 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Add $100 More: Augmenting NeRF-based Pseudo-LiDAR Point Cloud for Resolving Class-imbalance Problem
Paper and Code
Mar 20, 2024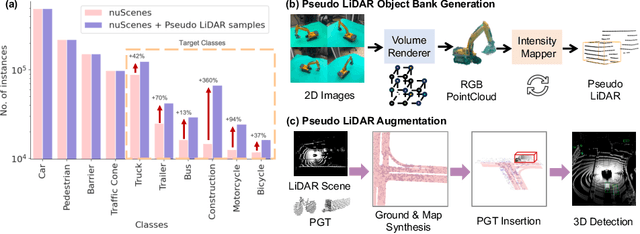
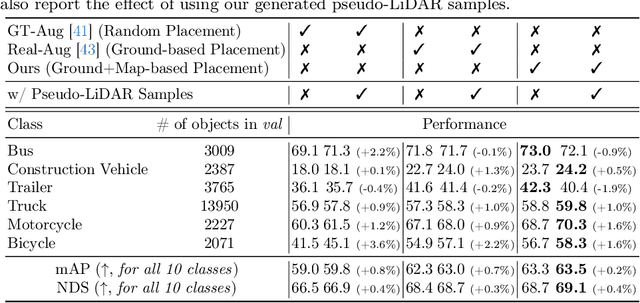
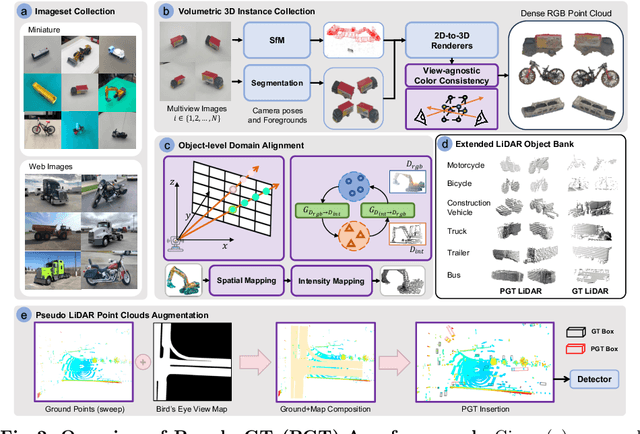
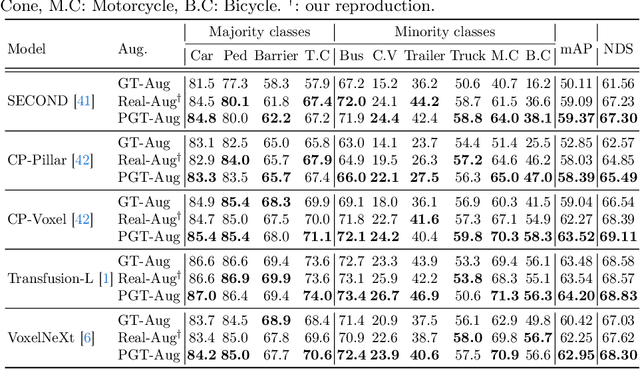
Typical LiDAR-based 3D object detection models are trained in a supervised manner with real-world data collection, which is often imbalanced over classes (or long-tailed). To deal with it, augmenting minority-class examples by sampling ground truth (GT) LiDAR points from a database and pasting them into a scene of interest is often used, but challenges still remain: inflexibility in locating GT samples and limited sample diversity. In this work, we propose to leverage pseudo-LiDAR point clouds generated (at a low cost) from videos capturing a surround view of miniatures or real-world objects of minor classes. Our method, called Pseudo Ground Truth Augmentation (PGT-Aug), consists of three main steps: (i) volumetric 3D instance reconstruction using a 2D-to-3D view synthesis model, (ii) object-level domain alignment with LiDAR intensity estimation and (iii) a hybrid context-aware placement method from ground and map information. We demonstrate the superiority and generality of our method through performance improvements in extensive experiments conducted on three popular benchmarks, i.e., nuScenes, KITTI, and Lyft, especially for the datasets with large domain gaps captured by different LiDAR configurations. Our code and data will be publicly available upon publication.