 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Image Captioning by Adversarially Propagating Labeled Data
Jan 26, 2023



We present a novel data-efficient semi-supervised framework to improve the generalization of image captioning models. Constructing a large-scale labeled image captioning dataset is an expensive task in terms of labor, time, and cost. In contrast to manually annotating all the training samples, separately collecting uni-modal datasets is immensely easier, e.g., a large-scale image dataset and a sentence dataset. We leverage such massive unpaired image and caption data upon standard paired data by learning to associate them. To this end, our proposed semi-supervised learning method assigns pseudo-labels to unpaired samples in an adversarial learning fashion, where the joint distribution of image and caption is learned. Our method trains a captioner to learn from a paired data and to progressively associate unpaired data. This approach shows noticeable performance improvement even in challenging scenarios including out-of-task data (i.e., relational captioning, where the target task is different from the unpaired data) and web-crawled data. We also show that our proposed method is theoretically well-motivated and has a favorable global optimal property. Our extensive and comprehensive empirical results both on (1) image-based and (2) dense region-based captioning datasets followed by comprehensive analysis on the scarcely-paired COCO dataset demonstrate the consistent effectiveness of our semisupervised learning method with unpaired data compared to competing methods.
Single-Modal Entropy based Active Learning for Visual Question Answering
Nov 18, 2021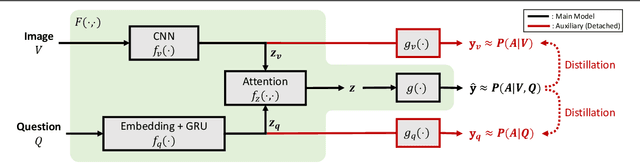
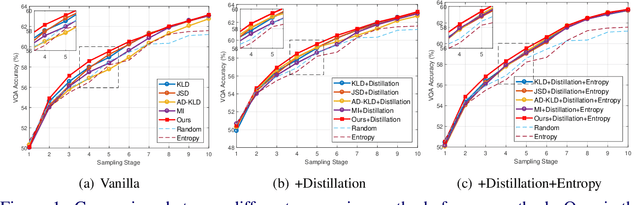
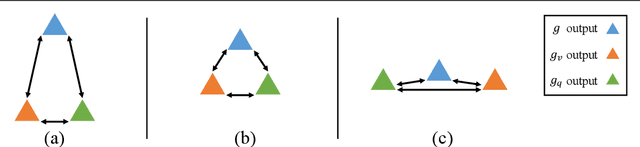
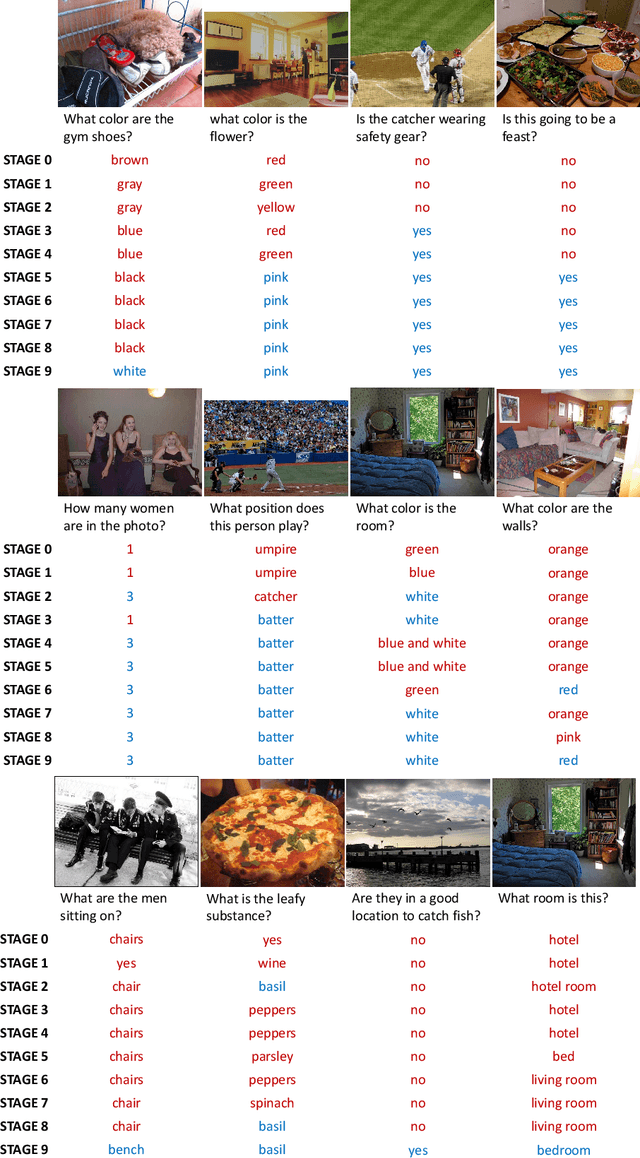
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
Self-Supervised Real-time Video Stabilization
Nov 10, 2021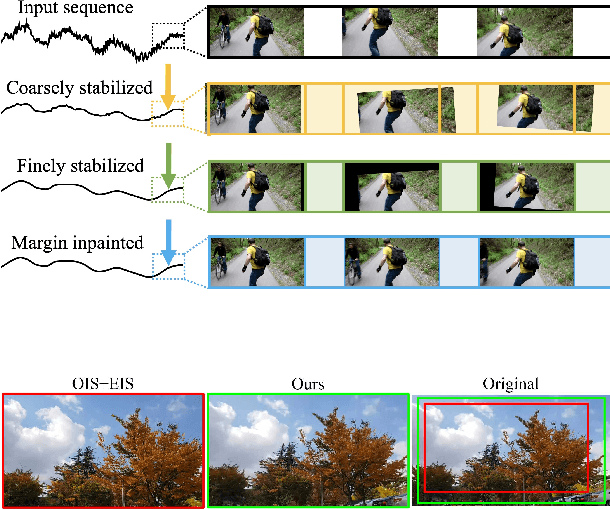
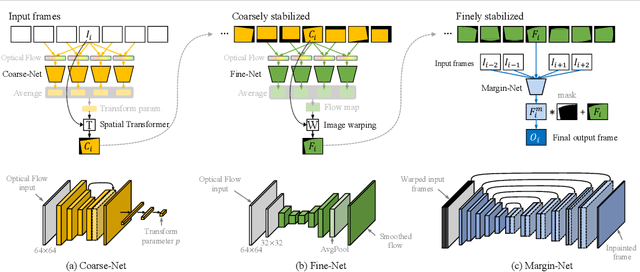

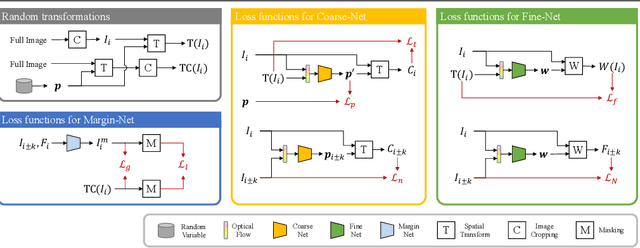
Videos are a popular media form, where online video streaming has recently gathered much popularity. In this work, we propose a novel method of real-time video stabilization - transforming a shaky video to a stabilized video as if it were stabilized via gimbals in real-time. Our framework is trainable in a self-supervised manner, which does not require data captured with special hardware setups (i.e., two cameras on a stereo rig or additional motion sensors). Our framework consists of a transformation estimator between given frames for global stability adjustments, followed by scene parallax reduction module via spatially smoothed optical flow for further stability. Then, a margin inpainting module fills in the missing margin regions created during stabilization to reduce the amount of post-cropping. These sequential steps reduce distortion and margin cropping to a minimum while enhancing stability. Hence, our approach outperforms state-of-the-art real-time video stabilization methods as well as offline methods that require camera trajectory optimization. Our method procedure takes approximately 24.3 ms yielding 41 fps regardless of resolution (e.g., 480p or 1080p).
