 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaTeaming: Exploring How Introducing Personas Can Improve Automated AI Red-Teaming
Sep 03, 2025Recent developments in AI governance and safety research have called for red-teaming methods that can effectively surface potential risks posed by AI models. Many of these calls have emphasized how the identities and backgrounds of red-teamers can shape their red-teaming strategies, and thus the kinds of risks they are likely to uncover. While automated red-teaming approaches promise to complement human red-teaming by enabling larger-scale exploration of model behavior, current approaches do not consider the role of identity. As an initial step towards incorporating people's background and identities in automated red-teaming, we develop and evaluate a novel method, PersonaTeaming, that introduces personas in the adversarial prompt generation process to explore a wider spectrum of adversarial strategies. In particular, we first introduce a methodology for mutating prompts based on either "red-teaming expert" personas or "regular AI user" personas. We then develop a dynamic persona-generating algorithm that automatically generates various persona types adaptive to different seed prompts. In addition, we develop a set of new metrics to explicitly measure the "mutation distance" to complement existing diversity measurements of adversarial prompts. Our experiments show promising improvements (up to 144.1%) in the attack success rates of adversarial prompts through persona mutation, while maintaining prompt diversity, compared to RainbowPlus, a state-of-the-art automated red-teaming method. We discuss the strengths and limitations of different persona types and mutation methods, shedding light on future opportunities to explore complementarities between automated and human red-teaming approaches.
Surveys Considered Harmful? Reflecting on the Use of Surveys in AI Research, Development, and Governance
Jul 26, 2024
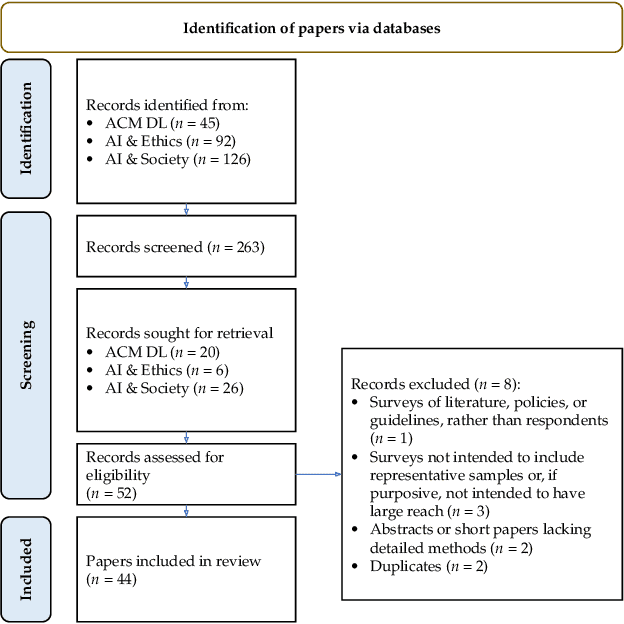
Calls for engagement with the public in Artificial Intelligence (AI) research, development, and governance are increasing, leading to the use of surveys to capture people's values, perceptions, and experiences related to AI. In this paper, we critically examine the state of human participant surveys associated with these topics. Through both a reflexive analysis of a survey pilot spanning six countries and a systematic literature review of 44 papers featuring public surveys related to AI, we explore prominent perspectives and methodological nuances associated with surveys to date. We find that public surveys on AI topics are vulnerable to specific Western knowledge, values, and assumptions in their design, including in their positioning of ethical concepts and societal values, lack sufficient critical discourse surrounding deployment strategies, and demonstrate inconsistent forms of transparency in their reporting. Based on our findings, we distill provocations and heuristic questions for our community, to recognize the limitations of surveys for meeting the goals of engagement, and to cultivate shared principles to design, deploy, and interpret surveys cautiously and responsibly.
