 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaSeg: MetaFormer-based Global Contexts-aware Network for Efficient Semantic Segmentation
Aug 15, 2024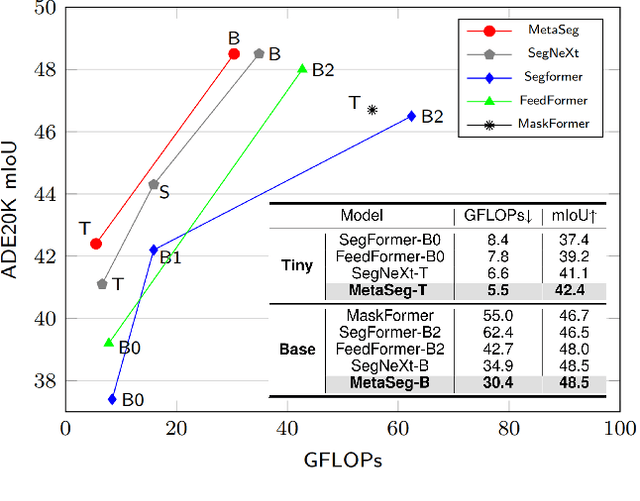
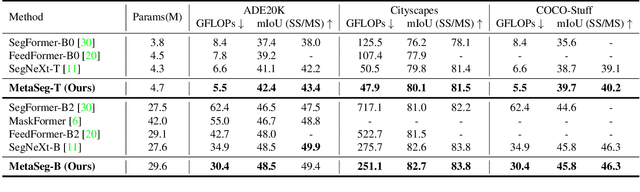
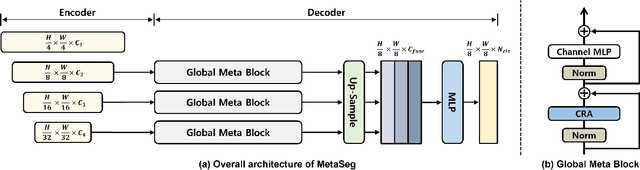
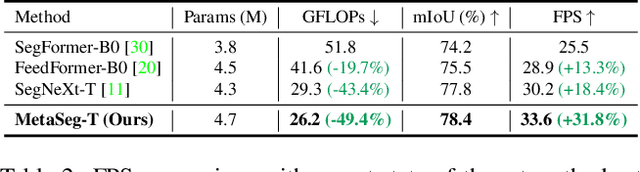
Beyond the Transformer, it is important to explore how to exploit the capacity of the MetaFormer, an architecture that is fundamental to the performance improvements of the Transformer. Previous studies have exploited it only for the backbone network. Unlike previous studies, we explore the capacity of the Metaformer architecture more extensively in the semantic segmentation task. We propose a powerful semantic segmentation network, MetaSeg, which leverages the Metaformer architecture from the backbone to the decoder. Our MetaSeg shows that the MetaFormer architecture plays a significant role in capturing the useful contexts for the decoder as well as for the backbone. In addition, recent segmentation methods have shown that using a CNN-based backbone for extracting the spatial information and a decoder for extracting the global information is more effective than using a transformer-based backbone with a CNN-based decoder. This motivates us to adopt the CNN-based backbone using the MetaFormer block and design our MetaFormer-based decoder, which consists of a novel self-attention module to capture the global contexts. To consider both the global contexts extraction and the computational efficiency of the self-attention for semantic segmentation, we propose a Channel Reduction Attention (CRA) module that reduces the channel dimension of the query and key into the one dimension. In this way, our proposed MetaSeg outperforms the previous state-of-the-art methods with more efficient computational costs on popular semantic segmentation and a medical image segmentation benchmark, including ADE20K, Cityscapes, COCO-stuff, and Synapse. The code is available at https://github.com/hyunwoo137/MetaSeg.
Embedding-Free Transformer with Inference Spatial Reduction for Efficient Semantic Segmentation
Jul 24, 2024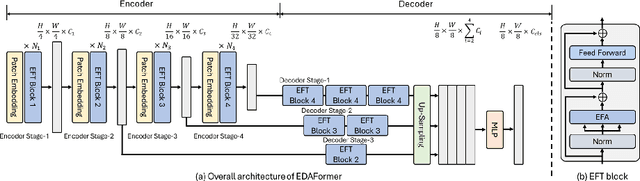
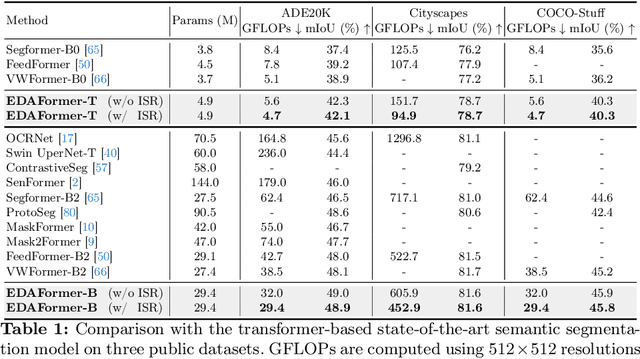
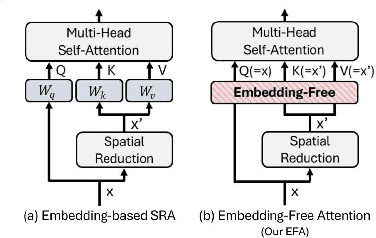
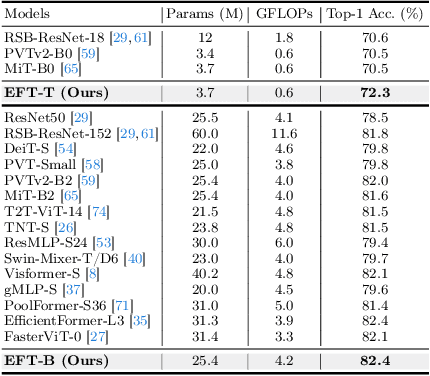
We present an Encoder-Decoder Attention Transformer, EDAFormer, which consists of the Embedding-Free Transformer (EFT) encoder and the all-attention decoder leveraging our Embedding-Free Attention (EFA) structure. The proposed EFA is a novel global context modeling mechanism that focuses on functioning the global non-linearity, not the specific roles of the query, key and value. For the decoder, we explore the optimized structure for considering the globality, which can improve the semantic segmentation performance. In addition, we propose a novel Inference Spatial Reduction (ISR) method for the computational efficiency. Different from the previous spatial reduction attention methods, our ISR method further reduces the key-value resolution at the inference phase, which can mitigate the computation-performance trade-off gap for the efficient semantic segmentation. Our EDAFormer shows the state-of-the-art performance with the efficient computation compared to the existing transformer-based semantic segmentation models in three public benchmarks, including ADE20K, Cityscapes and COCO-Stuff. Furthermore, our ISR method reduces the computational cost by up to 61% with minimal mIoU performance degradation on Cityscapes dataset. The code is available at https://github.com/hyunwoo137/EDAFormer.