 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefineVAD: Semantic-Guided Feature Recalibration for Weakly Supervised Video Anomaly Detection
Nov 17, 2025



Weakly-Supervised Video Anomaly Detection aims to identify anomalous events using only video-level labels, balancing annotation efficiency with practical applicability. However, existing methods often oversimplify the anomaly space by treating all abnormal events as a single category, overlooking the diverse semantic and temporal characteristics intrinsic to real-world anomalies. Inspired by how humans perceive anomalies, by jointly interpreting temporal motion patterns and semantic structures underlying different anomaly types, we propose RefineVAD, a novel framework that mimics this dual-process reasoning. Our framework integrates two core modules. The first, Motion-aware Temporal Attention and Recalibration (MoTAR), estimates motion salience and dynamically adjusts temporal focus via shift-based attention and global Transformer-based modeling. The second, Category-Oriented Refinement (CORE), injects soft anomaly category priors into the representation space by aligning segment-level features with learnable category prototypes through cross-attention. By jointly leveraging temporal dynamics and semantic structure, explicitly models both "how" motion evolves and "what" semantic category it resembles. Extensive experiments on WVAD benchmark validate the effectiveness of RefineVAD and highlight the importance of integrating semantic context to guide feature refinement toward anomaly-relevant patterns.
EO-VLM: VLM-Guided Energy Overload Attacks on Vision Models
Apr 11, 2025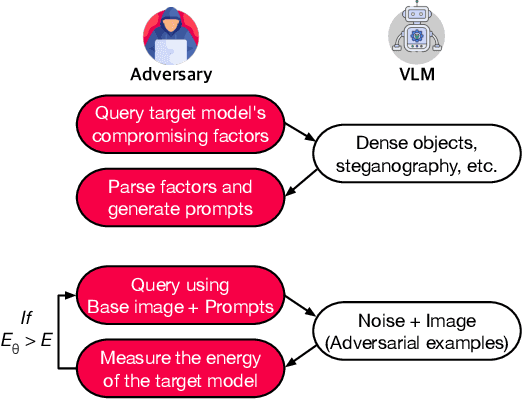
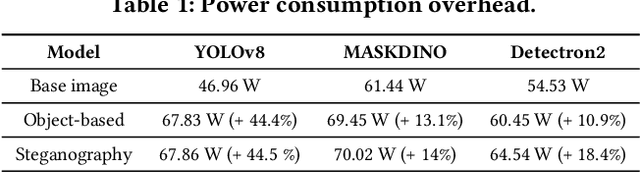

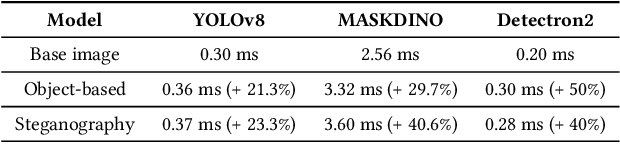
Vision models are increasingly deployed in critical applications such as autonomous driving and CCTV monitoring, yet they remain susceptible to resource-consuming attacks. In this paper, we introduce a novel energy-overloading attack that leverages vision language model (VLM) prompts to generate adversarial images targeting vision models. These images, though imperceptible to the human eye, significantly increase GPU energy consumption across various vision models, threatening the availability of these systems. Our framework, EO-VLM (Energy Overload via VLM), is model-agnostic, meaning it is not limited by the architecture or type of the target vision model. By exploiting the lack of safety filters in VLMs like DALL-E 3, we create adversarial noise images without requiring prior knowledge or internal structure of the target vision models. Our experiments demonstrate up to a 50% increase in energy consumption, revealing a critical vulnerability in current vision models.
VPOcc: Exploiting Vanishing Point for Monocular 3D Semantic Occupancy Prediction
Aug 07, 2024



Monocular 3D semantic occupancy prediction is becoming important in robot vision due to the compactness of using a single RGB camera. However, existing methods often do not adequately account for camera perspective geometry, resulting in information imbalance along the depth range of the image. To address this issue, we propose a vanishing point (VP) guided monocular 3D semantic occupancy prediction framework named VPOcc. Our framework consists of three novel modules utilizing VP. First, in the VPZoomer module, we initially utilize VP in feature extraction to achieve information balanced feature extraction across the scene by generating a zoom-in image based on VP. Second, we perform perspective geometry-aware feature aggregation by sampling points towards VP using a VP-guided cross-attention (VPCA) module. Finally, we create an information-balanced feature volume by effectively fusing original and zoom-in voxel feature volumes with a balanced feature volume fusion (BVFV) module. Experiments demonstrate that our method achieves state-of-the-art performance for both IoU and mIoU on SemanticKITTI and SSCBench-KITTI360. These results are obtained by effectively addressing the information imbalance in images through the utilization of VP. Our code will be available at www.github.com/anonymous.