 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIPA: Visual Informative Part Attention for Referring Image Segmentation
Feb 16, 2026Referring Image Segmentation (RIS) aims to segment a target object described by a natural language expression. Existing methods have evolved by leveraging the vision information into the language tokens. To more effectively exploit visual contexts for fine-grained segmentation, we propose a novel Visual Informative Part Attention (VIPA) framework for referring image segmentation. VIPA leverages the informative parts of visual contexts, called a visual expression, which can effectively provide the structural and semantic visual target information to the network. This design reduces high-variance cross-modal projection and enhances semantic consistency in an attention mechanism of the referring image segmentation. We also design a visual expression generator (VEG) module, which retrieves informative visual tokens via local-global linguistic context cues and refines the retrieved tokens for reducing noise information and sharing informative visual attributes. This module allows the visual expression to consider comprehensive contexts and capture semantic visual contexts of informative regions. In this way, our framework enables the network's attention to robustly align with the fine-grained regions of interest. Extensive experiments and visual analysis demonstrate the effectiveness of our approach. Our VIPA outperforms the existing state-of-the-art methods on four public RIS benchmarks.
ICP-4D: Bridging Iterative Closest Point and LiDAR Panoptic Segmentation
Dec 22, 2025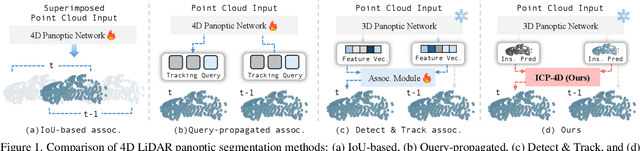
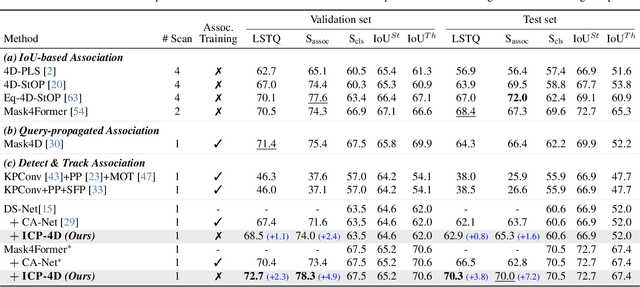
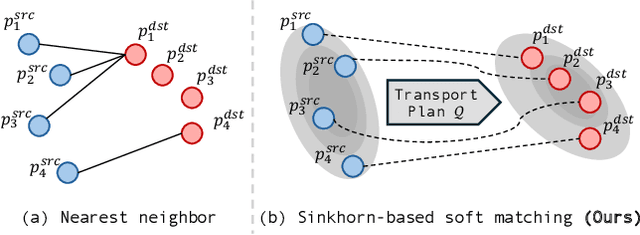
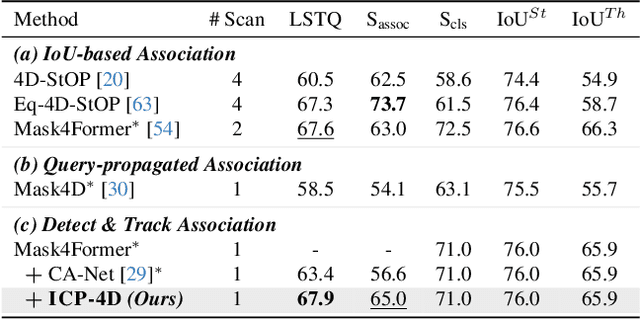
Dominant paradigms for 4D LiDAR panoptic segmentation are usually required to train deep neural networks with large superimposed point clouds or design dedicated modules for instance association. However, these approaches perform redundant point processing and consequently become computationally expensive, yet still overlook the rich geometric priors inherently provided by raw point clouds. To this end, we introduce ICP-4D, a simple yet effective training-free framework that unifies spatial and temporal reasoning through geometric relations among instance-level point sets. Specifically, we apply the Iterative Closest Point (ICP) algorithm to directly associate temporally consistent instances by aligning the source and target point sets through the estimated transformation. To stabilize association under noisy instance predictions, we introduce a Sinkhorn-based soft matching. This exploits the underlying instance distribution to obtain accurate point-wise correspondences, resulting in robust geometric alignment. Furthermore, our carefully designed pipeline, which considers three instance types-static, dynamic, and missing-offers computational efficiency and occlusion-aware matching. Our extensive experiments across both SemanticKITTI and panoptic nuScenes demonstrate that our method consistently outperforms state-of-the-art approaches, even without additional training or extra point cloud inputs.
