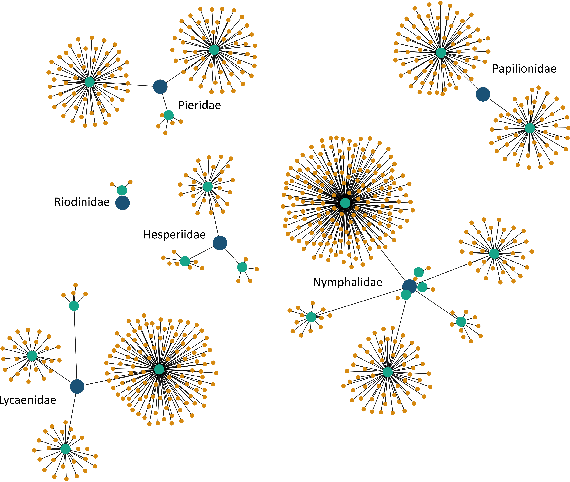
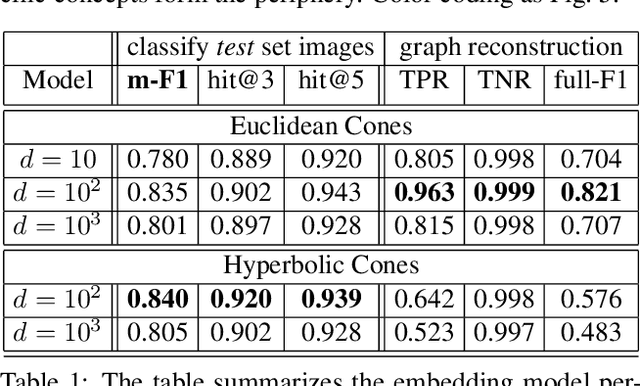
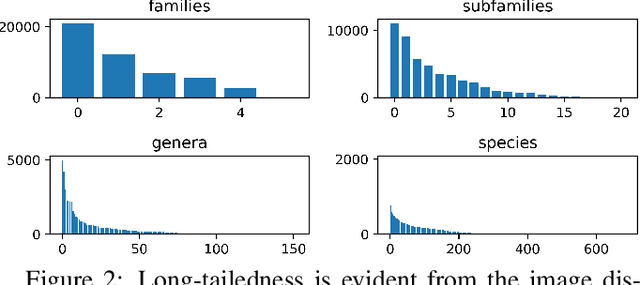
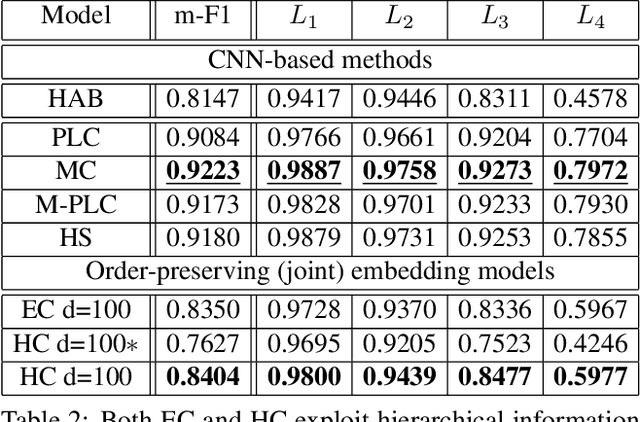
Image classification has been studied extensively, but there has been limited work in using unconventional, external guidance other than traditional image-label pairs for training. We present a set of methods for leveraging information about the semantic hierarchy embedded in class labels. We first inject label-hierarchy knowledge into an arbitrary CNN-based classifier and empirically show that availability of such external semantic information in conjunction with the visual semantics from images boosts overall performance. Taking a step further in this direction, we model more explicitly the label-label and label-image interactions using order-preserving embeddings governed by both Euclidean and hyperbolic geometries, prevalent in natural language, and tailor them to hierarchical image classification and representation learning. We empirically validate all the models on the hierarchical ETHEC dataset.
Learning Representations For Images With Hierarchical Labels
Apr 11, 2020



Image classification has been studied extensively but there has been limited work in the direction of using non-conventional, external guidance other than traditional image-label pairs to train such models. In this thesis we present a set of methods to leverage information about the semantic hierarchy induced by class labels. In the first part of the thesis, we inject label-hierarchy knowledge to an arbitrary classifier and empirically show that availability of such external semantic information in conjunction with the visual semantics from images boosts overall performance. Taking a step further in this direction, we model more explicitly the label-label and label-image interactions by using order-preserving embedding-based models, prevalent in natural language, and tailor them to the domain of computer vision to perform image classification. Although, contrasting in nature, both the CNN-classifiers injected with hierarchical information, and the embedding-based models outperform a hierarchy-agnostic model on the newly presented, real-world ETH Entomological Collection image dataset https://www.research-collection.ethz.ch/handle/20.500.11850/365379.
AMZ Driverless: The Full Autonomous Racing System
May 13, 2019