Farsight: Fostering Responsible AI Awareness During AI Application Prototyping
Feb 23, 2024
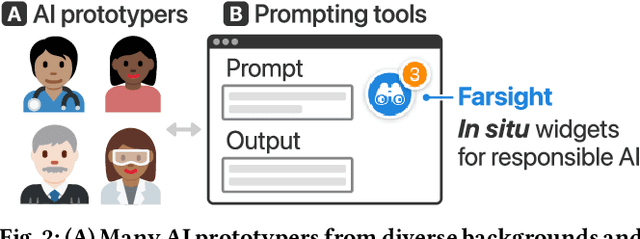
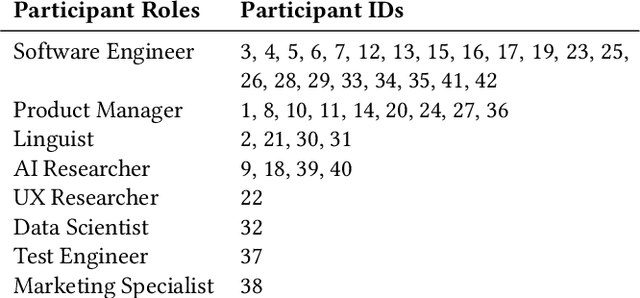
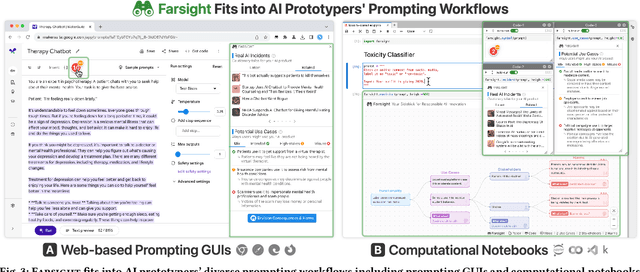
Prompt-based interfaces for Large Language Models (LLMs) have made prototyping and building AI-powered applications easier than ever before. However, identifying potential harms that may arise from AI applications remains a challenge, particularly during prompt-based prototyping. To address this, we present Farsight, a novel in situ interactive tool that helps people identify potential harms from the AI applications they are prototyping. Based on a user's prompt, Farsight highlights news articles about relevant AI incidents and allows users to explore and edit LLM-generated use cases, stakeholders, and harms. We report design insights from a co-design study with 10 AI prototypers and findings from a user study with 42 AI prototypers. After using Farsight, AI prototypers in our user study are better able to independently identify potential harms associated with a prompt and find our tool more useful and usable than existing resources. Their qualitative feedback also highlights that Farsight encourages them to focus on end-users and think beyond immediate harms. We discuss these findings and reflect on their implications for designing AI prototyping experiences that meaningfully engage with AI harms. Farsight is publicly accessible at: https://PAIR-code.github.io/farsight.
A Systematic Review and Thematic Analysis of Community-Collaborative Approaches to Computing Research
Jul 09, 2022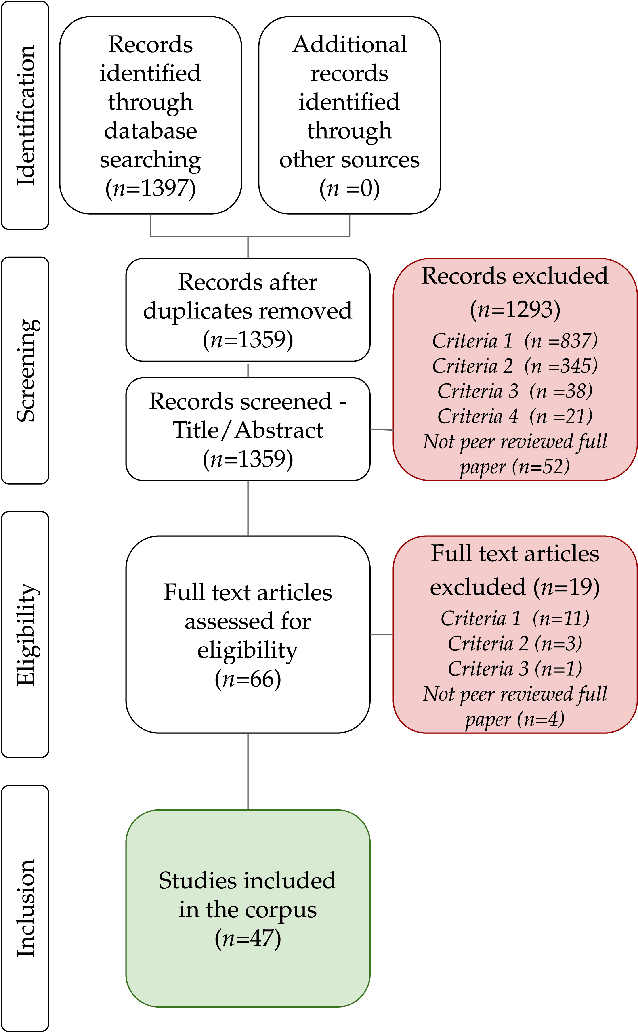
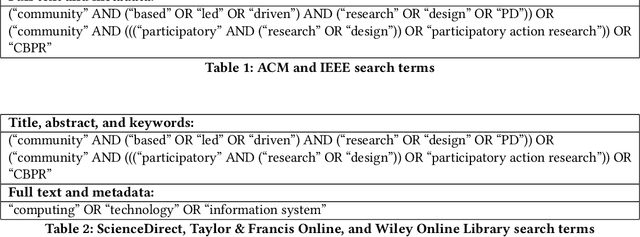
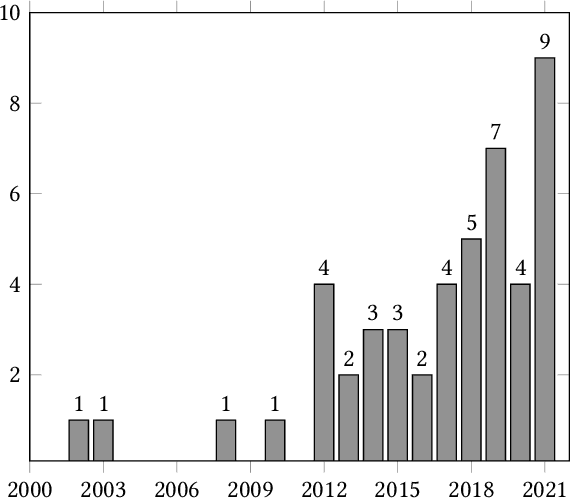

HCI researchers have been gradually shifting attention from individual users to communities when engaging in research, design, and system development. However, our field has yet to establish a cohesive, systematic understanding of the challenges, benefits, and commitments of community-collaborative approaches to research. We conducted a systematic review and thematic analysis of 47 computing research papers discussing participatory research with communities for the development of technological artifacts and systems, published over the last two decades. From this review, we