 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQORT-Former: Query-optimized Real-time Transformer for Understanding Two Hands Manipulating Objects
Feb 27, 2025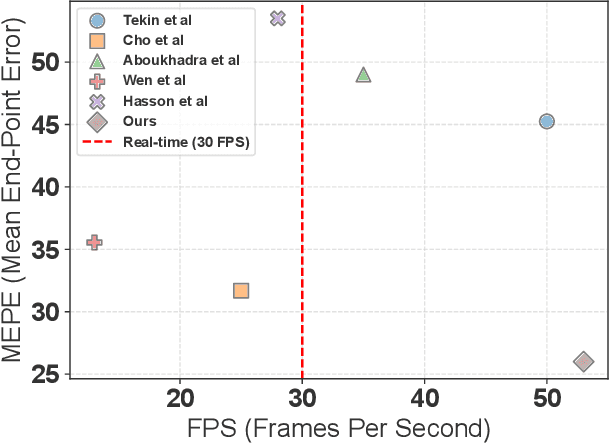
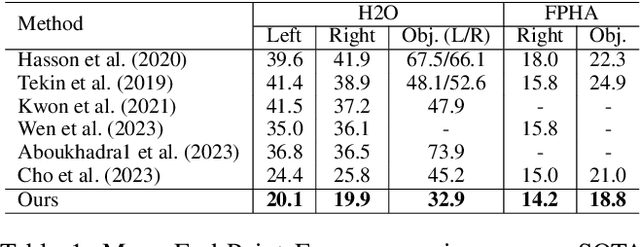
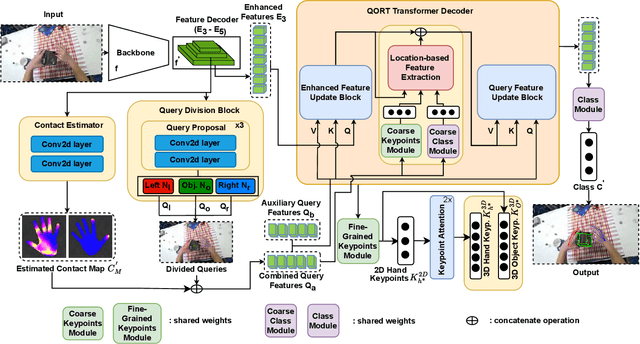
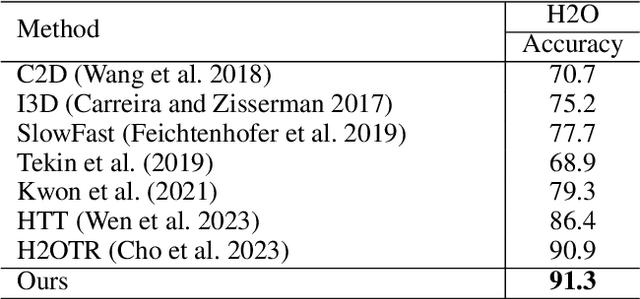
Significant advancements have been achieved in the realm of understanding poses and interactions of two hands manipulating an object. The emergence of augmented reality (AR) and virtual reality (VR) technologies has heightened the demand for real-time performance in these applications. However, current state-of-the-art models often exhibit promising results at the expense of substantial computational overhead. In this paper, we present a query-optimized real-time Transformer (QORT-Former), the first Transformer-based real-time framework for 3D pose estimation of two hands and an object. We first limit the number of queries and decoders to meet the efficiency requirement. Given limited number of queries and decoders, we propose to optimize queries which are taken as input to the Transformer decoder, to secure better accuracy: (1) we propose to divide queries into three types (a left hand query, a right hand query and an object query) and enhance query features (2) by using the contact information between hands and an object and (3) by using three-step update of enhanced image and query features with respect to one another. With proposed methods, we achieved real-time pose estimation performance using just 108 queries and 1 decoder (53.5 FPS on an RTX 3090TI GPU). Surpassing state-of-the-art results on the H2O dataset by 17.6% (left hand), 22.8% (right hand), and 27.2% (object), as well as on the FPHA dataset by 5.3% (right hand) and 10.4% (object), our method excels in accuracy. Additionally, it sets the state-of-the-art in interaction recognition, maintaining real-time efficiency with an off-the-shelf action recognition module.
GBOSE: Generalized Bandit Orthogonalized Semiparametric Estimation
Jan 20, 2023



In sequential decision-making scenarios i.e., mobile health recommendation systems revenue management contextual multi-armed bandit algorithms have garnered attention for their performance. But most of the existing algorithms are built on the assumption of a strictly parametric reward model mostly linear in nature. In this work we propose a new algorithm with a semi-parametric reward model with state-of-the-art complexity of upper bound on regret amongst existing semi-parametric algorithms. Our work expands the scope of another representative algorithm of state-of-the-art complexity with a similar reward model by proposing an algorithm built upon the same action filtering procedures but provides explicit action selection distribution for scenarios involving more than two arms at a particular time step while requiring fewer computations. We derive the said complexity of the upper bound on regret and present simulation results that affirm our methods superiority out of all prevalent semi-parametric bandit algorithms for cases involving over two arms.