 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Image Compression and Restoration for Digital Pathology
Apr 01, 2025Digital pathology images play a crucial role in medical diagnostics, but their ultra-high resolution and large file sizes pose significant challenges for storage, transmission, and real-time visualization. To address these issues, we propose CLERIC, a novel deep learning-based image compression framework designed specifically for whole slide images (WSIs). CLERIC integrates a learnable lifting scheme and advanced convolutional techniques to enhance compression efficiency while preserving critical pathological details. Our framework employs a lifting-scheme transform in the analysis stage to decompose images into low- and high-frequency components, enabling more structured latent representations. These components are processed through parallel encoders incorporating Deformable Residual Blocks (DRB) and Recurrent Residual Blocks (R2B) to improve feature extraction and spatial adaptability. The synthesis stage applies an inverse lifting transform for effective image reconstruction, ensuring high-fidelity restoration of fine-grained tissue structures. We evaluate CLERIC on a digital pathology image dataset and compare its performance against state-of-the-art learned image compression (LIC) models. Experimental results demonstrate that CLERIC achieves superior rate-distortion (RD) performance, significantly reducing storage requirements while maintaining high diagnostic image quality. Our study highlights the potential of deep learning-based compression in digital pathology, facilitating efficient data management and long-term storage while ensuring seamless integration into clinical workflows and AI-assisted diagnostic systems. Code and models are available at: https://github.com/pnu-amilab/CLERIC.
MetaSeg: MetaFormer-based Global Contexts-aware Network for Efficient Semantic Segmentation
Aug 15, 2024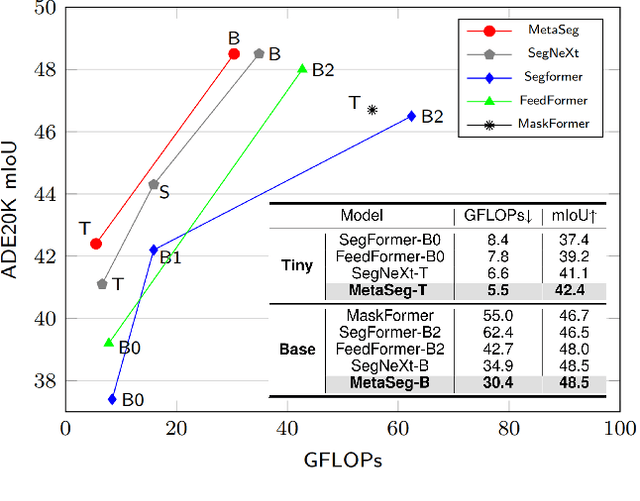
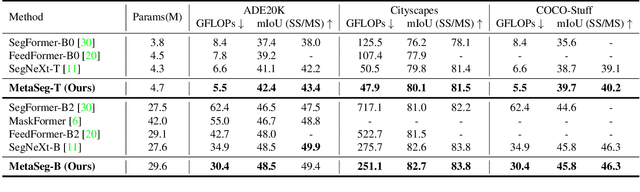
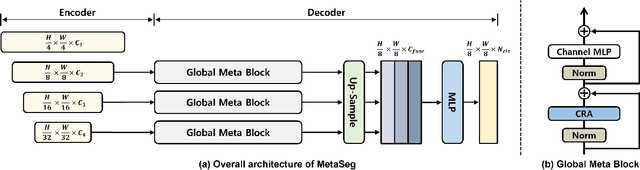
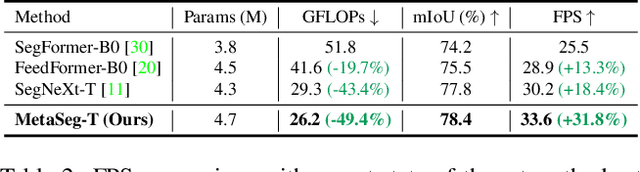
Beyond the Transformer, it is important to explore how to exploit the capacity of the MetaFormer, an architecture that is fundamental to the performance improvements of the Transformer. Previous studies have exploited it only for the backbone network. Unlike previous studies, we explore the capacity of the Metaformer architecture more extensively in the semantic segmentation task. We propose a powerful semantic segmentation network, MetaSeg, which leverages the Metaformer architecture from the backbone to the decoder. Our MetaSeg shows that the MetaFormer architecture plays a significant role in capturing the useful contexts for the decoder as well as for the backbone. In addition, recent segmentation methods have shown that using a CNN-based backbone for extracting the spatial information and a decoder for extracting the global information is more effective than using a transformer-based backbone with a CNN-based decoder. This motivates us to adopt the CNN-based backbone using the MetaFormer block and design our MetaFormer-based decoder, which consists of a novel self-attention module to capture the global contexts. To consider both the global contexts extraction and the computational efficiency of the self-attention for semantic segmentation, we propose a Channel Reduction Attention (CRA) module that reduces the channel dimension of the query and key into the one dimension. In this way, our proposed MetaSeg outperforms the previous state-of-the-art methods with more efficient computational costs on popular semantic segmentation and a medical image segmentation benchmark, including ADE20K, Cityscapes, COCO-stuff, and Synapse. The code is available at https://github.com/hyunwoo137/MetaSeg.
