 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Expert Cognitive Models to Social Robots via Agentic Concept Bottleneck Models
Aug 06, 2025Successful group meetings, such as those implemented in group behavioral-change programs, work meetings, and other social contexts, must promote individual goal setting and execution while strengthening the social relationships within the group. Consequently, an ideal facilitator must be sensitive to the subtle dynamics of disengagement, difficulties with individual goal setting and execution, and interpersonal difficulties that signal a need for intervention. The challenges and cognitive load experienced by facilitators create a critical gap for an embodied technology that can interpret social exchanges while remaining aware of the needs of the individuals in the group and providing transparent recommendations that go beyond powerful but "black box" foundation models (FMs) that identify social cues. We address this important demand with a social robot co-facilitator that analyzes multimodal meeting data and provides discreet cues to the facilitator. The robot's reasoning is powered by an agentic concept bottleneck model (CBM), which makes decisions based on human-interpretable concepts like participant engagement and sentiments, ensuring transparency and trustworthiness. Our core contribution is a transfer learning framework that distills the broad social understanding of an FM into our specialized and transparent CBM. This concept-driven system significantly outperforms direct zero-shot FMs in predicting the need for intervention and enables real-time human correction of its reasoning. Critically, we demonstrate robust knowledge transfer: the model generalizes across different groups and successfully transfers the expertise of senior human facilitators to improve the performance of novices. By transferring an expert's cognitive model into an interpretable robotic partner, our work provides a powerful blueprint for augmenting human capabilities in complex social domains.
EO-VLM: VLM-Guided Energy Overload Attacks on Vision Models
Apr 11, 2025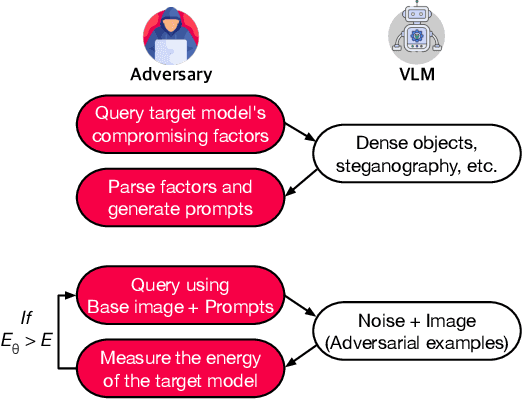
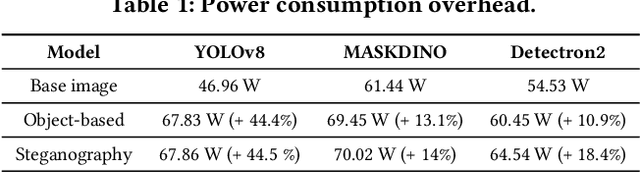

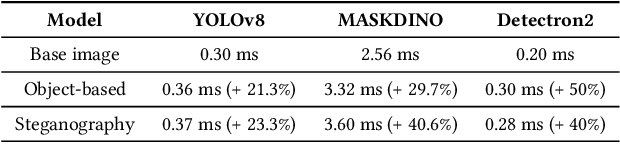
Vision models are increasingly deployed in critical applications such as autonomous driving and CCTV monitoring, yet they remain susceptible to resource-consuming attacks. In this paper, we introduce a novel energy-overloading attack that leverages vision language model (VLM) prompts to generate adversarial images targeting vision models. These images, though imperceptible to the human eye, significantly increase GPU energy consumption across various vision models, threatening the availability of these systems. Our framework, EO-VLM (Energy Overload via VLM), is model-agnostic, meaning it is not limited by the architecture or type of the target vision model. By exploiting the lack of safety filters in VLMs like DALL-E 3, we create adversarial noise images without requiring prior knowledge or internal structure of the target vision models. Our experiments demonstrate up to a 50% increase in energy consumption, revealing a critical vulnerability in current vision models.