ACP++: Action Co-occurrence Priors for Human-Object Interaction Detection
Sep 09, 2021
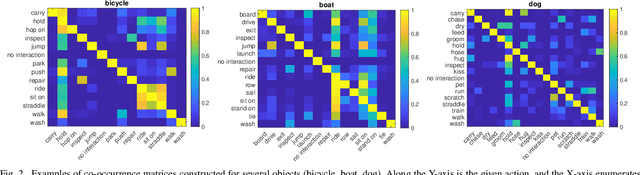
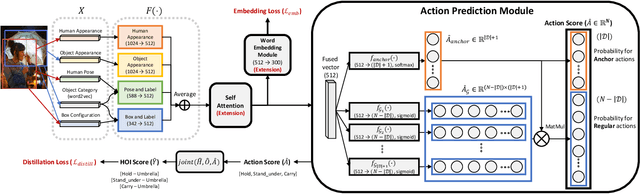

A common problem in the task of human-object interaction (HOI) detection is that numerous HOI classes have only a small number of labeled examples, resulting in training sets with a long-tailed distribution. The lack of positive labels can lead to low classification accuracy for these classes. Towards addressing this issue, we observe that there exist natural correlations and anti-correlations among human-object interactions. In this paper, we model the correlations as action co-occurrence matrices and present techniques to learn these priors and leverage them for more effective training, especially on rare classes. The efficacy of our approach is demonstrated experimentally, where the performance of our approach consistently improves over the state-of-the-art methods on both of the two leading HOI detection benchmark datasets, HICO-Det and V-COCO.
Dealing with Missing Modalities in the Visual Question Answer-Difference Prediction Task through Knowledge Distillation
Apr 13, 2021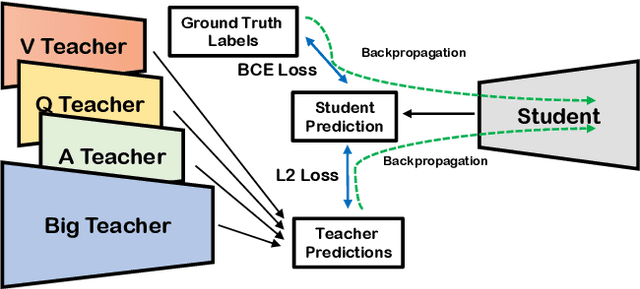

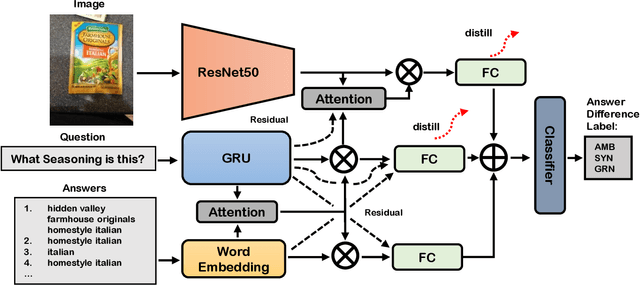
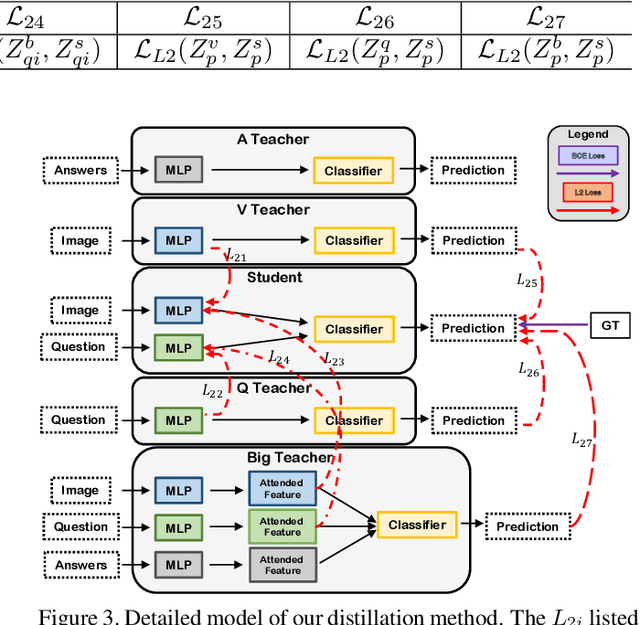
In this work, we address the issues of missing modalities that have arisen from the Visual Question Answer-Difference prediction task and find a novel method to solve the task at hand. We address the missing modality-the ground truth answers-that are not present at test time and use a privileged knowledge distillation scheme to deal with the issue of the missing modality. In order to efficiently do so, we first introduce a model, the "Big" Teacher, that takes the image/question/answer triplet as its input and outperforms the baseline, then use a combination of models to distill knowledge to a target network (student) that only takes the image/question pair as its inputs. We experiment our models on the VizWiz and VQA-V2 Answer Difference datasets and show through extensive experimentation and ablation the performances of our method and a diverse possibility for future research.