MetaSeg: MetaFormer-based Global Contexts-aware Network for Efficient Semantic Segmentation
Aug 15, 2024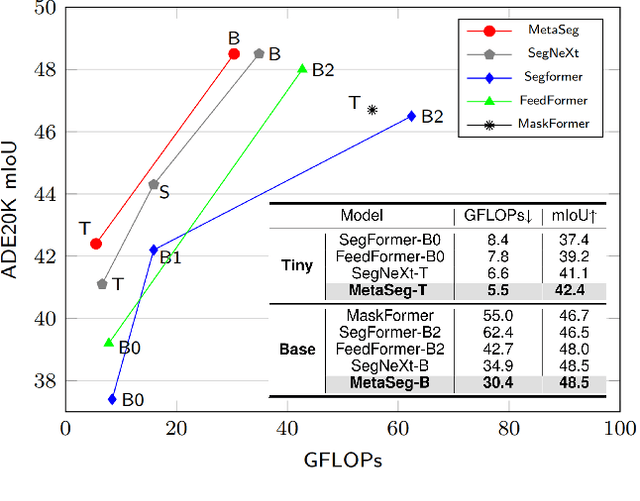
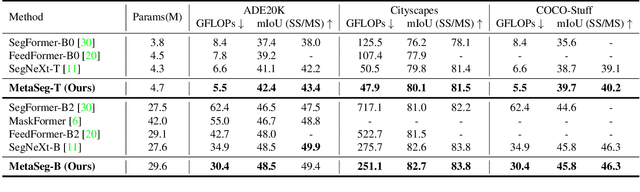
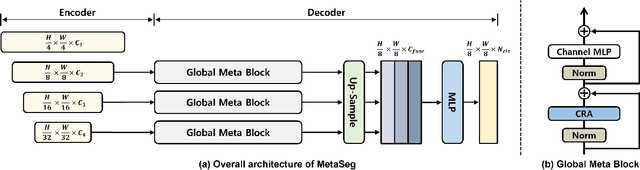
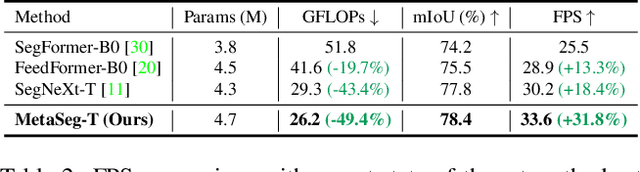
Beyond the Transformer, it is important to explore how to exploit the capacity of the MetaFormer, an architecture that is fundamental to the performance improvements of the Transformer. Previous studies have exploited it only for the backbone network. Unlike previous studies, we explore the capacity of the Metaformer architecture more extensively in the semantic segmentation task. We propose a powerful semantic segmentation network, MetaSeg, which leverages the Metaformer architecture from the backbone to the decoder. Our MetaSeg shows that the MetaFormer architecture plays a significant role in capturing the useful contexts for the decoder as well as for the backbone. In addition, recent segmentation methods have shown that using a CNN-based backbone for extracting the spatial information and a decoder for extracting the global information is more effective than using a transformer-based backbone with a CNN-based decoder. This motivates us to adopt the CNN-based backbone using the MetaFormer block and design our MetaFormer-based decoder, which consists of a novel self-attention module to capture the global contexts. To consider both the global contexts extraction and the computational efficiency of the self-attention for semantic segmentation, we propose a Channel Reduction Attention (CRA) module that reduces the channel dimension of the query and key into the one dimension. In this way, our proposed MetaSeg outperforms the previous state-of-the-art methods with more efficient computational costs on popular semantic segmentation and a medical image segmentation benchmark, including ADE20K, Cityscapes, COCO-stuff, and Synapse. The code is available at https://github.com/hyunwoo137/MetaSeg.
