 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERIA: Verification-Centric Multimodal Instance Augmentation for Long-Tailed 3D Object Detection
Mar 25, 2026Long-tail distributions in driving datasets pose a fundamental challenge for 3D perception, as rare classes exhibit substantial intra-class diversity yet available samples cover this variation space only sparsely. Existing instance augmentation methods based on copy-paste or asset libraries improve rare-class exposure but are often limited in fine-grained diversity and scene-context placement. We propose VERIA, an image-first multimodal augmentation framework that synthesizes synchronized RGB--LiDAR instances using off-the-shelf foundation models and curates them with sequential semantic and geometric verification. This verification-centric design tends to select instances that better match real LiDAR statistics while spanning a wider range of intra-class variation. Stage-wise yield decomposition provides a log-based diagnostic of pipeline reliability. On nuScenes and Lyft, VERIA improves rare-class 3D object detection in both LiDAR-only and multimodal settings. Our code is available at https://sgvr.kaist.ac.kr/VERIA/.
Just Add $100 More: Augmenting NeRF-based Pseudo-LiDAR Point Cloud for Resolving Class-imbalance Problem
Mar 20, 2024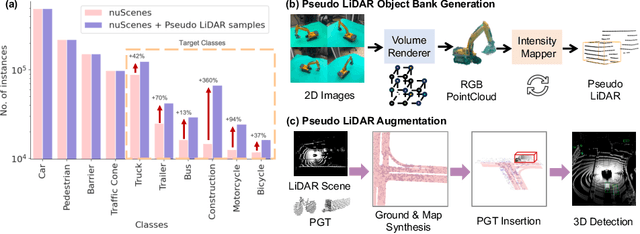
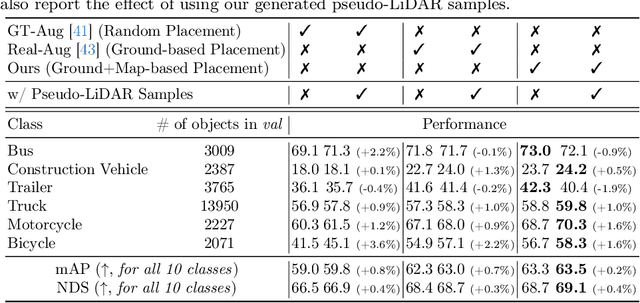
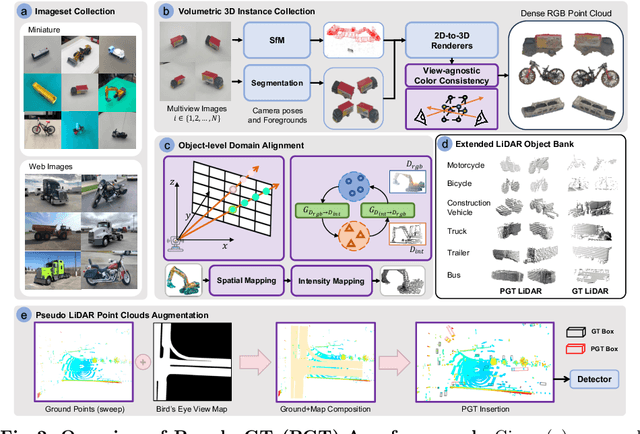
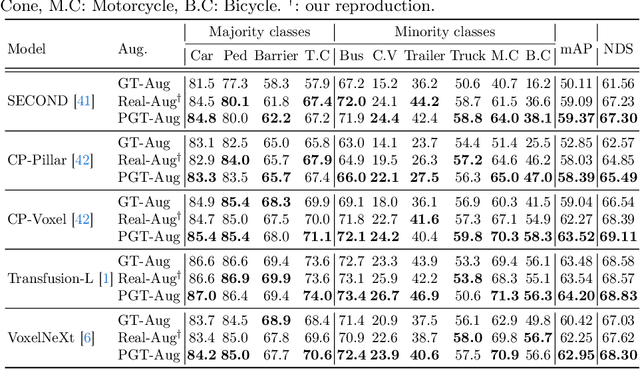
Typical LiDAR-based 3D object detection models are trained in a supervised manner with real-world data collection, which is often imbalanced over classes (or long-tailed). To deal with it, augmenting minority-class examples by sampling ground truth (GT) LiDAR points from a database and pasting them into a scene of interest is often used, but challenges still remain: inflexibility in locating GT samples and limited sample diversity. In this work, we propose to leverage pseudo-LiDAR point clouds generated (at a low cost) from videos capturing a surround view of miniatures or real-world objects of minor classes. Our method, called Pseudo Ground Truth Augmentation (PGT-Aug), consists of three main steps: (i) volumetric 3D instance reconstruction using a 2D-to-3D view synthesis model, (ii) object-level domain alignment with LiDAR intensity estimation and (iii) a hybrid context-aware placement method from ground and map information. We demonstrate the superiority and generality of our method through performance improvements in extensive experiments conducted on three popular benchmarks, i.e., nuScenes, KITTI, and Lyft, especially for the datasets with large domain gaps captured by different LiDAR configurations. Our code and data will be publicly available upon publication.
