 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Modal Entropy based Active Learning for Visual Question Answering
Nov 18, 2021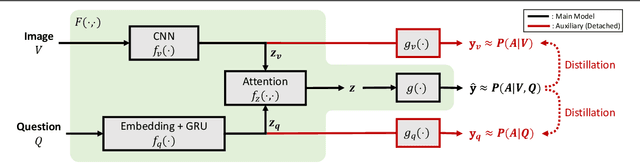
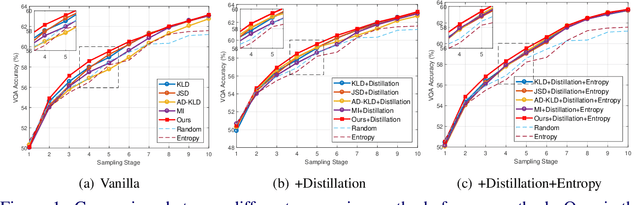
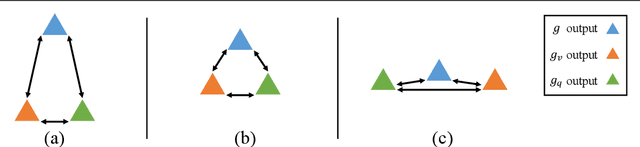
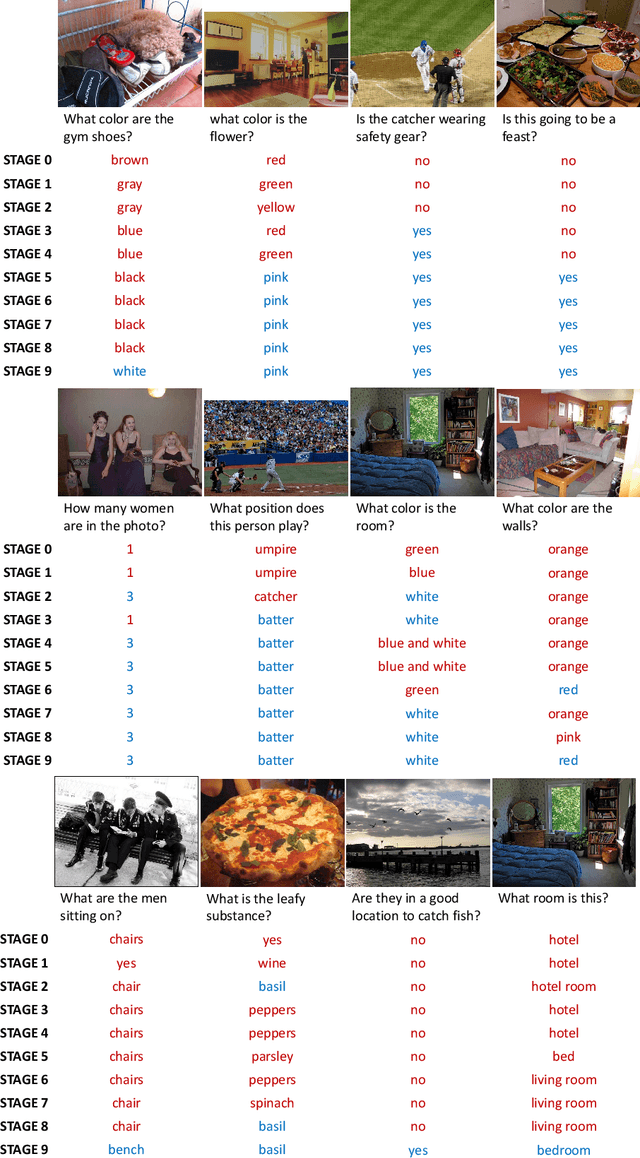
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.