AttentionHand: Text-driven Controllable Hand Image Generation for 3D Hand Reconstruction in the Wild
Jul 25, 2024



Recently, there has been a significant amount of research conducted on 3D hand reconstruction to use various forms of human-computer interaction. However, 3D hand reconstruction in the wild is challenging due to extreme lack of in-the-wild 3D hand datasets. Especially, when hands are in complex pose such as interacting hands, the problems like appearance similarity, self-handed occclusion and depth ambiguity make it more difficult. To overcome these issues, we propose AttentionHand, a novel method for text-driven controllable hand image generation. Since AttentionHand can generate various and numerous in-the-wild hand images well-aligned with 3D hand label, we can acquire a new 3D hand dataset, and can relieve the domain gap between indoor and outdoor scenes. Our method needs easy-to-use four modalities (i.e, an RGB image, a hand mesh image from 3D label, a bounding box, and a text prompt). These modalities are embedded into the latent space by the encoding phase. Then, through the text attention stage, hand-related tokens from the given text prompt are attended to highlight hand-related regions of the latent embedding. After the highlighted embedding is fed to the visual attention stage, hand-related regions in the embedding are attended by conditioning global and local hand mesh images with the diffusion-based pipeline. In the decoding phase, the final feature is decoded to new hand images, which are well-aligned with the given hand mesh image and text prompt. As a result, AttentionHand achieved state-of-the-art among text-to-hand image generation models, and the performance of 3D hand mesh reconstruction was improved by additionally training with hand images generated by AttentionHand.
Embedding-Free Transformer with Inference Spatial Reduction for Efficient Semantic Segmentation
Jul 24, 2024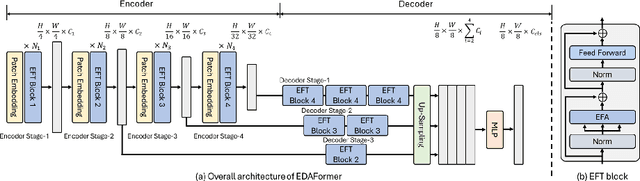
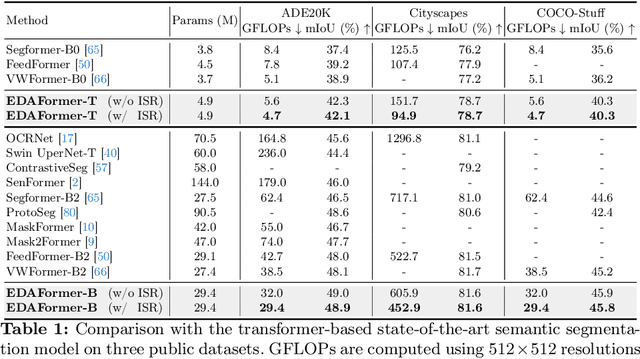
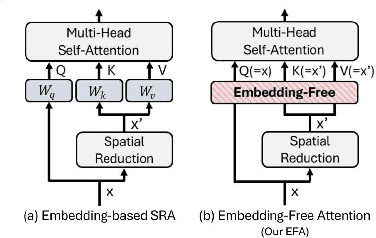
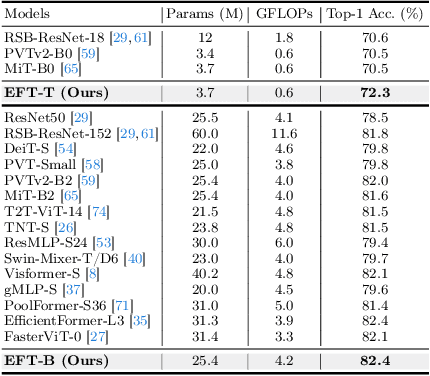
We present an Encoder-Decoder Attention Transformer, EDAFormer, which consists of the Embedding-Free Transformer (EFT) encoder and the all-attention decoder leveraging our Embedding-Free Attention (EFA) structure. The proposed EFA is a novel global context modeling mechanism that focuses on functioning the global non-linearity, not the specific roles of the query, key and value. For the decoder, we explore the optimized structure for considering the globality, which can improve the semantic segmentation performance. In addition, we propose a novel Inference Spatial Reduction (ISR) method for the computational efficiency. Different from the previous spatial reduction attention methods, our ISR method further reduces the key-value resolution at the inference phase, which can mitigate the computation-performance trade-off gap for the efficient semantic segmentation. Our EDAFormer shows the state-of-the-art performance with the efficient computation compared to the existing transformer-based semantic segmentation models in three public benchmarks, including ADE20K, Cityscapes and COCO-Stuff. Furthermore, our ISR method reduces the computational cost by up to 61% with minimal mIoU performance degradation on Cityscapes dataset. The code is available at https://github.com/hyunwoo137/EDAFormer.
