 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Product Search Relevance with EAR-MP: A Solution for the CIKM 2025 AnalytiCup
Oct 27, 2025Multilingual e-commerce search is challenging due to linguistic diversity and the noise inherent in user-generated queries. This paper documents the solution employed by our team (EAR-MP) for the CIKM 2025 AnalytiCup, which addresses two core tasks: Query-Category (QC) relevance and Query-Item (QI) relevance. Our approach first normalizes the multilingual dataset by translating all text into English, then mitigates noise through extensive data cleaning and normalization. For model training, we build on DeBERTa-v3-large and improve performance with label smoothing, self-distillation, and dropout. In addition, we introduce task-specific upgrades, including hierarchical token injection for QC and a hybrid scoring mechanism for QI. Under constrained compute, our method achieves competitive results, attaining an F1 score of 0.8796 on QC and 0.8744 on QI. These findings underscore the importance of systematic data preprocessing and tailored training strategies for building robust, resource-efficient multilingual relevance systems.
Toward a Better Understanding of Loss Functions for Collaborative Filtering
Aug 11, 2023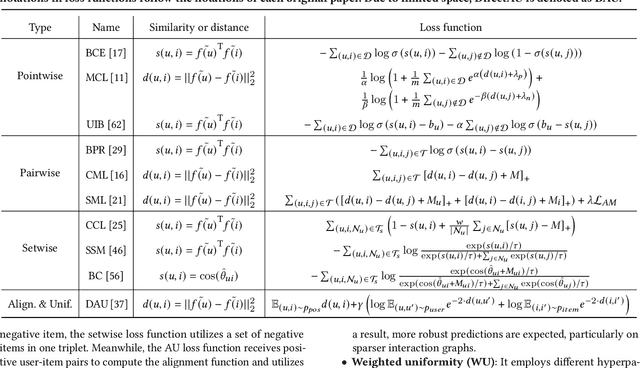
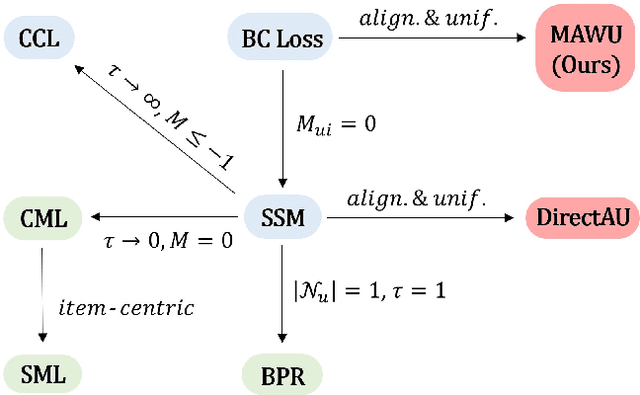
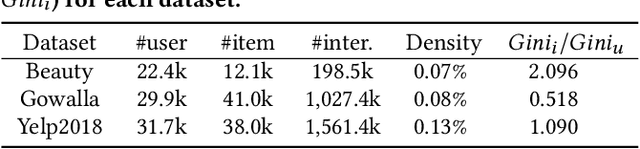
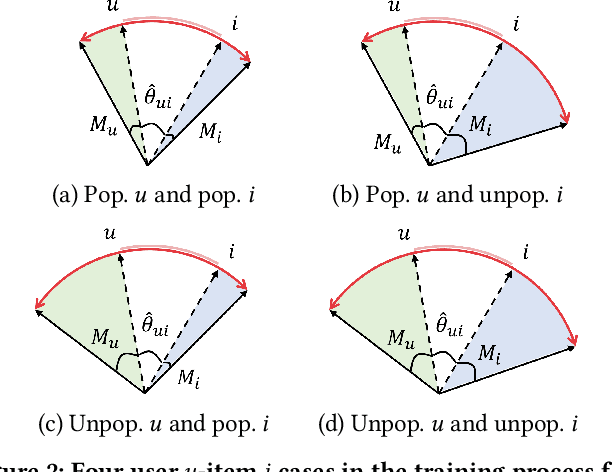
Collaborative filtering (CF) is a pivotal technique in modern recommender systems. The learning process of CF models typically consists of three components: interaction encoder, loss function, and negative sampling. Although many existing studies have proposed various CF models to design sophisticated interaction encoders, recent work shows that simply reformulating the loss functions can achieve significant performance gains. This paper delves into analyzing the relationship among existing loss functions. Our mathematical analysis reveals that the previous loss functions can be interpreted as alignment and uniformity functions: (i) the alignment matches user and item representations, and (ii) the uniformity disperses user and item distributions. Inspired by this analysis, we propose a novel loss function that improves the design of alignment and uniformity considering the unique patterns of datasets called Margin-aware Alignment and Weighted Uniformity (MAWU). The key novelty of MAWU is two-fold: (i) margin-aware alignment (MA) mitigates user/item-specific popularity biases, and (ii) weighted uniformity (WU) adjusts the significance between user and item uniformities to reflect the inherent characteristics of datasets. Extensive experimental results show that MF and LightGCN equipped with MAWU are comparable or superior to state-of-the-art CF models with various loss functions on three public datasets.
