 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Variational Contrastive Learning
Jun 11, 2025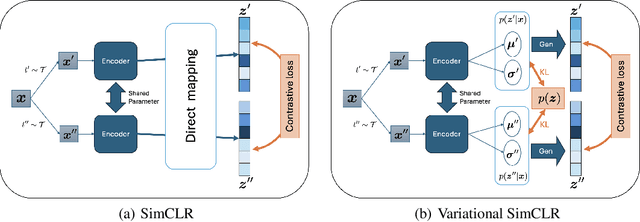

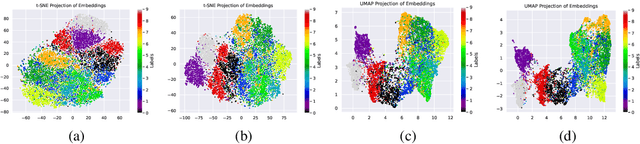
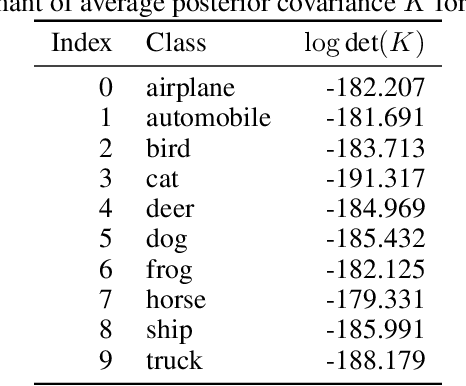
Deterministic embeddings learned by contrastive learning (CL) methods such as SimCLR and SupCon achieve state-of-the-art performance but lack a principled mechanism for uncertainty quantification. We propose Variational Contrastive Learning (VCL), a decoder-free framework that maximizes the evidence lower bound (ELBO) by interpreting the InfoNCE loss as a surrogate reconstruction term and adding a KL divergence regularizer to a uniform prior on the unit hypersphere. We model the approximate posterior $q_\theta(z|x)$ as a projected normal distribution, enabling the sampling of probabilistic embeddings. Our two instantiations--VSimCLR and VSupCon--replace deterministic embeddings with samples from $q_\theta(z|x)$ and incorporate a normalized KL term into the loss. Experiments on multiple benchmarks demonstrate that VCL mitigates dimensional collapse, enhances mutual information with class labels, and matches or outperforms deterministic baselines in classification accuracy, all the while providing meaningful uncertainty estimates through the posterior model. VCL thus equips contrastive learning with a probabilistic foundation, serving as a new basis for contrastive approaches.
Learned Image Compression and Restoration for Digital Pathology
Apr 01, 2025Digital pathology images play a crucial role in medical diagnostics, but their ultra-high resolution and large file sizes pose significant challenges for storage, transmission, and real-time visualization. To address these issues, we propose CLERIC, a novel deep learning-based image compression framework designed specifically for whole slide images (WSIs). CLERIC integrates a learnable lifting scheme and advanced convolutional techniques to enhance compression efficiency while preserving critical pathological details. Our framework employs a lifting-scheme transform in the analysis stage to decompose images into low- and high-frequency components, enabling more structured latent representations. These components are processed through parallel encoders incorporating Deformable Residual Blocks (DRB) and Recurrent Residual Blocks (R2B) to improve feature extraction and spatial adaptability. The synthesis stage applies an inverse lifting transform for effective image reconstruction, ensuring high-fidelity restoration of fine-grained tissue structures. We evaluate CLERIC on a digital pathology image dataset and compare its performance against state-of-the-art learned image compression (LIC) models. Experimental results demonstrate that CLERIC achieves superior rate-distortion (RD) performance, significantly reducing storage requirements while maintaining high diagnostic image quality. Our study highlights the potential of deep learning-based compression in digital pathology, facilitating efficient data management and long-term storage while ensuring seamless integration into clinical workflows and AI-assisted diagnostic systems. Code and models are available at: https://github.com/pnu-amilab/CLERIC.
Variable Selection in Convex Piecewise Linear Regression
Nov 04, 2024



This paper presents Sparse Gradient Descent as a solution for variable selection in convex piecewise linear regression where the model is given as $\mathrm{max}\langle a_j^\star, x \rangle + b_j^\star$ for $j = 1,\dots,k$ where $x \in \mathbb R^d$ is the covariate vector. Here, $\{a_j^\star\}_{j=1}^k$ and $\{b_j^\star\}_{j=1}^k$ denote the ground-truth weight vectors and intercepts. A non-asymptotic local convergence analysis is provided for Sp-GD under sub-Gaussian noise when the covariate distribution satisfies sub-Gaussianity and anti-concentration property. When the model order and parameters are fixed, Sp-GD provides an $\epsilon$-accurate estimate given $\mathcal{O}(\max(\epsilon^{-2}\sigma_z^2,1)s\log(d/s))$ observations where $\sigma_z^2$ denotes the noise variance. This also implies the exact parameter recovery by Sp-GD from $\mathcal{O}(s\log(d/s))$ noise-free observations. Since optimizing the squared loss for sparse max-affine is non-convex, an initialization scheme is proposed to provide a suitable initial estimate within the basin of attraction for Sp-GD, i.e. sufficiently accurate to invoke the convergence guarantees. The initialization scheme uses sparse principal component analysis to estimate the subspace spanned by $\{ a_j^\star\}_{j=1}^k$ then applies an $r$-covering search to estimate the model parameters. A non-asymptotic analysis is presented for this initialization scheme when the covariates and noise samples follow Gaussian distributions. When the model order and parameters are fixed, this initialization scheme provides an $\epsilon$-accurate estimate given $\mathcal{O}(\epsilon^{-2}\max(\sigma_z^4,\sigma_z^2,1)s^2\log^4(d))$ observations. Numerical Monte Carlo results corroborate theoretical findings for Sp-GD and the initialization scheme.
Max-affine regression via first-order methods
Aug 15, 2023



