 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging 2D Masked Reconstruction for Domain Adaptation of 3D Pose Estimation
Jan 14, 2025RGB-based 3D pose estimation methods have been successful with the development of deep learning and the emergence of high-quality 3D pose datasets. However, most existing methods do not operate well for testing images whose distribution is far from that of training data. However, most existing methods do not operate well for testing images whose distribution is far from that of training data. This problem might be alleviated by involving diverse data during training, however it is non-trivial to collect such diverse data with corresponding labels (i.e. 3D pose). In this paper, we introduced an unsupervised domain adaptation framework for 3D pose estimation that utilizes the unlabeled data in addition to labeled data via masked image modeling (MIM) framework. Foreground-centric reconstruction and attention regularization are further proposed to increase the effectiveness of unlabeled data usage. Experiments are conducted on the various datasets in human and hand pose estimation tasks, especially using the cross-domain scenario. We demonstrated the effectiveness of ours by achieving the state-of-the-art accuracy on all datasets.
SDDGR: Stable Diffusion-based Deep Generative Replay for Class Incremental Object Detection
Feb 27, 2024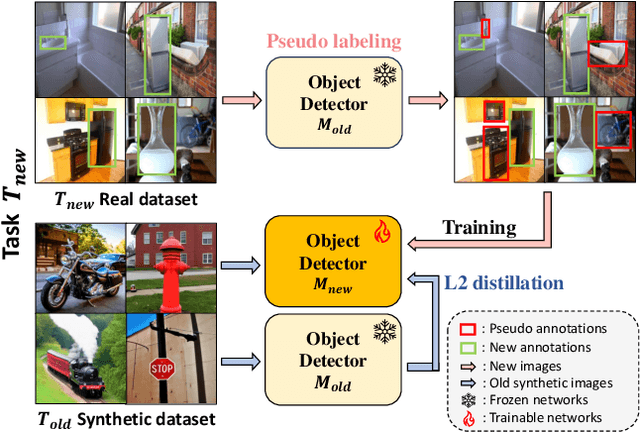
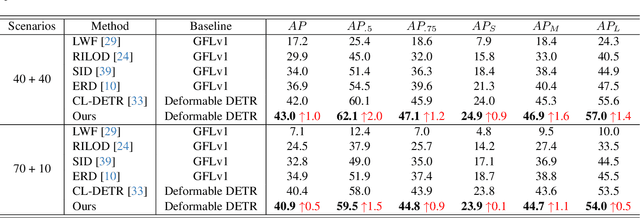
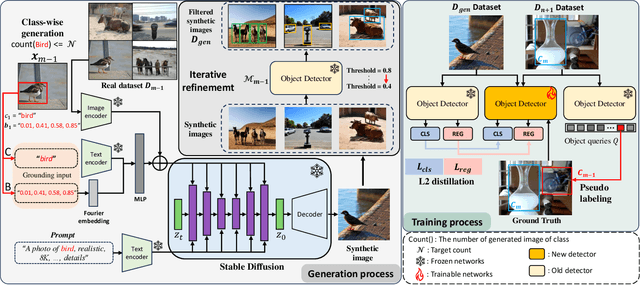
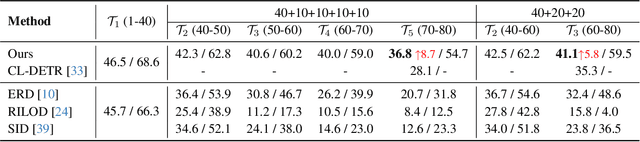
In the field of class incremental learning (CIL), genera- tive replay has become increasingly prominent as a method to mitigate the catastrophic forgetting, alongside the con- tinuous improvements in generative models. However, its application in class incremental object detection (CIOD) has been significantly limited, primarily due to the com- plexities of scenes involving multiple labels. In this paper, we propose a novel approach called stable diffusion deep generative replay (SDDGR) for CIOD. Our method utilizes a diffusion-based generative model with pre-trained text- to-diffusion networks to generate realistic and diverse syn- thetic images. SDDGR incorporates an iterative refinement strategy to produce high-quality images encompassing old classes. Additionally, we adopt an L2 knowledge distilla- tion technique to improve the retention of prior knowledge in synthetic images. Furthermore, our approach includes pseudo-labeling for old objects within new task images, pre- venting misclassification as background elements. Exten- sive experiments on the COCO 2017 dataset demonstrate that SDDGR significantly outperforms existing algorithms, achieving a new state-of-the-art in various CIOD scenarios. The source code will be made available to the public.