MCDAL: Maximum Classifier Discrepancy for Active Learning
Jul 23, 2021
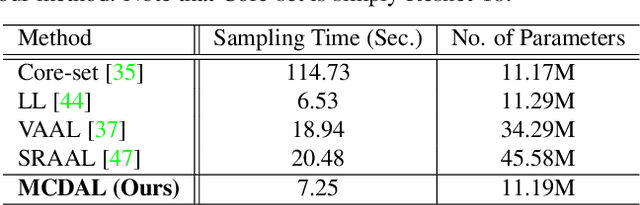
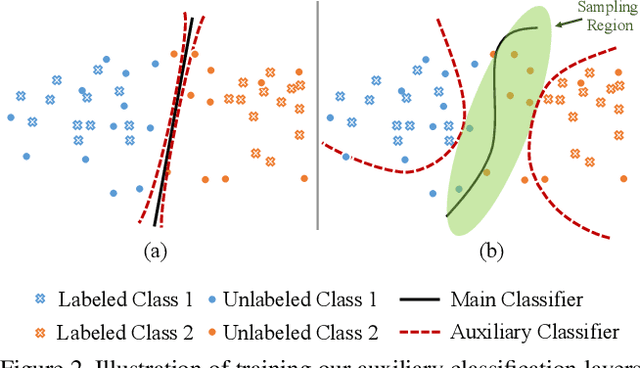

Recent state-of-the-art active learning methods have mostly leveraged Generative Adversarial Networks (GAN) for sample acquisition; however, GAN is usually known to suffer from instability and sensitivity to hyper-parameters. In contrast to these methods, we propose in this paper a novel active learning framework that we call Maximum Classifier Discrepancy for Active Learning (MCDAL) which takes the prediction discrepancies between multiple classifiers. In particular, we utilize two auxiliary classification layers that learn tighter decision boundaries by maximizing the discrepancies among them. Intuitively, the discrepancies in the auxiliary classification layers' predictions indicate the uncertainty in the prediction. In this regard, we propose a novel method to leverage the classifier discrepancies for the acquisition function for active learning. We also provide an interpretation of our idea in relation to existing GAN based active learning methods and domain adaptation frameworks. Moreover, we empirically demonstrate the utility of our approach where the performance of our approach exceeds the state-of-the-art methods on several image classification and semantic segmentation datasets in active learning setups.
Dealing with Missing Modalities in the Visual Question Answer-Difference Prediction Task through Knowledge Distillation
Apr 13, 2021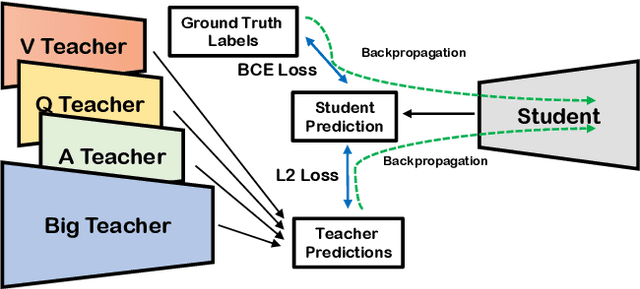

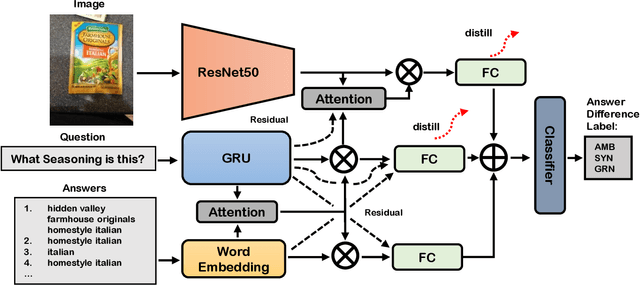
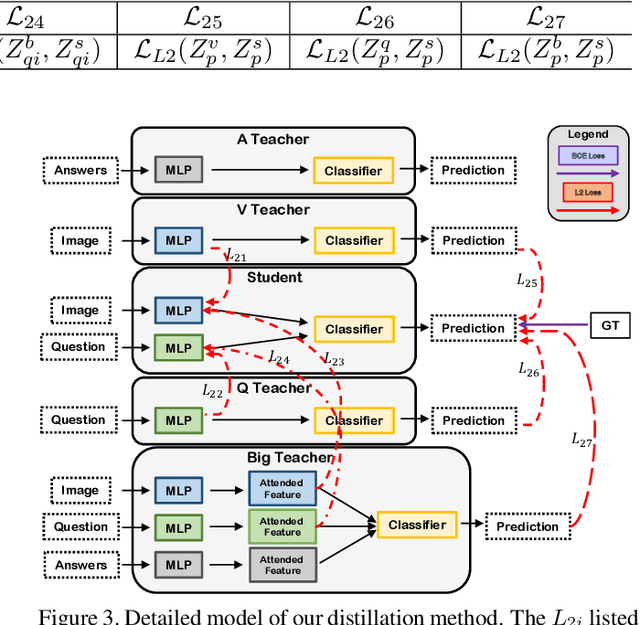
In this work, we address the issues of missing modalities that have arisen from the Visual Question Answer-Difference prediction task and find a novel method to solve the task at hand. We address the missing modality-the ground truth answers-that are not present at test time and use a privileged knowledge distillation scheme to deal with the issue of the missing modality. In order to efficiently do so, we first introduce a model, the "Big" Teacher, that takes the image/question/answer triplet as its input and outperforms the baseline, then use a combination of models to distill knowledge to a target network (student) that only takes the image/question pair as its inputs. We experiment our models on the VizWiz and VQA-V2 Answer Difference datasets and show through extensive experimentation and ablation the performances of our method and a diverse possibility for future research.