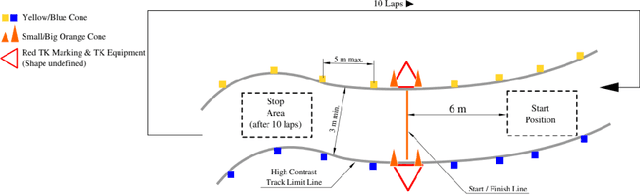

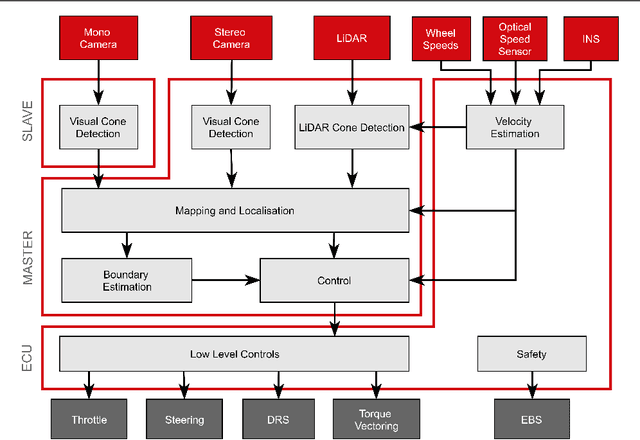
This paper presents the algorithms and system architecture of an autonomous racecar. The introduced vehicle is powered by a software stack designed for robustness, reliability, and extensibility. In order to autonomously race around a previously unknown track, the proposed solution combines state of the art techniques from different fields of robotics. Specifically, perception, estimation, and control are incorporated into one high-performance autonomous racecar. This complex robotic system, developed by AMZ Driverless and ETH Zurich, finished 1st overall at each competition we attended: Formula Student Germany 2017, Formula Student Italy 2018 and Formula Student Germany 2018. We discuss the findings and learnings from these competitions and present an experimental evaluation of each module of our solution.
Real-time 3D Traffic Cone Detection for Autonomous Driving
Feb 06, 2019
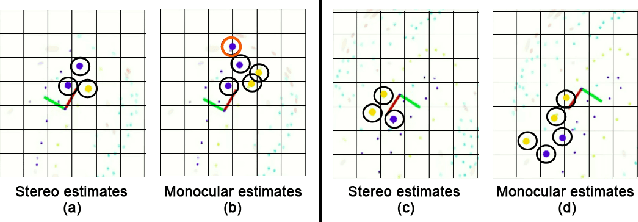


Considerable progress has been made in semantic scene understanding of road scenes with monocular cameras. It is, however, mainly related to certain classes such as cars and pedestrians. This work investigates traffic cones, an object class crucial for traffic control in the context of autonomous vehicles. 3D object detection using images from a monocular camera is intrinsically an ill-posed problem. In this work, we leverage the unique structure of traffic cones and propose a pipelined approach to the problem. Specifically, we first detect cones in images by a tailored 2D object detector; then, the spatial arrangement of keypoints on a traffic cone are detected by our deep structural regression network, where the fact that the cross-ratio is projection invariant is leveraged for network regularization; finally, the 3D position of cones is recovered by the classical Perspective n-Point algorithm. Extensive experiments show that our approach can accurately detect traffic cones and estimate their position in the 3D world in real time. The proposed method is also deployed on a real-time, critical system. It runs efficiently on the low-power Jetson TX2, providing accurate 3D position estimates, allowing a race-car to map and drive autonomously on an unseen track indicated by traffic cones. With the help of robust and accurate perception, our race-car won both Formula Student Competitions held in Italy and Germany in 2018, cruising at a top-speed of 54 kmph. Visualization of the complete pipeline, mapping and navigation can be found on our project page.
Real-time 3D Pose Estimation with a Monocular Camera Using Deep Learning and Object Priors On an Autonomous Racecar
Sep 27, 2018
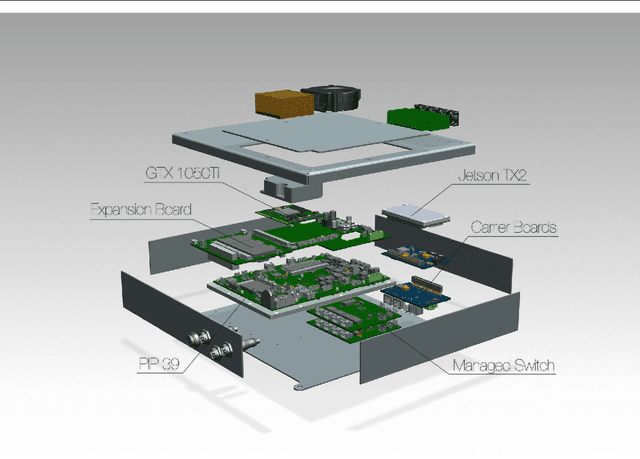
We propose a complete pipeline that allows object detection and simultaneously estimate the pose of these multiple object instances using just a single image. A novel "keypoint regression" scheme with a cross-ratio term is introduced that exploits prior information about the object's shape and size to regress and find specific feature points. Further, a priori 3D information about the object is used to match 2D-3D correspondences and accurately estimate object positions up to a distance of 15m. A detailed discussion of the results and an in-depth analysis of the pipeline is presented. The pipeline runs efficiently on a low-powered Jetson TX2 and is deployed as part of the perception pipeline on a real-time autonomous vehicle cruising at a top speed of 54 km/hr.
LiDAR-Camera Calibration using 3D-3D Point correspondences
May 27, 2017