We consider regression of a max-affine model that produces a piecewise linear model by combining affine models via the max function. The max-affine model ubiquitously arises in applications in signal processing and statistics including multiclass classification, auction problems, and convex regression. It also generalizes phase retrieval and learning rectifier linear unit activation functions. We present a non-asymptotic convergence analysis of gradient descent (GD) and mini-batch stochastic gradient descent (SGD) for max-affine regression when the model is observed at random locations following the sub-Gaussianity and an anti-concentration with additive sub-Gaussian noise. Under these assumptions, a suitably initialized GD and SGD converge linearly to a neighborhood of the ground truth specified by the corresponding error bound. We provide numerical results that corroborate the theoretical finding. Importantly, SGD not only converges faster in run time with fewer observations than alternating minimization and GD in the noiseless scenario but also outperforms them in low-sample scenarios with noise.
Max-Linear Regression by Scalable and Guaranteed Convex Programming
Mar 12, 2021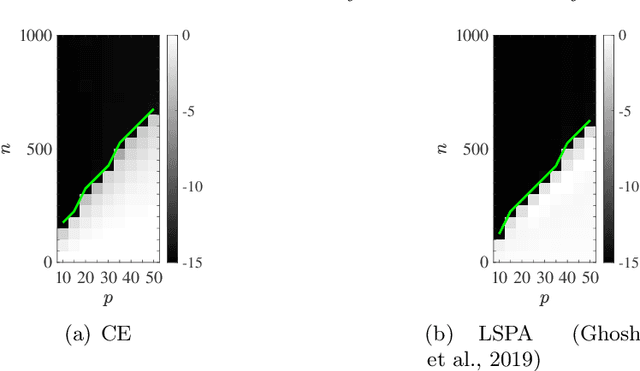
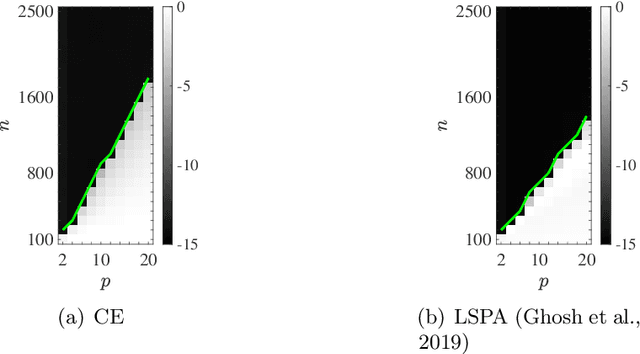
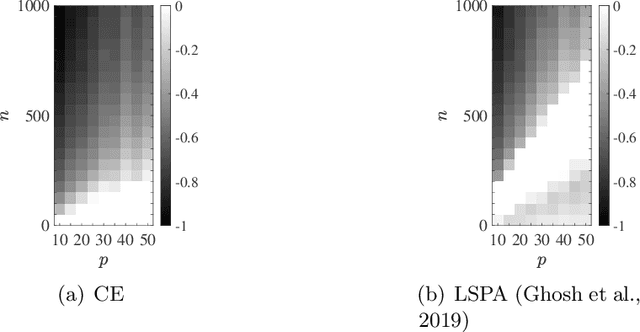
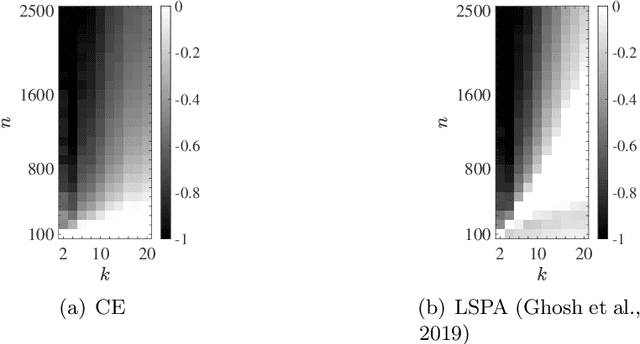
We consider the multivariate max-linear regression problem where the model parameters $\boldsymbol{\beta}_{1},\dotsc,\boldsymbol{\beta}_{k}\in\mathbb{R}^{p}$ need to be estimated from $n$ independent samples of the (noisy) observations $y = \max_{1\leq j \leq k} \boldsymbol{\beta}_{j}^{\mathsf{T}} \boldsymbol{x} + \mathrm{noise}$. The max-linear model vastly generalizes the conventional linear model, and it can approximate any convex function to an arbitrary accuracy when the number of linear models $k$ is large enough. However, the inherent nonlinearity of the max-linear model renders the estimation of the regression parameters computationally challenging. Particularly, no estimator based on convex programming is known in the literature. We formulate and analyze a scalable convex program as the estimator for the max-linear regression problem. Under the standard Gaussian observation setting, we present a non-asymptotic performance guarantee showing that the convex program recovers the parameters with high probability. When the $k$ linear components are equally likely to achieve the maximum, our result shows that a sufficient number of observations scales as $k^{2}p$ up to a logarithmic factor. This significantly improves on the analogous prior result based on alternating minimization (Ghosh et al., 2019). Finally, through a set of Monte Carlo simulations, we illustrate that our theoretical result is consistent with empirical behavior, and the convex estimator for max-linear regression is as competitive as the alternating minimization algorithm in practice.