 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Case for "Thick Evaluations" of Cultural Representation in AI
Mar 24, 2025

Generative AI image models have been increasingly evaluated for their (in)ability to represent non-Western cultures. We argue that these evaluations operate through reductive ideals of representation, abstracted from how people define their own representation and neglecting the inherently interpretive and contextual nature of cultural representation. In contrast to these 'thin' evaluations, we introduce the idea of 'thick evaluations': a more granular, situated, and discursive measurement framework for evaluating representations of social worlds in AI images, steeped in communities' own understandings of representation. We develop this evaluation framework through workshops in South Asia, by studying the 'thick' ways in which people interpret and assign meaning to images of their own cultures. We introduce practices for thicker evaluations of representation that expand the understanding of representation underpinning AI evaluations and by co-constructing metrics with communities, bringing measurement in line with the experiences of communities on the ground.
Farsight: Fostering Responsible AI Awareness During AI Application Prototyping
Feb 23, 2024
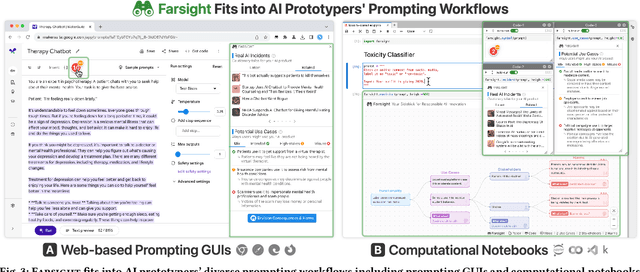
Prompt-based interfaces for Large Language Models (LLMs) have made prototyping and building AI-powered applications easier than ever before. However, identifying potential harms that may arise from AI applications remains a challenge, particularly during prompt-based prototyping. To address this, we present Farsight, a novel in situ interactive tool that helps people identify potential harms from the AI applications they are prototyping. Based on a user's prompt, Farsight highlights news articles about relevant AI incidents and allows users to explore and edit LLM-generated use cases, stakeholders, and harms. We report design insights from a co-design study with 10 AI prototypers and findings from a user study with 42 AI prototypers. After using Farsight, AI prototypers in our user study are better able to independently identify potential harms associated with a prompt and find our tool more useful and usable than existing resources. Their qualitative feedback also highlights that Farsight encourages them to focus on end-users and think beyond immediate harms. We discuss these findings and reflect on their implications for designing AI prototyping experiences that meaningfully engage with AI harms. Farsight is publicly accessible at: https://PAIR-code.github.io/farsight.
The Participatory Turn in AI Design: Theoretical Foundations and the Current State of Practice
Oct 02, 2023
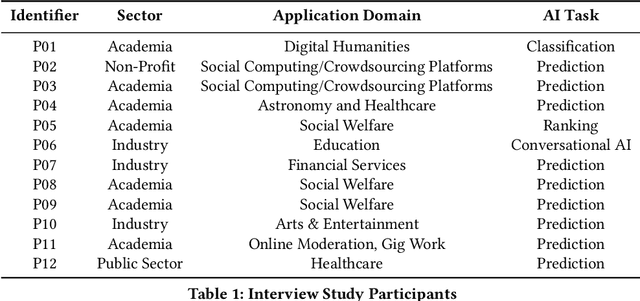
Despite the growing consensus that stakeholders affected by AI systems should participate in their design, enormous variation and implicit disagreements exist among current approaches. For researchers and practitioners who are interested in taking a participatory approach to AI design and development, it remains challenging to assess the extent to which any participatory approach grants substantive agency to stakeholders. This article thus aims to ground what we dub the "participatory turn" in AI design by synthesizing existing theoretical literature on participation and through empirical investigation and critique of its current practices. Specifically, we derive a conceptual framework through synthesis of literature across technology design, political theory, and the social sciences that researchers and practitioners can leverage to evaluate approaches to participation in AI design. Additionally, we articulate empirical findings concerning the current state of participatory practice in AI design based on an analysis of recently published research and semi-structured interviews with 12 AI researchers and practitioners. We use these empirical findings to understand the current state of participatory practice and subsequently provide guidance to better align participatory goals and methods in a way that accounts for practical constraints.