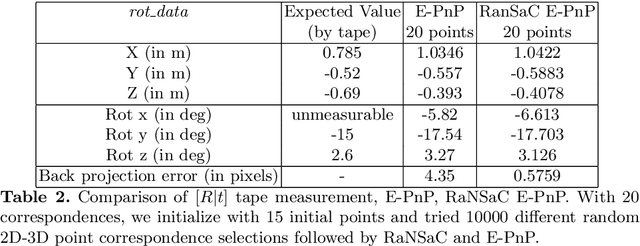
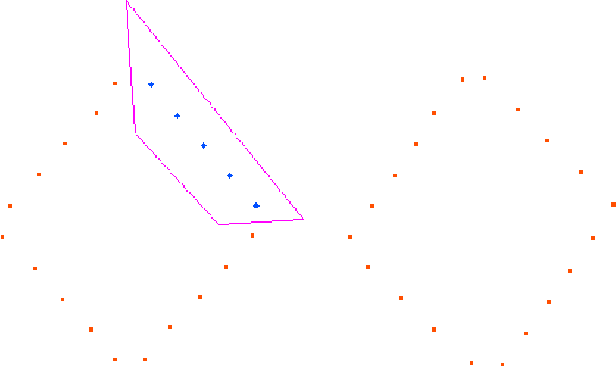
With the advent of autonomous vehicles, LiDAR and cameras have become an indispensable combination of sensors. They both provide rich and complementary data which can be used by various algorithms and machine learning to sense and make vital inferences about the surroundings. We propose a novel pipeline and experimental setup to find accurate rigid-body transformation for extrinsically calibrating a LiDAR and a camera. The pipeling uses 3D-3D point correspondences in LiDAR and camera frame and gives a closed form solution. We further show the accuracy of the estimate by fusing point clouds from two stereo cameras which align perfectly with the rotation and translation estimated by our method, confirming the accuracy of our method's estimates both mathematically and visually. Taking our idea of extrinsic LiDAR-camera calibration forward, we demonstrate how two cameras with no overlapping field-of-view can also be calibrated extrinsically using 3D point correspondences. The code has been made available as open-source software in the form of a ROS package, more information about which can be sought here: https://github.com/ankitdhall/lidar_camera_calibration .
On Optimizing Human-Machine Task Assignments
Sep 24, 2015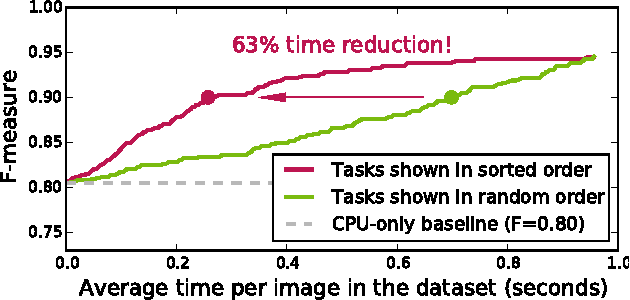
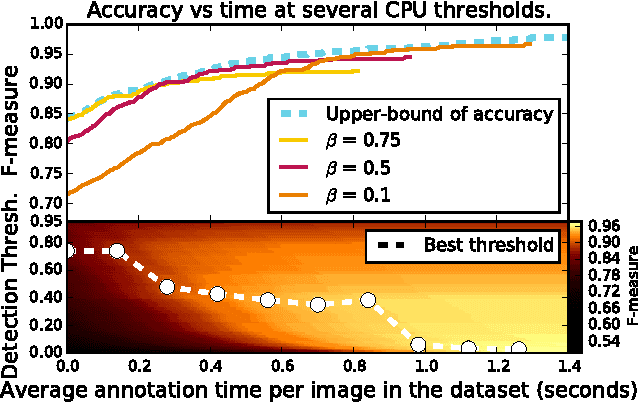
When crowdsourcing systems are used in combination with machine inference systems in the real world, they benefit the most when the machine system is deeply integrated with the crowd workers. However, if researchers wish to integrate the crowd with "off-the-shelf" machine classifiers, this deep integration is not always possible. This work explores two strategies to increase accuracy and decrease cost under this setting. First, we show that reordering tasks presented to the human can create a significant accuracy improvement. Further, we show that greedily choosing parameters to maximize machine accuracy is sub-optimal, and joint optimization of the combined system improves performance.