Integrated In-vehicle Monitoring System Using 3D Human Pose Estimation and Seat Belt Segmentation
Apr 17, 2022

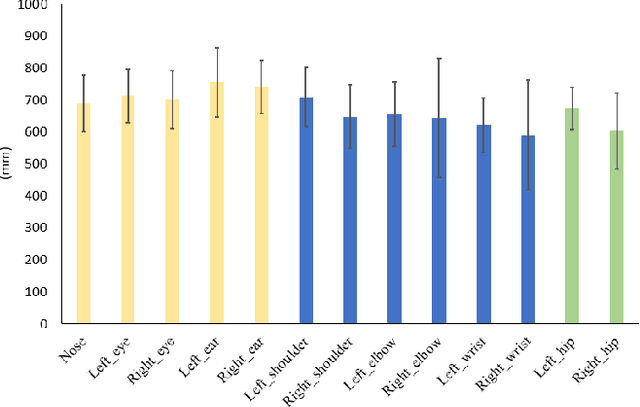
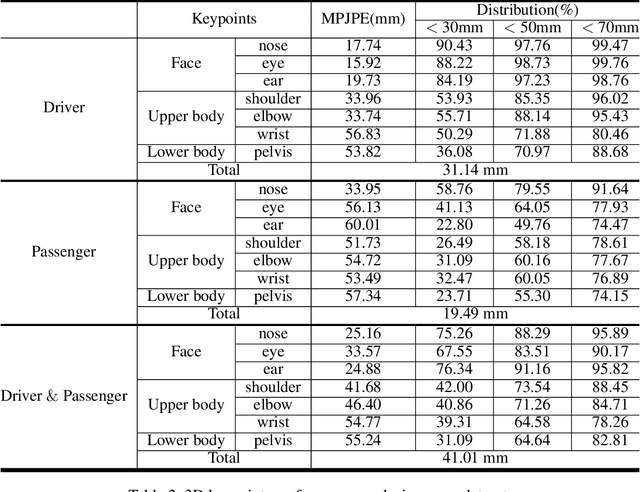
Recently, along with interest in autonomous vehicles, the importance of monitoring systems for both drivers and passengers inside vehicles has been increasing. This paper proposes a novel in-vehicle monitoring system the combines 3D pose estimation, seat-belt segmentation, and seat-belt status classification networks. Our system outputs various information necessary for monitoring by accurately considering the data characteristics of the in-vehicle environment. Specifically, the proposed 3D pose estimation directly estimates the absolute coordinates of keypoints for a driver and passengers, and the proposed seat-belt segmentation is implemented by applying a structure based on the feature pyramid. In addition, we propose a classification task to distinguish between normal and abnormal states of wearing a seat belt using results that combine 3D pose estimation with seat-belt segmentation. These tasks can be learned simultaneously and operate in real-time. Our method was evaluated on a private dataset we newly created and annotated. The experimental results show that our method has significantly high performance that can be applied directly to real in-vehicle monitoring systems.
AnoSeg: Anomaly Segmentation Network Using Self-Supervised Learning
Oct 07, 2021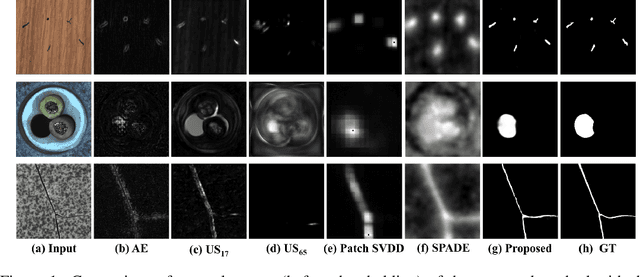
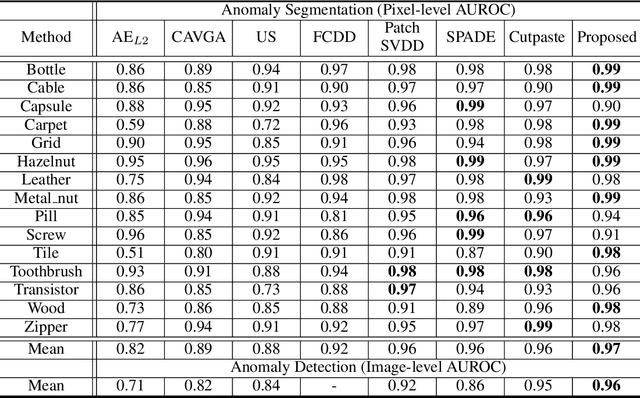
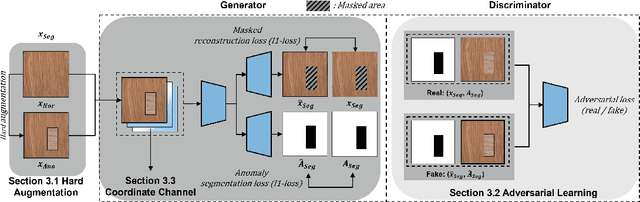

Anomaly segmentation, which localizes defective areas, is an important component in large-scale industrial manufacturing. However, most recent researches have focused on anomaly detection. This paper proposes a novel anomaly segmentation network (AnoSeg) that can directly generate an accurate anomaly map using self-supervised learning. For highly accurate anomaly segmentation, the proposed AnoSeg considers three novel techniques: Anomaly data generation based on hard augmentation, self-supervised learning with pixel-wise and