identified seven themes associated with the evolution of a project: from establishing community partnerships to sustaining results. Our findings suggest that several tensions characterize these projects, many of which relate to the power and position of researchers, and the computing research environment, relative to community partners. We discuss the implications of our findings and offer methodological proposals to guide HCI, and computing research more broadly, towards practices that center communities.
Healthsheet: Development of a Transparency Artifact for Health Datasets
Feb 26, 2022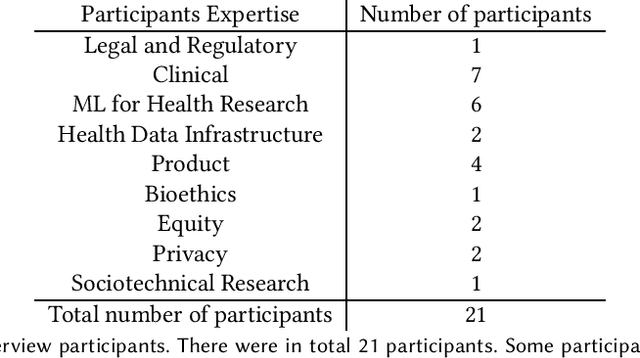
Machine learning (ML) approaches have demonstrated promising results in a wide range of healthcare applications. Data plays a crucial role in developing ML-based healthcare systems that directly affect people's lives. Many of the ethical issues surrounding the use of ML in healthcare stem from structural inequalities underlying the way we collect, use, and handle data. Developing guidelines to improve documentation practices regarding the creation, use, and maintenance of ML healthcare datasets is therefore of critical importance. In this work, we introduce Healthsheet, a contextualized adaptation of the original datasheet questionnaire ~\cite{gebru2018datasheets} for health-specific applications. Through a series of semi-structured interviews, we adapt the datasheets for healthcare data documentation. As part of the Healthsheet development process and to understand the obstacles researchers face in creating datasheets, we worked with three publicly-available healthcare datasets as our case studies, each with different types of structured data: Electronic health Records (EHR), clinical trial study data, and smartphone-based performance outcome measures. Our findings from the interviewee study and case studies show 1) that datasheets should be contextualized for healthcare, 2) that despite incentives to adopt accountability practices such as datasheets, there is a lack of consistency in the broader use of these practices 3) how the ML for health community views datasheets and particularly \textit{Healthsheets} as diagnostic tool to surface the limitations and strength of datasets and 4) the relative importance of different fields in the datasheet to healthcare concerns.