Cross-aware Early Fusion with Stage-divided Vision and Language Transformer Encoders for Referring Image Segmentation
Aug 14, 2024



Referring segmentation aims to segment a target object related to a natural language expression. Key challenges of this task are understanding the meaning of complex and ambiguous language expressions and determining the relevant regions in the image with multiple objects by referring to the expression. Recent models have focused on the early fusion with the language features at the intermediate stage of the vision encoder, but these approaches have a limitation that the language features cannot refer to the visual information. To address this issue, this paper proposes a novel architecture, Cross-aware early fusion with stage-divided Vision and Language Transformer encoders (CrossVLT), which allows both language and vision encoders to perform the early fusion for improving the ability of the cross-modal context modeling. Unlike previous methods, our method enables the vision and language features to refer to each other's information at each stage to mutually enhance the robustness of both encoders. Furthermore, unlike the conventional scheme that relies solely on the high-level features for the cross-modal alignment, we introduce a feature-based alignment scheme that enables the low-level to high-level features of the vision and language encoders to engage in the cross-modal alignment. By aligning the intermediate cross-modal features in all encoder stages, this scheme leads to effective cross-modal fusion. In this way, the proposed approach is simple but effective for referring image segmentation, and it outperforms the previous state-of-the-art methods on three public benchmarks.
Embedding-Free Transformer with Inference Spatial Reduction for Efficient Semantic Segmentation
Jul 24, 2024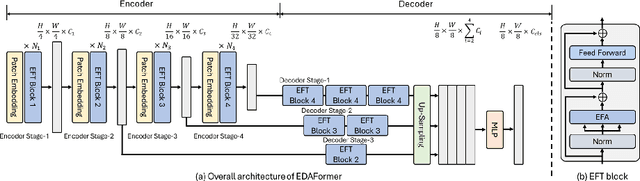
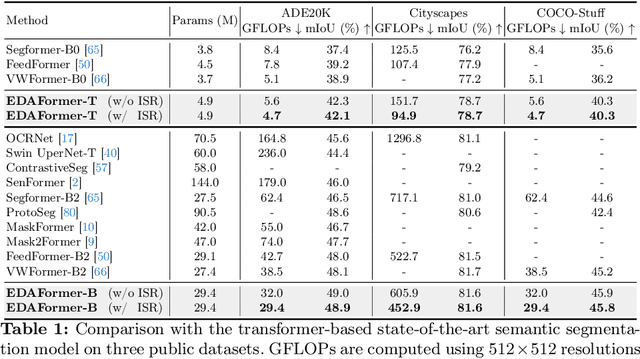
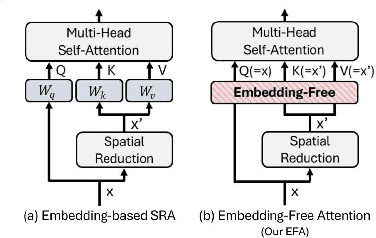
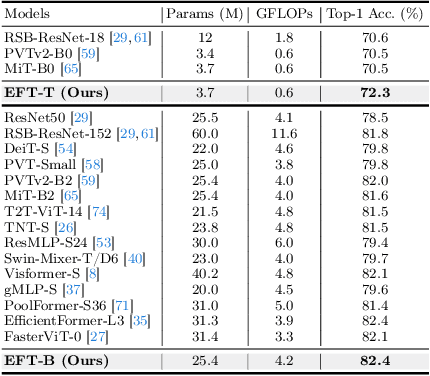
We present an Encoder-Decoder Attention Transformer, EDAFormer, which consists of the Embedding-Free Transformer (EFT) encoder and the all-attention decoder leveraging our Embedding-Free Attention (EFA) structure. The proposed EFA is a novel global context modeling mechanism that focuses on functioning the global non-linearity, not the specific roles of the query, key and value. For the decoder, we explore the optimized structure for considering the globality, which can improve the semantic segmentation performance. In addition, we propose a novel Inference Spatial Reduction (ISR) method for the computational efficiency. Different from the previous spatial reduction attention methods, our ISR method further reduces the key-value resolution at the inference phase, which can mitigate the computation-performance trade-off gap for the efficient semantic segmentation. Our EDAFormer shows the state-of-the-art performance with the efficient computation compared to the existing transformer-based semantic segmentation models in three public benchmarks, including ADE20K, Cityscapes and COCO-Stuff. Furthermore, our ISR method reduces the computational cost by up to 61% with minimal mIoU performance degradation on Cityscapes dataset. The code is available at https://github.com/hyunwoo137/EDAFormer.