Hide-and-Tell: Learning to Bridge Photo Streams for Visual Storytelling
Feb 03, 2020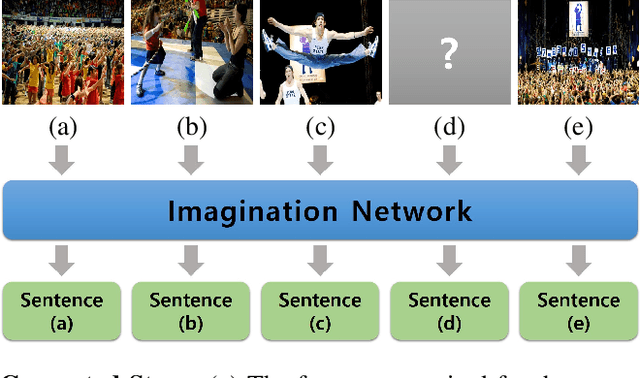
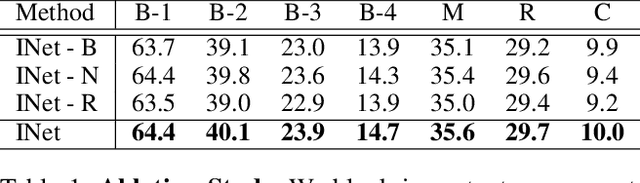
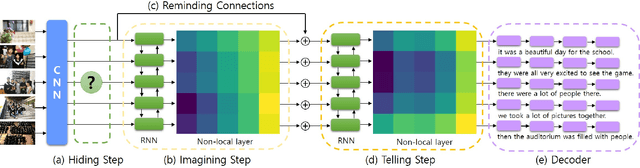
Visual storytelling is a task of creating a short story based on photo streams. Unlike existing visual captioning, storytelling aims to contain not only factual descriptions, but also human-like narration and semantics. However, the VIST dataset consists only of a small, fixed number of photos per story. Therefore, the main challenge of visual storytelling is to fill in the visual gap between photos with narrative and imaginative story. In this paper, we propose to explicitly learn to imagine a storyline that bridges the visual gap. During training, one or more photos is randomly omitted from the input stack, and we train the network to produce a full plausible story even with missing photo(s). Furthermore, we propose for visual storytelling a hide-and-tell model, which is designed to learn non-local relations across the photo streams and to refine and improve conventional RNN-based models. In experiments, we show that our scheme of hide-and-tell, and the network design are indeed effective at storytelling, and that our model outperforms previous state-of-the-art methods in automatic metrics. Finally, we qualitatively show the learned ability to interpolate storyline over visual gaps.
Discriminative Feature Learning for Unsupervised Video Summarization
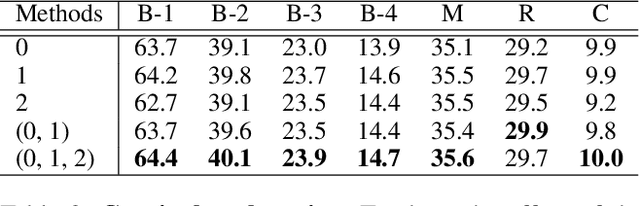
Nov 24, 2018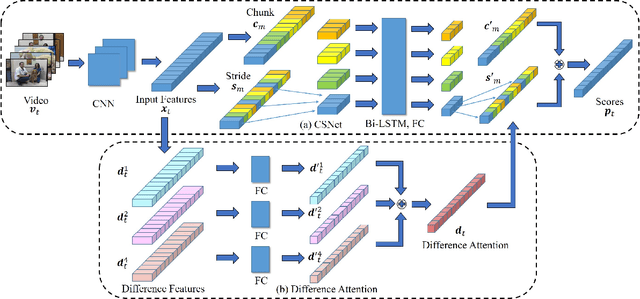



In this paper, we address the problem of unsupervised video summarization that automatically extracts key-shots from an input video. Specifically, we tackle two critical issues based on our empirical observations: (i) Ineffective feature learning due to flat distributions of output importance scores for each frame, and (ii) training difficulty when dealing with long-length video inputs. To alleviate the first problem, we propose a simple yet effective regularization loss term called variance loss. The proposed variance loss allows a network to predict output scores for each frame with high discrepancy which enables effective feature learning and significantly improves model performance. For the second problem, we design a novel two-stream network named Chunk and Stride Network (CSNet) that utilizes local (chunk) and global (stride) temporal view on the video features. Our CSNet gives better summarization results for long-length videos compared to the existing methods. In addition, we introduce an attention mechanism to handle the dynamic information in videos. We demonstrate the effectiveness of the proposed methods by conducting extensive ablation studies and show that our final model achieves new state-of-the-art results on two benchmark datasets.