Dense Relational Image Captioning via Multi-task Triple-Stream Networks
Oct 12, 2020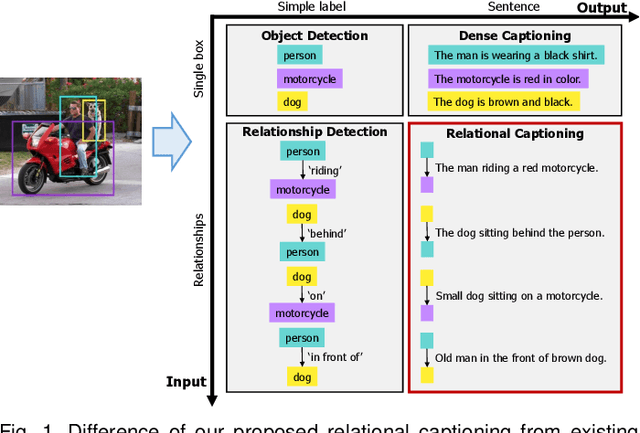
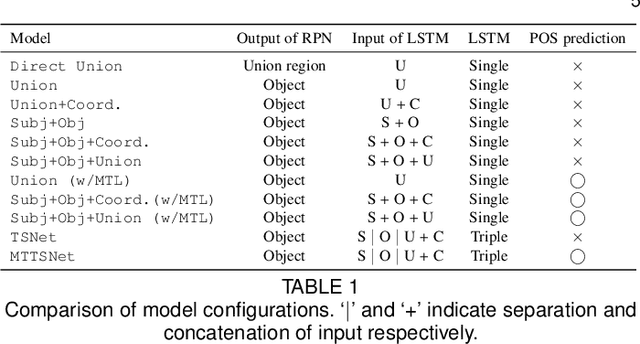
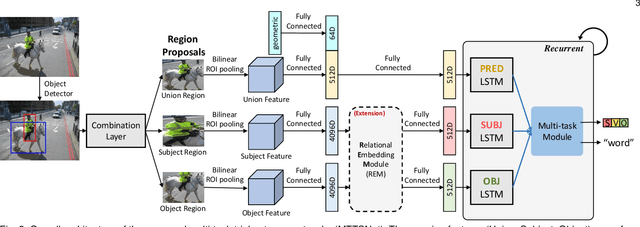

We introduce dense relational captioning, a novel image captioning task which aims to generate multiple captions with respect to relational information between objects in a visual scene. Relational captioning provides explicit descriptions of each relationship between object combinations. This framework is advantageous in both diversity and amount of information, leading to a comprehensive image understanding based on relationships, e.g., relational proposal generation. For relational understanding between objects, the part-of-speech (POS, i.e., subject-object-predicate categories) can be a valuable prior information to guide the causal sequence of words in a caption. We enforce our framework to not only learn to generate captions but also predict the POS of each word. To this end, we propose the multi-task triple-stream network (MTTSNet) which consists of three recurrent units responsible for each POS which is trained by jointly predicting the correct captions and POS for each word. In addition, we found that the performance of MTTSNet can be improved by modulating the object embeddings with an explicit relational module. We demonstrate that our proposed model can generate more diverse and richer captions, via extensive experimental analysis on large scale datasets and several metrics. We additionally extend analysis to an ablation study, applications on holistic image captioning, scene graph generation, and retrieval tasks.
