 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Method for Incremental Learning on Classification and Generation
Oct 29, 2020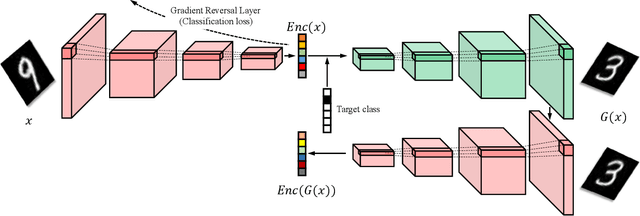

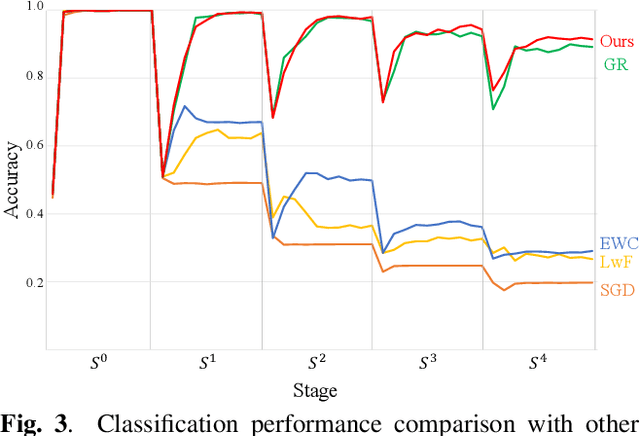
Although well-trained deep neural networks have shown remarkable performance on numerous tasks, they rapidly forget what they have learned as soon as they begin to learn with additional data with the previous data stop being provided. In this paper, we introduce a novel algorithm, Incremental Class Learning with Attribute Sharing (ICLAS), for incremental class learning with deep neural networks. As one of its component, we also introduce a generative model, incGAN, which can generate images with increased variety compared with the training data. Under challenging environment of data deficiency, ICLAS incrementally trains classification and the generation networks. Since ICLAS trains both networks, our algorithm can perform multiple times of incremental class learning. The experiments on MNIST dataset demonstrate the advantages of our algorithm.
Hide-and-Tell: Learning to Bridge Photo Streams for Visual Storytelling
Feb 03, 2020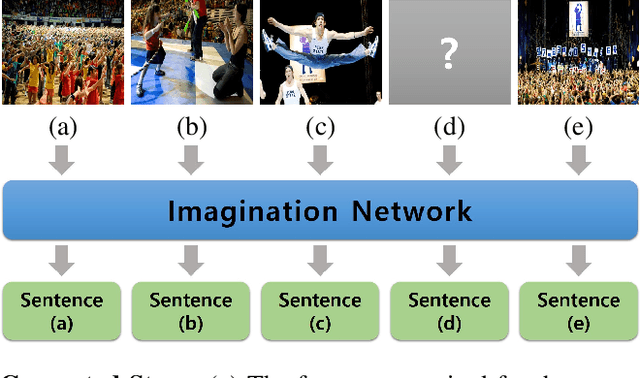
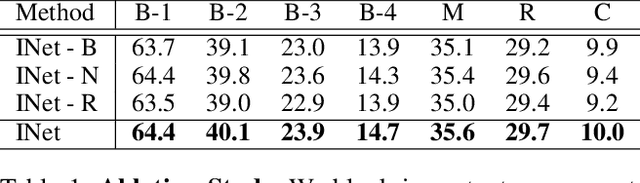
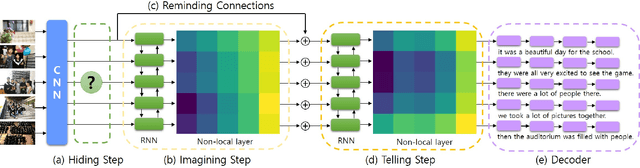
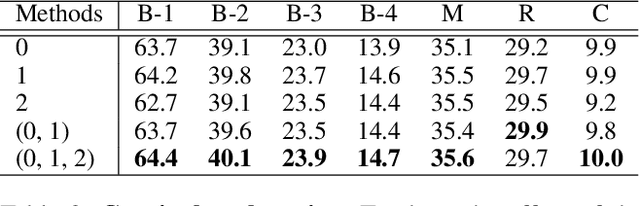
Visual storytelling is a task of creating a short story based on photo streams. Unlike existing visual captioning, storytelling aims to contain not only factual descriptions, but also human-like narration and semantics. However, the VIST dataset consists only of a small, fixed number of photos per story. Therefore, the main challenge of visual storytelling is to fill in the visual gap between photos with narrative and imaginative story. In this paper, we propose to explicitly learn to imagine a storyline that bridges the visual gap. During training, one or more photos is randomly omitted from the input stack, and we train the network to produce a full plausible story even with missing photo(s). Furthermore, we propose for visual storytelling a hide-and-tell model, which is designed to learn non-local relations across the photo streams and to refine and improve conventional RNN-based models. In experiments, we show that our scheme of hide-and-tell, and the network design are indeed effective at storytelling, and that our model outperforms previous state-of-the-art methods in automatic metrics. Finally, we qualitatively show the learned ability to interpolate storyline over visual gaps.