Scaling Laws Do Not Scale
Jul 05, 2023Recent work has proposed a power law relationship, referred to as ``scaling laws,'' between the performance of artificial intelligence (AI) models and aspects of those models' design (e.g., dataset size). In other words, as the size of a dataset (or model parameters, etc) increases, the performance of a given model trained on that dataset will correspondingly increase. However, while compelling in the aggregate, this scaling law relationship overlooks the ways that metrics used to measure performance may be precarious and contested, or may not correspond with how different groups of people may perceive the quality of models' output. In this paper, we argue that as the size of datasets used to train large AI models grows, the number of distinct communities (including demographic groups) whose data is included in a given dataset is likely to grow, each of whom may have different values. As a result, there is an increased risk that communities represented in a dataset may have values or preferences not captured by (or in the worst case, at odds with) the metrics used to evaluate model performance for scaling laws. We end the paper with implications for AI scaling laws -- that models may not, in fact, continue to improve as the datasets get larger -- at least not for all people or communities impacted by those models.
Investigating Practices and Opportunities for Cross-functional Collaboration around AI Fairness in Industry Practice
Jun 10, 2023
An emerging body of research indicates that ineffective cross-functional collaboration -- the interdisciplinary work done by industry practitioners across roles -- represents a major barrier to addressing issues of fairness in AI design and development. In this research, we sought to better understand practitioners' current practices and tactics to enact cross-functional collaboration for AI fairness, in order to identify opportunities to support more effective collaboration. We conducted a series of interviews and design workshops with 23 industry practitioners spanning various roles from 17 companies. We found that practitioners engaged in bridging work to overcome frictions in understanding, contextualization, and evaluation around AI fairness across roles. In addition, in organizational contexts with a lack of resources and incentives for fairness work, practitioners often piggybacked on existing requirements (e.g., for privacy assessments) and AI development norms (e.g., the use of quantitative evaluation metrics), although they worry that these tactics may be fundamentally compromised. Finally, we draw attention to the invisible labor that practitioners take on as part of this bridging and piggybacking work to enact interdisciplinary collaboration for fairness. We close by discussing opportunities for both FAccT researchers and AI practitioners to better support cross-functional collaboration for fairness in the design and development of AI systems.
Fairlearn: Assessing and Improving Fairness of AI Systems
Mar 29, 2023Fairlearn is an open source project to help practitioners assess and improve fairness of artificial intelligence (AI) systems. The associated Python library, also named fairlearn, supports evaluation of a model's output across affected populations and includes several algorithms for mitigating fairness issues. Grounded in the understanding that fairness is a sociotechnical challenge, the project integrates learning resources that aid practitioners in considering a system's broader societal context.
Human-Centered Responsible Artificial Intelligence: Current & Future Trends
Feb 16, 2023
In recent years, the CHI community has seen significant growth in research on Human-Centered Responsible Artificial Intelligence. While different research communities may use different terminology to discuss similar topics, all of this work is ultimately aimed at developing AI that benefits humanity while being grounded in human rights and ethics, and reducing the potential harms of AI. In this special interest group, we aim to bring together researchers from academia and industry interested in these topics to map current and future research trends to advance this important area of research by fostering collaboration and sharing ideas.
