 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reasoning-Focused Legal Retrieval Benchmark
May 06, 2025As the legal community increasingly examines the use of large language models (LLMs) for various legal applications, legal AI developers have turned to retrieval-augmented LLMs ("RAG" systems) to improve system performance and robustness. An obstacle to the development of specialized RAG systems is the lack of realistic legal RAG benchmarks which capture the complexity of both legal retrieval and downstream legal question-answering. To address this, we introduce two novel legal RAG benchmarks: Bar Exam QA and Housing Statute QA. Our tasks correspond to real-world legal research tasks, and were produced through annotation processes which resemble legal research. We describe the construction of these benchmarks and the performance of existing retriever pipelines. Our results suggest that legal RAG remains a challenging application, thus motivating future research.
PIGEON: Predicting Image Geolocations
Jul 13, 2023
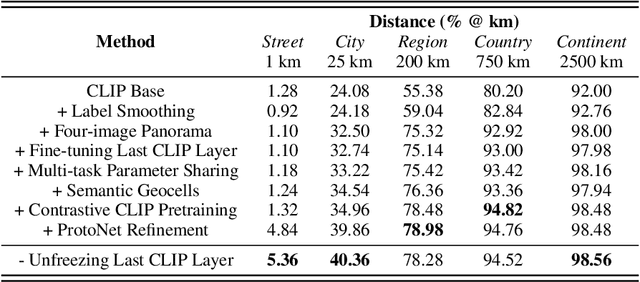
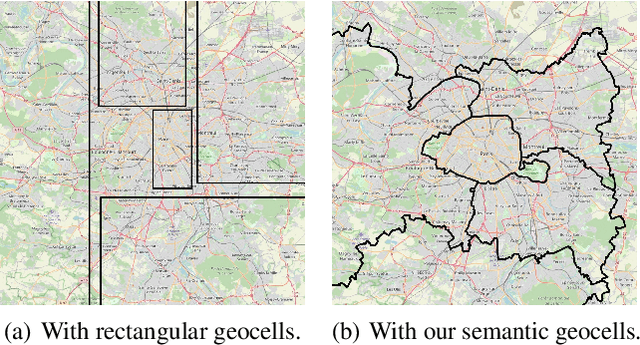
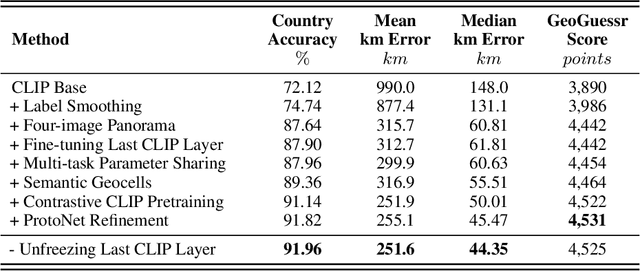
We introduce PIGEON, a multi-task end-to-end system for planet-scale image geolocalization that achieves state-of-the-art performance on both external benchmarks and in human evaluation. Our work incorporates semantic geocell creation with label smoothing, conducts pretraining of a vision transformer on images with geographic information, and refines location predictions with ProtoNets across a candidate set of geocells. The contributions of PIGEON are three-fold: first, we design a semantic geocells creation and splitting algorithm based on open-source data which can be adapted to any geospatial dataset. Second, we show the effectiveness of intra-geocell refinement and the applicability of unsupervised clustering and ProtNets to the task. Finally, we make our pre-trained CLIP transformer model, StreetCLIP, publicly available for use in adjacent domains with applications to fighting climate change and urban and rural scene understanding.
Learning Generalized Zero-Shot Learners for Open-Domain Image Geolocalization
Feb 01, 2023Image geolocalization is the challenging task of predicting the geographic coordinates of origin for a given photo. It is an unsolved problem relying on the ability to combine visual clues with general knowledge about the world to make accurate predictions across geographies. We present $\href{https://huggingface.co/geolocal/StreetCLIP}{\text{StreetCLIP}}$, a robust, publicly available foundation model not only achieving state-of-the-art performance on multiple open-domain image geolocalization benchmarks but also doing so in a zero-shot setting, outperforming supervised models trained on more than 4 million images. Our method introduces a meta-learning approach for generalized zero-shot learning by pretraining CLIP from synthetic captions, grounding CLIP in a domain of choice. We show that our method effectively transfers CLIP's generalized zero-shot capabilities to the domain of image geolocalization, improving in-domain generalized zero-shot performance without finetuning StreetCLIP on a fixed set of classes.