Regularized Mutual Information Neural Estimation
Nov 16, 2020
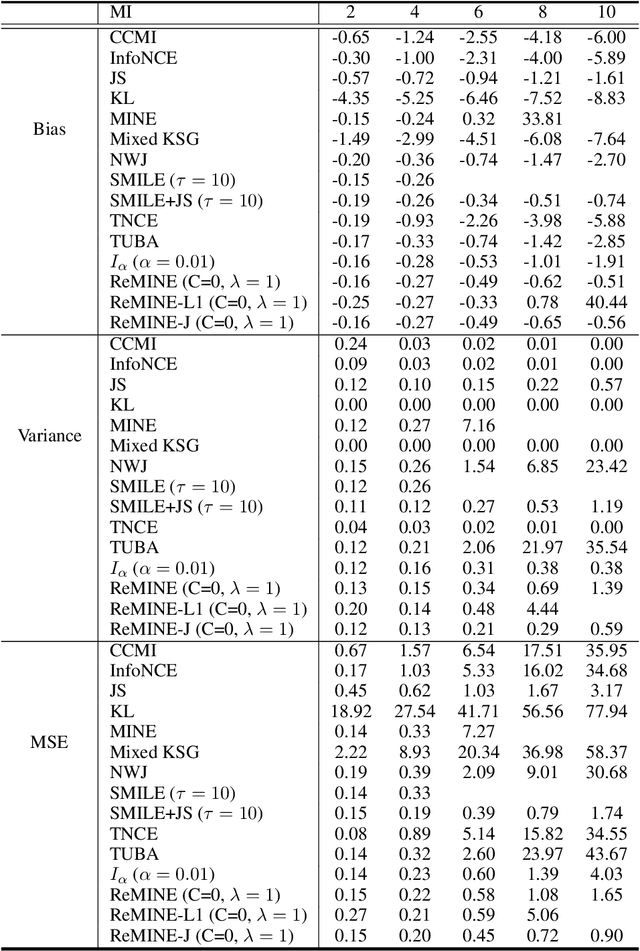
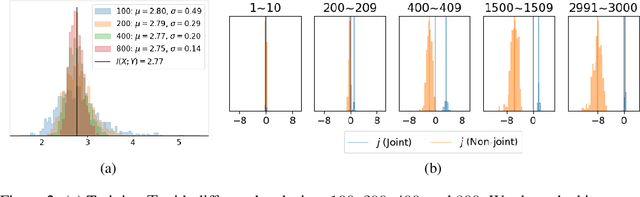
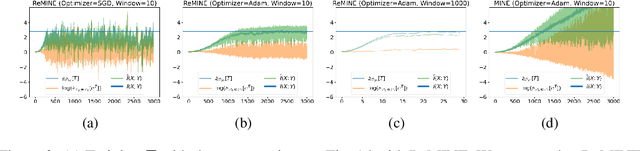
With the variational lower bound of mutual information (MI), the estimation of MI can be understood as an optimization task via stochastic gradient descent. In this work, we start by showing how Mutual Information Neural Estimator (MINE) searches for the optimal function $T$ that maximizes the Donsker-Varadhan representation. With our synthetic dataset, we directly observe the neural network outputs during the optimization to investigate why MINE succeeds or fails: We discover the drifting phenomenon, where the constant term of $T$ is shifting through the optimization process, and analyze the instability caused by the interaction between the $logsumexp$ and the insufficient batch size. Next, through theoretical and experimental evidence, we propose a novel lower bound that effectively regularizes the neural network to alleviate the problems of MINE. We also introduce an averaging strategy that produces an unbiased estimate by utilizing multiple batches to mitigate the batch size limitation. Finally, we show that $L^2$ regularization achieves significant improvements in both discrete and continuous settings.