Detecting Human-Object Interactions with Action Co-occurrence Priors
Jul 27, 2020
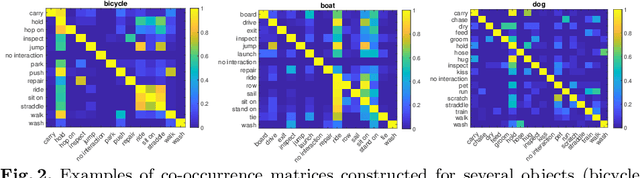
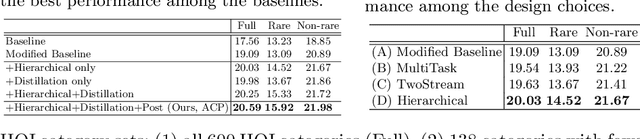

A common problem in human-object interaction (HOI) detection task is that numerous HOI classes have only a small number of labeled examples, resulting in training sets with a long-tailed distribution. The lack of positive labels can lead to low classification accuracy for these classes. Towards addressing this issue, we observe that there exist natural correlations and anti-correlations among human-object interactions. In this paper, we model the correlations as action co-occurrence matrices and present techniques to learn these priors and leverage them for more effective training, especially in rare classes. The utility of our approach is demonstrated experimentally, where the performance of our approach exceeds the state-of-the-art methods on both of the two leading HOI detection benchmark datasets, HICO-Det and V-COCO.
Deep Iterative Frame Interpolation for Full-frame Video Stabilization
Sep 05, 2019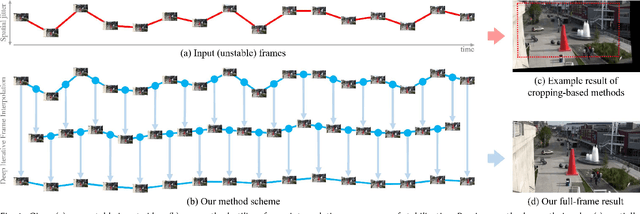

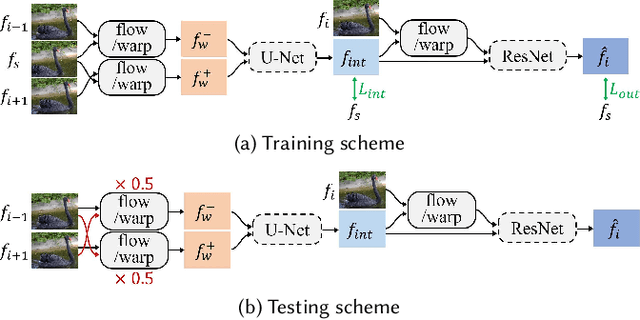

Video stabilization is a fundamental and important technique for higher quality videos. Prior works have extensively explored video stabilization, but most of them involve cropping of the frame boundaries and introduce moderate levels of distortion. We present a novel deep approach to video stabilization which can generate video frames without cropping and low distortion. The proposed framework utilizes frame interpolation techniques to generate in between frames, leading to reduced inter-frame jitter. Once applied in an iterative fashion, the stabilization effect becomes stronger. A major advantage is that our framework is end-to-end trainable in an unsupervised manner. In addition, our method is able to run in near real-time (15 fps). To the best of our knowledge, this is the first work to propose an unsupervised deep approach to full-frame video stabilization. We show the advantages of our method through quantitative and qualitative evaluations comparing to the state-of-the-art methods.