Gaining Extra Supervision via Multi-task learning for Multi-Modal Video Question Answering
May 28, 2019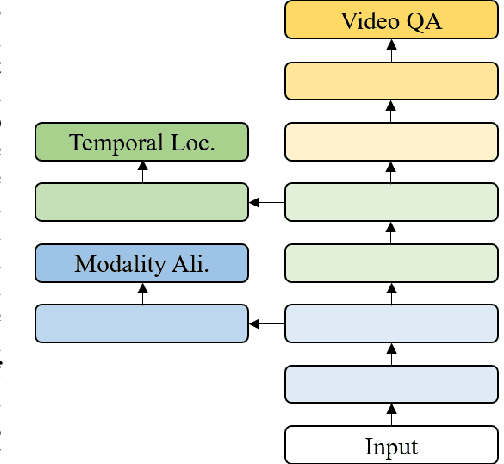
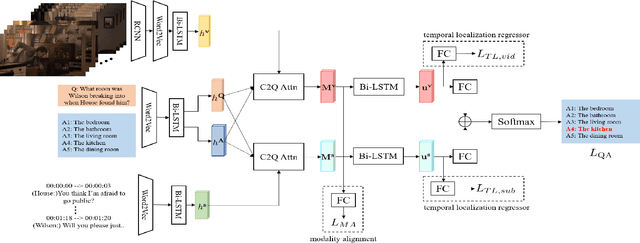
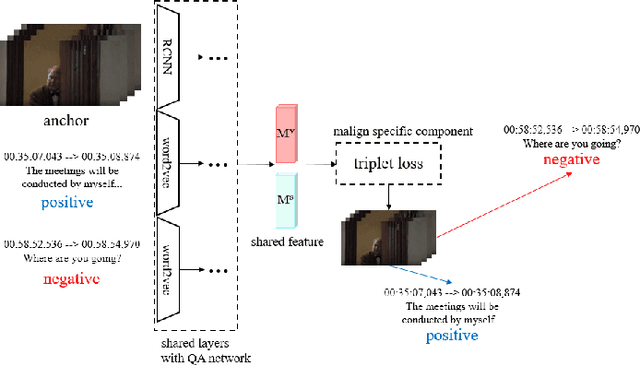
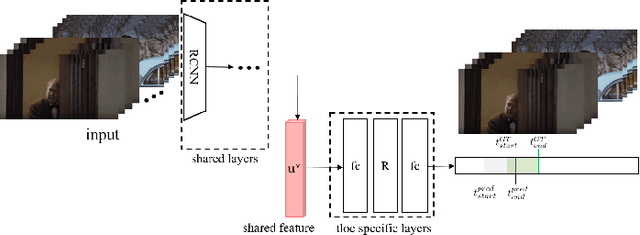
This paper proposes a method to gain extra supervision via multi-task learning for multi-modal video question answering. Multi-modal video question answering is an important task that aims at the joint understanding of vision and language. However, establishing large scale dataset for multi-modal video question answering is expensive and the existing benchmarks are relatively small to provide sufficient supervision. To overcome this challenge, this paper proposes a multi-task learning method which is composed of three main components: (1) multi-modal video question answering network that answers the question based on the both video and subtitle feature, (2) temporal retrieval network that predicts the time in the video clip where the question was generated from and (3) modality alignment network that solves metric learning problem to find correct association of video and subtitle modalities. By simultaneously solving related auxiliary tasks with hierarchically shared intermediate layers, the extra synergistic supervisions are provided. Motivated by curriculum learning, multi task ratio scheduling is proposed to learn easier task earlier to set inductive bias at the beginning of the training. The experiments on publicly available dataset TVQA shows state-of-the-art results, and ablation studies are conducted to prove the statistical validity.
Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation
May 15, 2019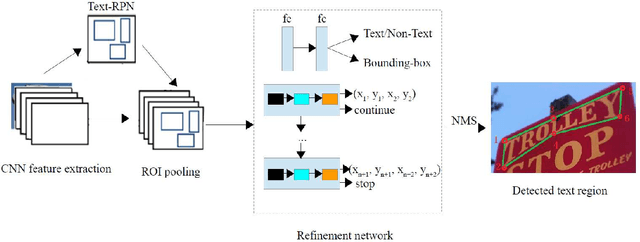
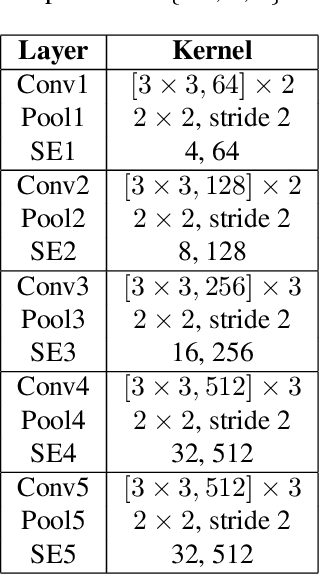

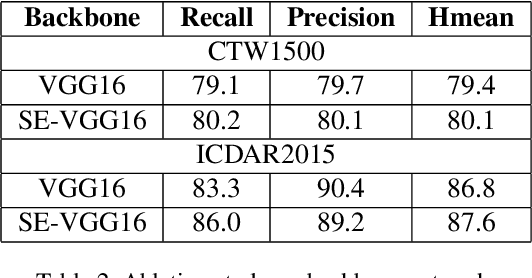
Scene text detection attracts much attention in computer vision, because it can be widely used in many applications such as real-time text translation, automatic information entry, blind person assistance, robot sensing and so on. Though many methods have been proposed for horizontal and oriented texts, detecting irregular shape texts such as curved texts is still a challenging problem. To solve the problem, we propose a robust scene text detection method with adaptive text region representation. Given an input image, a text region proposal network is first used for extracting text proposals. Then, these proposals are verified and refined with a refinement network. Here, recurrent neural network based adaptive text region representation is proposed for text region refinement, where a pair of boundary points are predicted each time step until no new points are found. In this way, text regions of arbitrary shapes are detected and represented with adaptive number of boundary points. This gives more accurate description of text regions. Experimental results on five benchmarks, namely, CTW1500, TotalText, ICDAR2013, ICDAR2015 and MSRATD500, show that the proposed method achieves state-of-the-art in scene text detection.
Progressive Attention Memory Network for Movie Story Question Answering
Apr 18, 2019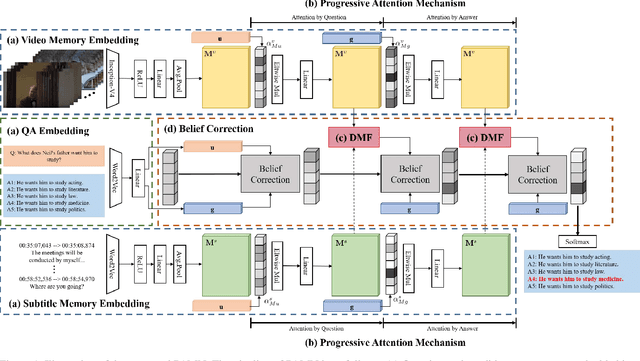

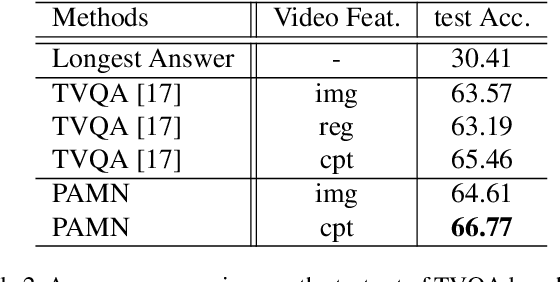
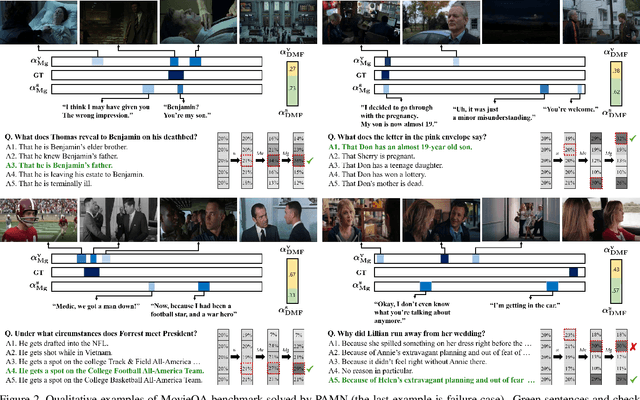
This paper proposes the progressive attention memory network (PAMN) for movie story question answering (QA). Movie story QA is challenging compared to VQA in two aspects: (1) pinpointing the temporal parts relevant to answer the question is difficult as the movies are typically longer than an hour, (2) it has both video and subtitle where different questions require different modality to infer the answer. To overcome these challenges, PAMN involves three main features: (1) progressive attention mechanism that utilizes cues from both question and answer to progressively prune out irrelevant temporal parts in memory, (2) dynamic modality fusion that adaptively determines the contribution of each modality for answering the current question, and (3) belief correction answering scheme that successively corrects the prediction score on each candidate answer. Experiments on publicly available benchmark datasets, MovieQA and TVQA, demonstrate that each feature contributes to our movie story QA architecture, PAMN, and improves performance to achieve the state-of-the-art result. Qualitative analysis by visualizing the inference mechanism of PAMN is also provided.