Painting Outside as Inside: Edge Guided Image Outpainting via Bidirectional Rearrangement with Step-By-Step Learning
Oct 05, 2020
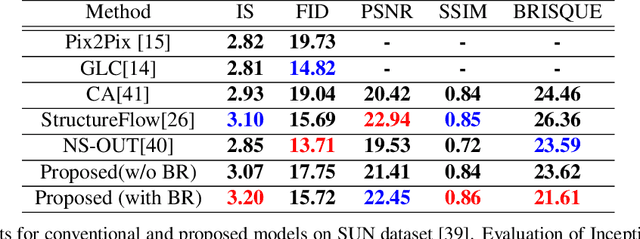
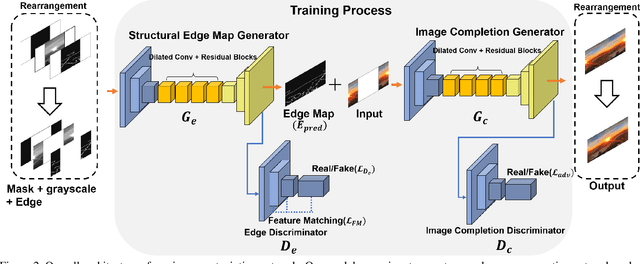
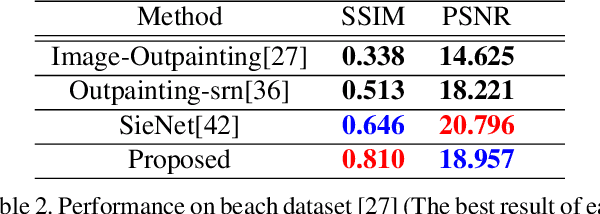
Image outpainting is a very intriguing problem as the outside of a given image can be continuously filled by considering as the context of the image. This task has two main challenges. The first is to maintain the spatial consistency in contents of generated regions and the original input. The second is to generate a high-quality large image with a small amount of adjacent information. Conventional image outpainting methods generate inconsistent, blurry, and repeated pixels. To alleviate the difficulty of an outpainting problem, we propose a novel image outpainting method using bidirectional boundary region rearrangement. We rearrange the image to benefit from the image inpainting task by reflecting more directional information. The bidirectional boundary region rearrangement enables the generation of the missing region using bidirectional information similar to that of the image inpainting task, thereby generating the higher quality than the conventional methods using unidirectional information. Moreover, we use the edge map generator that considers images as original input with structural information and hallucinates the edges of unknown regions to generate the image. Our proposed method is compared with other state-of-the-art outpainting and inpainting methods both qualitatively and quantitatively. We further compared and evaluated them using BRISQUE, one of the No-Reference image quality assessment (IQA) metrics, to evaluate the naturalness of the output. The experimental results demonstrate that our method outperforms other methods and generates new images with 360{\deg}panoramic characteristics.
End-to-End Differentiable Learning to HDR Image Synthesis for Multi-exposure Images
Jun 29, 2020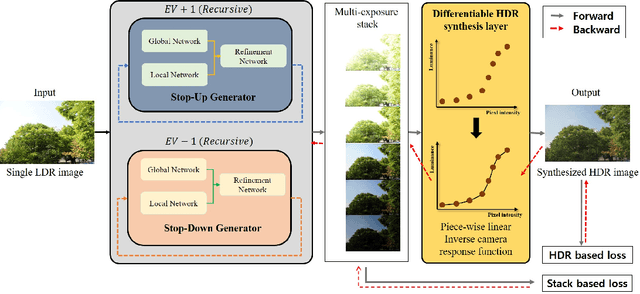
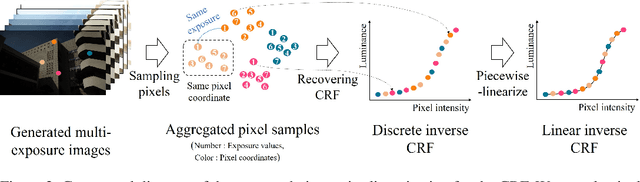
Recent deep learning-based methods have reconstructed a high dynamic range (HDR) image from a single low dynamic range (LDR) image by focusing on the exposure transfer task to reconstruct the multi-exposure stack. However, these methods often fail to fuse the multi-exposure stack into a perceptually pleasant HDR image as the local inversion artifacts are formed in the HDR imaging (HDRI) process. The artifacts arise from the impossibility of learning the whole HDRI process due to its non-differentiable structure of the camera response recovery. Therefore, we tackle the major challenge in stack reconstruction-based methods by proposing a novel framework with the fully differentiable HDRI process. Our framework enables a neural network to train the HDR image generation based on the end-to-end structure. Hence, a deep neural network can train the precise correlations between multi-exposure images in the HDRI process using our differentiable HDR synthesis layer. In addition, our network uses the image decomposition and the recursive process to facilitate the exposure transfer task and to adaptively respond to recursion frequency. The experimental results show that the proposed network outperforms the state-of-the-art quatitative and qualitative results in terms of both the exposure transfer tasks and the whole HDRI process.
