 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPINET: A Fully-Convolutional Neural Network Using Epipolar Geometry for Depth from Light Field Images
Apr 06, 2018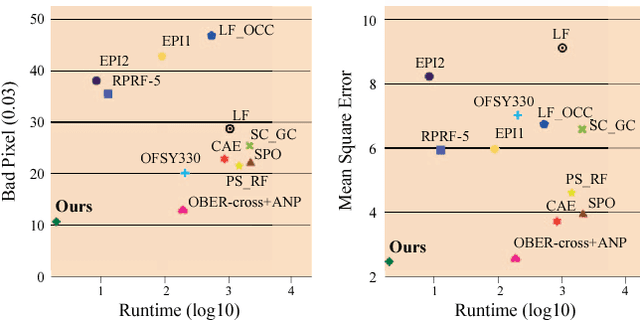



Light field cameras capture both the spatial and the angular properties of light rays in space. Due to its property, one can compute the depth from light fields in uncontrolled lighting environments, which is a big advantage over active sensing devices. Depth computed from light fields can be used for many applications including 3D modelling and refocusing. However, light field images from hand-held cameras have very narrow baselines with noise, making the depth estimation difficult. any approaches have been proposed to overcome these limitations for the light field depth estimation, but there is a clear trade-off between the accuracy and the speed in these methods. In this paper, we introduce a fast and accurate light field depth estimation method based on a fully-convolutional neural network. Our network is designed by considering the light field geometry and we also overcome the lack of training data by proposing light field specific data augmentation methods. We achieved the top rank in the HCI 4D Light Field Benchmark on most metrics, and we also demonstrate the effectiveness of the proposed method on real-world light-field images.
Disjoint Multi-task Learning between Heterogeneous Human-centric Tasks
Feb 14, 2018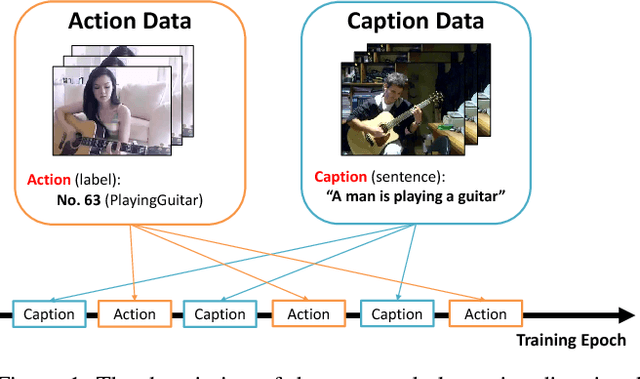

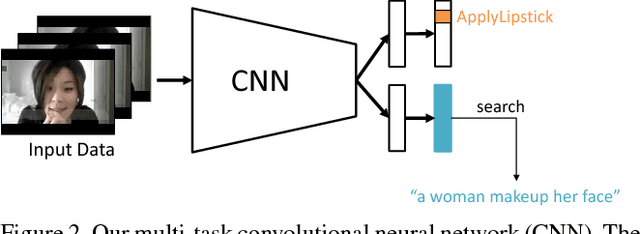

Human behavior understanding is arguably one of the most important mid-level components in artificial intelligence. In order to efficiently make use of data, multi-task learning has been studied in diverse computer vision tasks including human behavior understanding. However, multi-task learning relies on task specific datasets and constructing such datasets can be cumbersome. It requires huge amounts of data, labeling efforts, statistical consideration etc. In this paper, we leverage existing single-task datasets for human action classification and captioning data for efficient human behavior learning. Since the data in each dataset has respective heterogeneous annotations, traditional multi-task learning is not effective in this scenario. To this end, we propose a novel alternating directional optimization method to efficiently learn from the heterogeneous data. We demonstrate the effectiveness of our model and show performance improvements on both classification and sentence retrieval tasks in comparison to the models trained on each of the single-task datasets.
Fine-scale Surface Normal Estimation using a Single NIR Image
Mar 24, 2016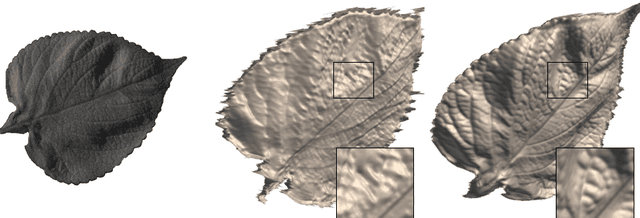
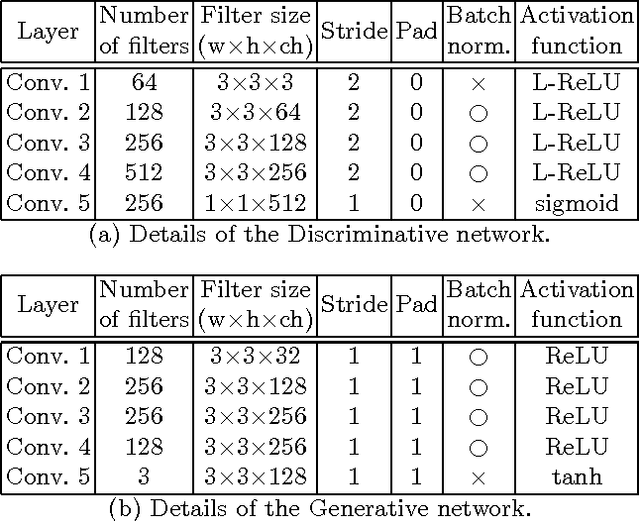
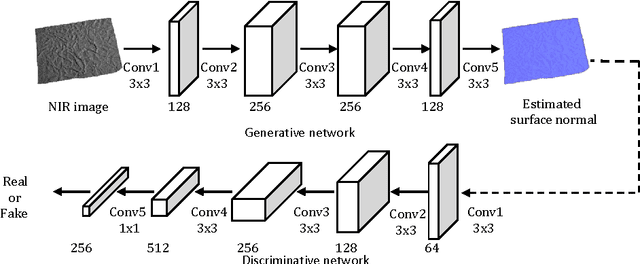
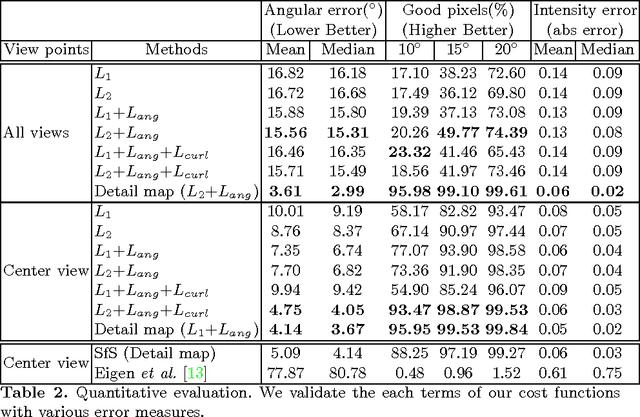
We present surface normal estimation using a single near infrared (NIR) image. We are focusing on fine-scale surface geometry captured with an uncalibrated light source. To tackle this ill-posed problem, we adopt a generative adversarial network which is effective in recovering a sharp output, which is also essential for fine-scale surface normal estimation. We incorporate angular error and integrability constraint into the objective function of the network to make estimated normals physically meaningful. We train and validate our network on a recent NIR dataset, and also evaluate the generality of our trained model by using new external datasets which are captured with a different camera under different environment.