adversarial losses, and coordinate channel concatenation. First, to generate synthetic anomaly images and reference masks for normal data, the proposed method uses hard augmentation to change the normal sample distribution. Then, the proposed AnoSeg is trained in a self-supervised learning manner from the synthetic anomaly data and normal data. Finally, the coordinate channel, which represents the pixel location information, is concatenated to an input of AnoSeg to consider the positional relationship of each pixel in the image. The estimated anomaly map can also be utilized to improve the performance of anomaly detection. Our experiments show that the proposed method outperforms the state-of-the-art anomaly detection and anomaly segmentation methods for the MVTec AD dataset. In addition, we compared the proposed method with the existing methods through the intersection over union (IoU) metric commonly used in segmentation tasks and demonstrated the superiority of our method for anomaly segmentation.
Core-set Sampling for Efficient Neural Architecture Search
Jul 08, 2021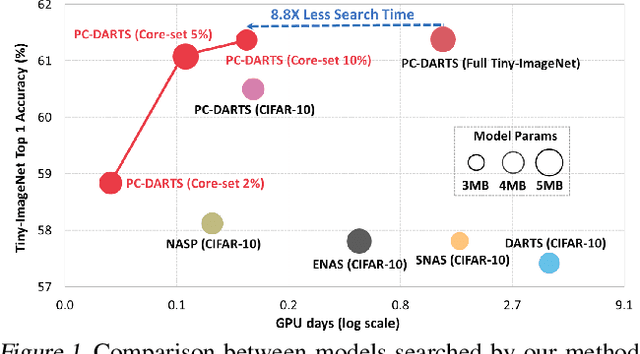
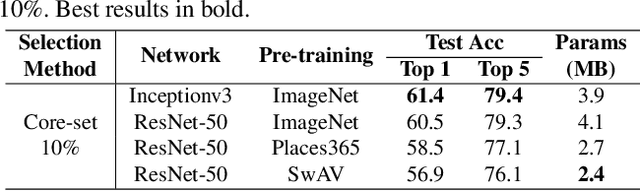
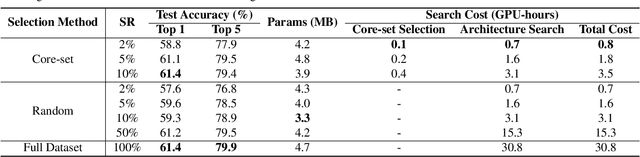
Neural architecture search (NAS), an important branch of automatic machine learning, has become an effective approach to automate the design of deep learning models. However, the major issue in NAS is how to reduce the large search time imposed by the heavy computational burden. While most recent approaches focus on pruning redundant sets or developing new search methodologies, this paper attempts to formulate the problem based on the data curation manner. Our key strategy is to search the architecture using summarized data distribution, i.e., core-set. Typically, many NAS algorithms separate searching and training stages, and the proposed core-set methodology is only used in search stage, thus their performance degradation can be minimized. In our experiments, we were able to save overall computational time from 30.8 hours to 3.5 hours, 8.8x reduction, on a single RTX 3090 GPU without sacrificing accuracy.