Learning Not to Learn: Training Deep Neural Networks with Biased Data
Dec 26, 2018
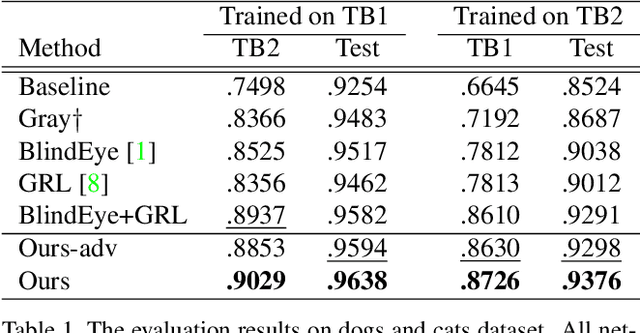
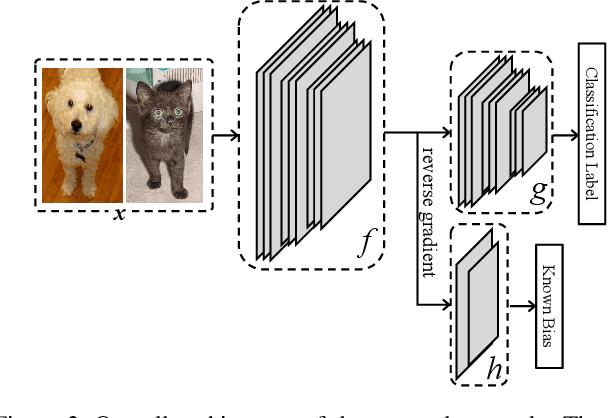
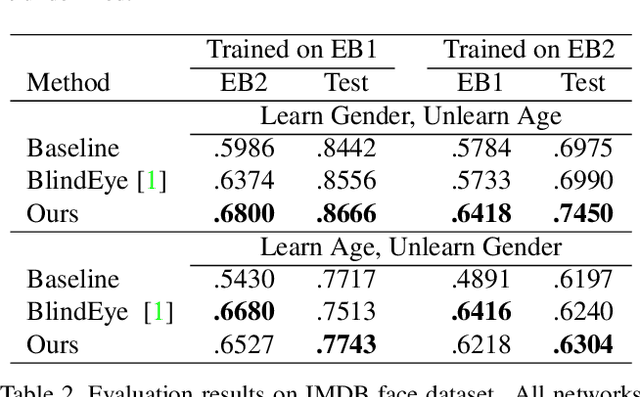
We propose a novel regularization algorithm to train deep neural networks, in which data at training time is severely biased. Since a neural network efficiently learns data distribution, a network is likely to learn the bias information to categorize input data. It leads to poor performance at test time, if the bias is, in fact, irrelevant to the categorization. In this paper, we formulate a regularization loss based on mutual information between feature embedding and bias. Based on the idea of minimizing this mutual information, we propose an iterative algorithm to unlearn the bias information. We employ an additional network to predict the bias distribution and train the network adversarially against the feature embedding network. At the end of learning, the bias prediction network is not able to predict the bias not because it is poorly trained, but because the feature embedding network successfully unlearns the bias information. We also demonstrate quantitative and qualitative experimental results which show that our algorithm effectively removes the bias information from feature embedding.