Deep Chain HDRI: Reconstructing a High Dynamic Range Image from a Single Low Dynamic Range Image
Jan 19, 2018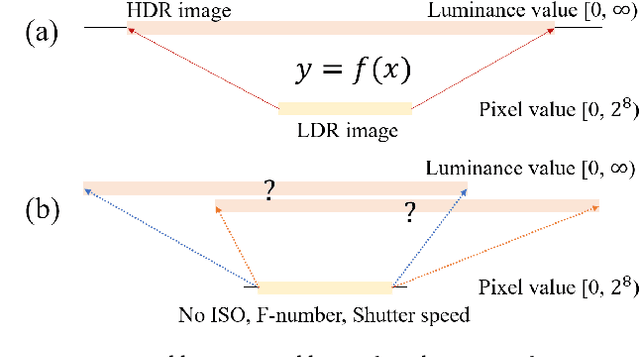
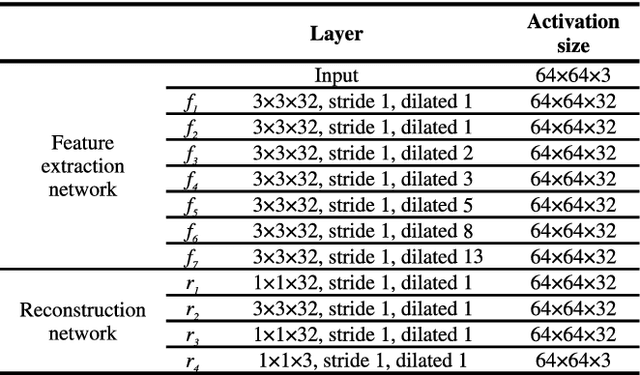
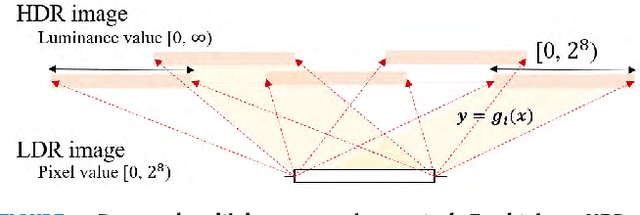
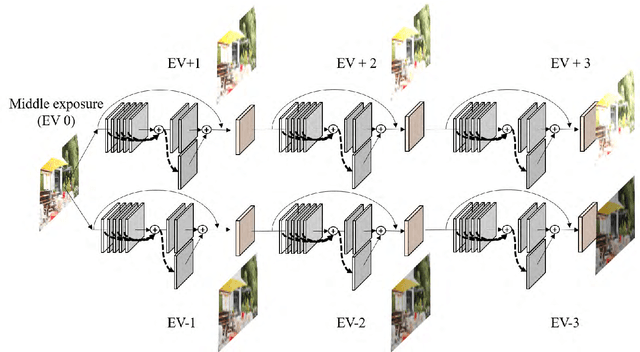
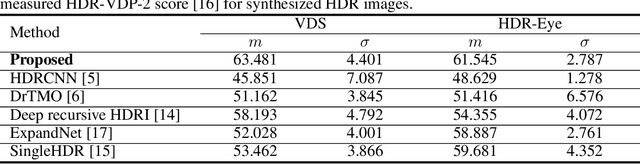
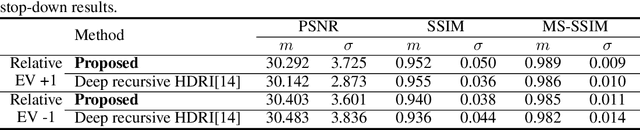
In this paper, we propose a novel deep neural network model that reconstructs a high dynamic range (HDR) image from a single low dynamic range (LDR) image. The proposed model is based on a convolutional neural network composed of dilated convolutional layers, and infers LDR images with various exposures and illumination from a single LDR image of the same scene. Then, the final HDR image can be formed by merging these inference results. It is relatively easy for the proposed method to find the mapping between the LDR and an HDR with a different bit depth because of the chaining structure inferring the relationship between the LDR images with brighter (or darker) exposures from a given LDR image. The method not only extends the range, but also has the advantage of restoring the light information of the actual physical world. For the HDR images obtained by the proposed method, the HDR-VDP2 Q score, which is the most popular evaluation metric for HDR images, was 56.36 for a display with a 1920$\times$1200 resolution, which is an improvement of 6 compared with the scores of conventional algorithms. In addition, when comparing the peak signal-to-noise ratio values for tone mapped HDR images generated by the proposed and conventional algorithms, the average value obtained by the proposed algorithm is 30.86 dB, which is 10 dB higher than those obtained by the conventional algorithms.