Assessing the Fairness of AI Systems: AI Practitioners' Processes, Challenges, and Needs for Support
Dec 10, 2021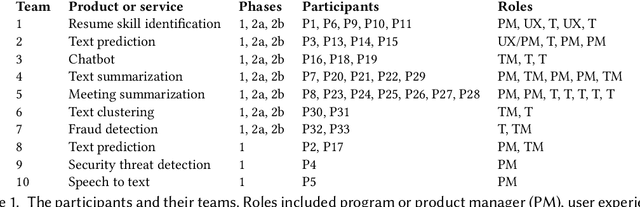
Various tools and practices have been developed to support practitioners in identifying, assessing, and mitigating fairness-related harms caused by AI systems. However, prior research has highlighted gaps between the intended design of these tools and practices and their use within particular contexts, including gaps caused by the role that organizational factors play in shaping fairness work. In this paper, we investigate these gaps for one such practice: disaggregated evaluations of AI systems, intended to uncover performance disparities between demographic groups. By conducting semi-structured interviews and structured workshops with thirty-three AI practitioners from ten teams at three technology companies, we identify practitioners' processes, challenges, and needs for support when designing disaggregated evaluations. We find that practitioners face challenges when choosing performance metrics, identifying the most relevant direct stakeholders and demographic groups on which to focus, and collecting datasets with which to conduct disaggregated evaluations. More generally, we identify impacts on fairness work stemming from a lack of engagement with direct stakeholders, business imperatives that prioritize customers over marginalized groups, and the drive to deploy AI systems at scale.
Stakeholder Participation in AI: Beyond "Add Diverse Stakeholders and Stir"
Nov 01, 2021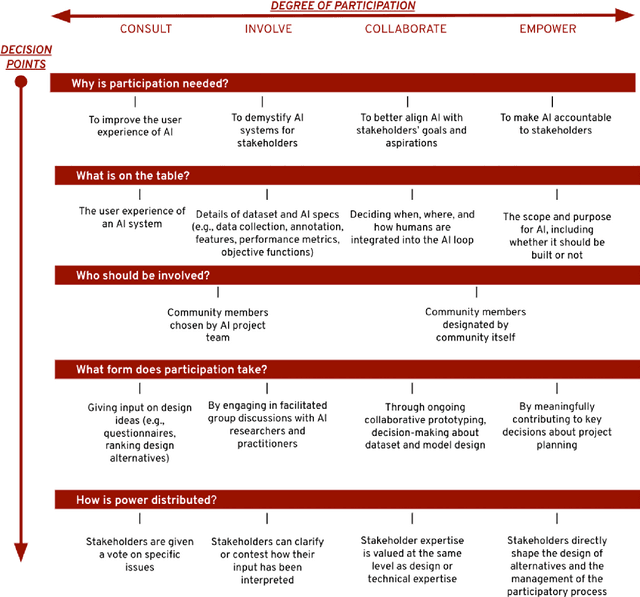
There is a growing consensus in HCI and AI research that the design of AI systems needs to engage and empower stakeholders who will be affected by AI. However, the manner in which stakeholders should participate in AI design is unclear. This workshop paper aims to ground what we dub a 'participatory turn' in AI design by synthesizing existing literature on participation and through empirical analysis of its current practices via a survey of recent published research and a dozen semi-structured interviews with AI researchers and practitioners. Based on our literature synthesis and empirical research, this paper presents a conceptual framework for analyzing participatory approaches to AI design and articulates a set of empirical findings that in ensemble detail out the contemporary landscape of participatory practice in AI design. These findings can help bootstrap a more principled discussion on how PD of AI should move forward across AI, HCI, and other research communities.
Risks of AI Foundation Models in Education
Oct 19, 2021If the authors of a recent Stanford report (Bommasani et al., 2021) on the opportunities and risks of "foundation models" are to be believed, these models represent a paradigm shift for AI and for the domains in which they will supposedly be used, including education. Although the name is new (and contested (Field, 2021)), the term describes existing types of algorithmic models that are "trained on broad data at scale" and "fine-tuned" (i.e., adapted) for particular downstream tasks, and is intended to encompass large language models such as BERT or GPT-3 and computer vision models such as CLIP. Such technologies have the potential for harm broadly speaking (e.g., Bender et al., 2021), but their use in the educational domain is particularly fraught, despite the potential benefits for learners claimed by the authors. In section 3.3 of the Stanford report, Malik et al. argue that achieving the goal of providing education for all learners requires more efficient computational approaches that can rapidly scale across educational domains and across educational contexts, for which they argue foundation models are uniquely well-suited. However, evidence suggests that not only are foundation models not likely to achieve the stated benefits for learners, but their use may also introduce new risks for harm.