Transformer-based Action recognition in hand-object interacting scenarios
Oct 20, 2022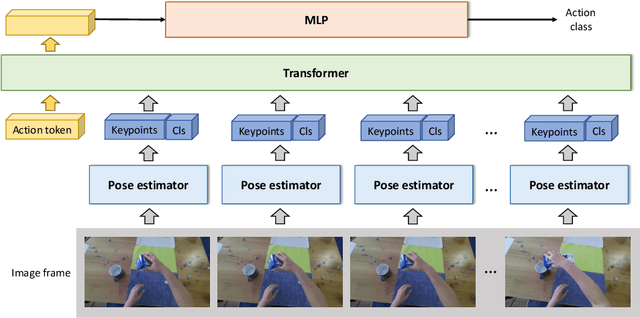



This report describes the 2nd place solution to the ECCV 2022 Human Body, Hands, and Activities (HBHA) from Egocentric and Multi-view Cameras Challenge: Action Recognition. This challenge aims to recognize hand-object interaction in an egocentric view. We propose a framework that estimates keypoints of two hands and an object with a Transformer-based keypoint estimator and recognizes actions based on the estimated keypoints. We achieved a top-1 accuracy of 87.19% on the testset.
Transformer-based Global 3D Hand Pose Estimation in Two Hands Manipulating Objects Scenarios
Oct 20, 2022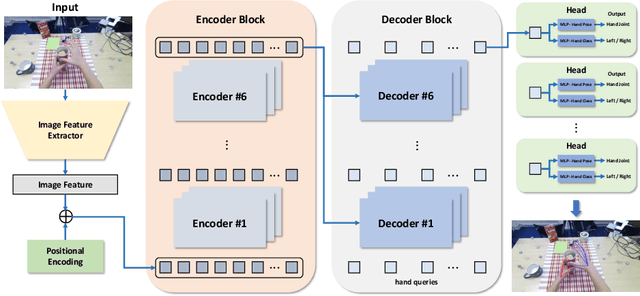
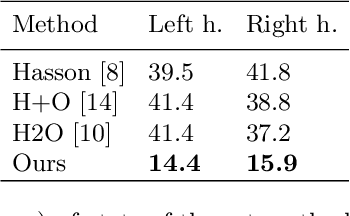
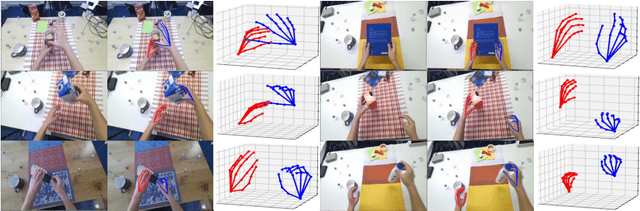

This report describes our 1st place solution to ECCV 2022 challenge on Human Body, Hands, and Activities (HBHA) from Egocentric and Multi-view Cameras (hand pose estimation). In this challenge, we aim to estimate global 3D hand poses from the input image where two hands and an object are interacting on the egocentric viewpoint. Our proposed method performs end-to-end multi-hand pose estimation via transformer architecture. In particular, our method robustly estimates hand poses in a scenario where two hands interact. Additionally, we propose an algorithm that considers hand scales to robustly estimate the absolute depth. The proposed algorithm works well even when the hand sizes are various for each person. Our method attains 14.4 mm (left) and 15.9 mm (right) errors for each hand in the test set.