Selective Focusing Learning in Conditional GANs
Jul 08, 2021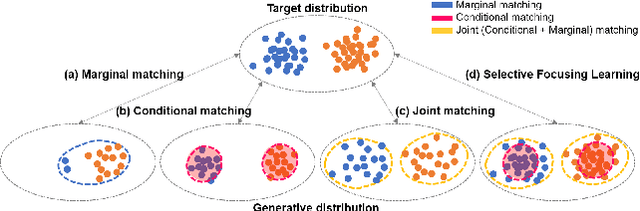
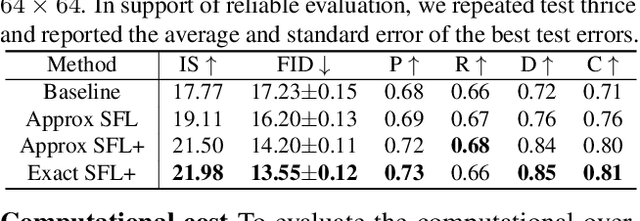
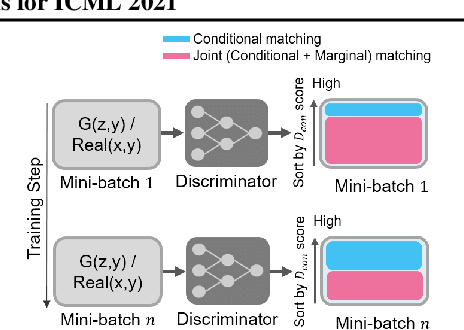

Conditional generative adversarial networks (cGANs) have demonstrated remarkable success due to their class-wise controllability and superior quality for complex generation tasks. Typical cGANs solve the joint distribution matching problem by decomposing two easier sub-problems: marginal matching and conditional matching. From our toy experiments, we found that it is the best to apply only conditional matching to certain samples due to the content-aware optimization of the discriminator. This paper proposes a simple (a few lines of code) but effective training methodology, selective focusing learning, which enforces the discriminator and generator to learn easy samples of each class rapidly while maintaining diversity. Our key idea is to selectively apply conditional and joint matching for the data in each mini-batch. We conducted experiments on recent cGAN variants in ImageNet (64x64 and 128x128), CIFAR-10, and CIFAR-100 datasets, and improved the performance significantly (up to 35.18% in terms of FID) without sacrificing diversity.
Attention Map-guided Two-stage Anomaly Detection using Hard Augmentation
Mar 31, 2021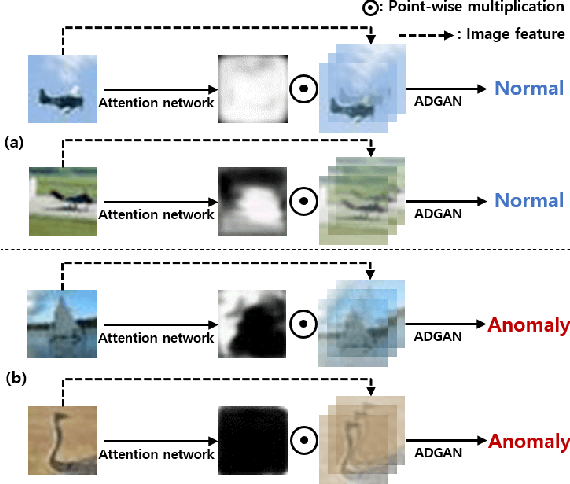
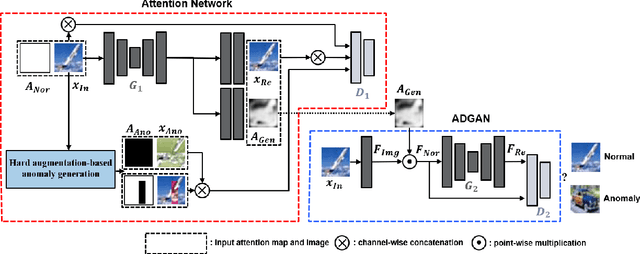

Anomaly detection is a task that recognizes whether an input sample is included in the distribution of a target normal class or an anomaly class. Conventional generative adversarial network (GAN)-based methods utilize an entire image including foreground and background as an input. However, in these methods, a useless region unrelated to the normal class (e.g., unrelated background) is learned as normal class distribution, thereby leading to false detection. To alleviate this problem, this paper proposes a novel two-stage network consisting of an attention network and an anomaly detection GAN (ADGAN). The attention network generates an attention map that can indicate the region representing the normal class distribution. To generate an accurate attention map, we propose the attention loss and the adversarial anomaly loss based on synthetic anomaly samples generated from hard augmentation. By applying the attention map to an image feature map, ADGAN learns the normal class distribution from which the useless region is removed, and it is possible to greatly reduce the problem difficulty of the anomaly detection task. Additionally, the estimated attention map can be used for anomaly segmentation because it can distinguish between normal and anomaly regions. As a result, the proposed method outperforms the state-of-the-art anomaly detection and anomaly segmentation methods for widely used datasets.