Image Captioning with Very Scarce Supervised Data: Adversarial Semi-Supervised Learning Approach
Sep 05, 2019
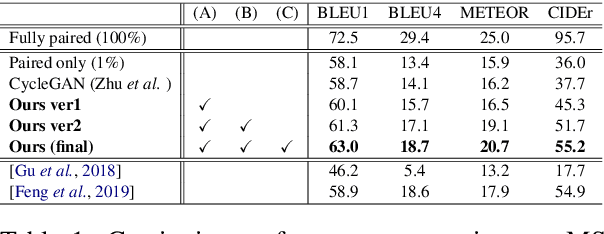


Constructing an organized dataset comprised of a large number of images and several captions for each image is a laborious task, which requires vast human effort. On the other hand, collecting a large number of images and sentences separately may be immensely easier. In this paper, we develop a novel data-efficient semi-supervised framework for training an image captioning model. We leverage massive unpaired image and caption data by learning to associate them. To this end, our proposed semi-supervised learning method assigns pseudo-labels to unpaired samples via Generative Adversarial Networks to learn the joint distribution of image and caption. To evaluate, we construct scarcely-paired COCO dataset, a modified version of MS COCO caption dataset. The empirical results show the effectiveness of our method compared to several strong baselines, especially when the amount of the paired samples are scarce.
Dense Relational Captioning: Triple-Stream Networks for Relationship-Based Captioning
Apr 01, 2019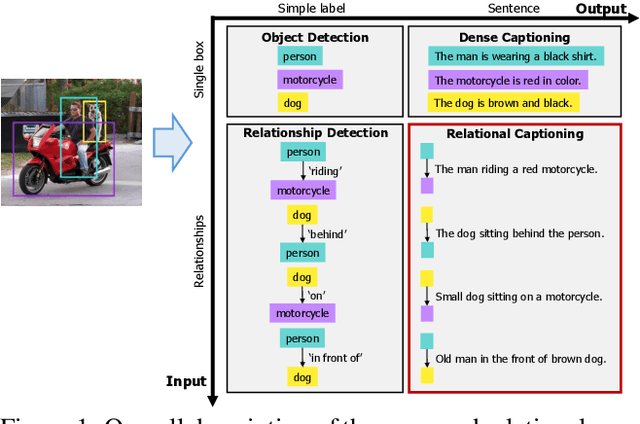
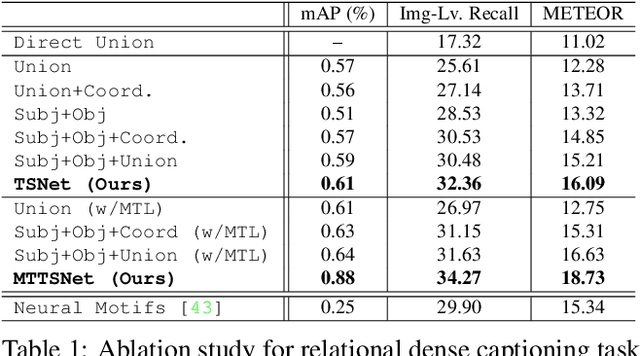
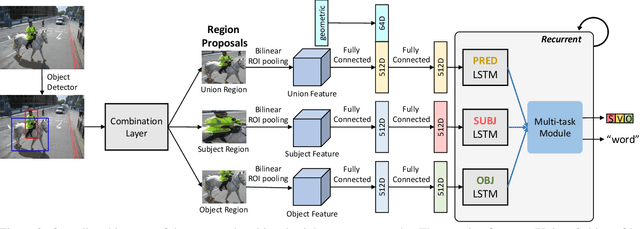
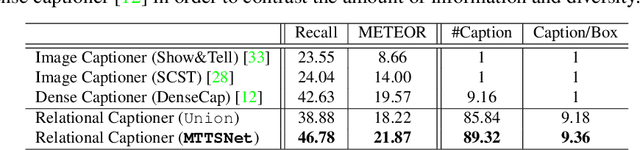
Our goal in this work is to train an image captioning model that generates more dense and informative captions. We introduce "relational captioning," a novel image captioning task which aims to generate multiple captions with respect to relational information between objects in an image. Relational captioning is a framework that is advantageous in both diversity and amount of information, leading to image understanding based on relationships. Part-of speech (POS, i.e. subject-object-predicate categories) tags can be assigned to every English word. We leverage the POS as a prior to guide the correct sequence of words in a caption. To this end, we propose a multi-task triple-stream network (MTTSNet) which consists of three recurrent units for the respective POS and jointly performs POS prediction and captioning. We demonstrate more diverse and richer representations generated by the proposed model against several baselines and competing methods.