uCTRL: Unbiased Contrastive Representation Learning via Alignment and Uniformity for Collaborative Filtering
May 22, 2023Because implicit user feedback for the collaborative filtering (CF) models is biased toward popular items, CF models tend to yield recommendation lists with popularity bias. Previous studies have utilized inverse propensity weighting (IPW) or causal inference to mitigate this problem. However, they solely employ pointwise or pairwise loss functions and neglect to adopt a contrastive loss function for learning meaningful user and item representations. In this paper, we propose Unbiased ConTrastive Representation Learning (uCTRL), optimizing alignment and uniformity functions derived from the InfoNCE loss function for CF models. Specifically, we formulate an unbiased alignment function used in uCTRL. We also devise a novel IPW estimation method that removes the bias of both users and items. Despite its simplicity, uCTRL equipped with existing CF models consistently outperforms state-of-the-art unbiased recommender models, up to 12.22% for Recall@20 and 16.33% for NDCG@20 gains, on four benchmark datasets.
Bilateral Self-unbiased Learning from Biased Implicit Feedback
Jul 26, 2022

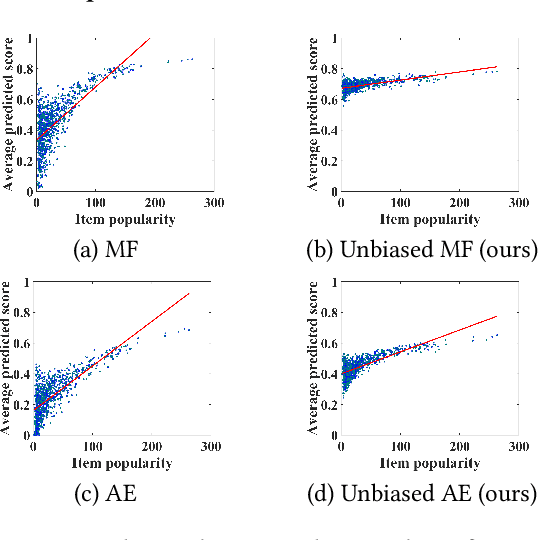

Implicit feedback has been widely used to build commercial recommender systems. Because observed feedback represents users' click logs, there is a semantic gap between true relevance and observed feedback. More importantly, observed feedback is usually biased towards popular items, thereby overestimating the actual relevance of popular items. Although existing studies have developed unbiased learning methods using inverse propensity weighting (IPW) or causal reasoning, they solely focus on eliminating the popularity bias of items. In this paper, we propose a novel unbiased recommender learning model, namely BIlateral SElf-unbiased Recommender (BISER), to eliminate the exposure bias of items caused by recommender models. Specifically, BISER consists of two key components: (i) self-inverse propensity weighting (SIPW) to gradually mitigate the bias of items without incurring high computational costs; and (ii) bilateral unbiased learning (BU) to bridge the gap between two complementary models in model predictions, i.e., user- and item-based autoencoders, alleviating the high variance of SIPW. Extensive experiments show that BISER consistently outperforms state-of-the-art unbiased recommender models over several datasets, including Coat, Yahoo! R3, MovieLens, and CiteULike.
Collaborative Distillation for Top-N Recommendation
Nov 13, 2019
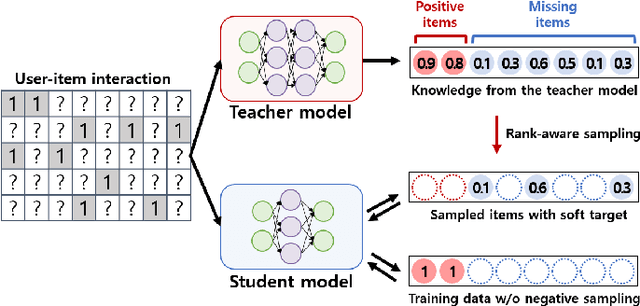
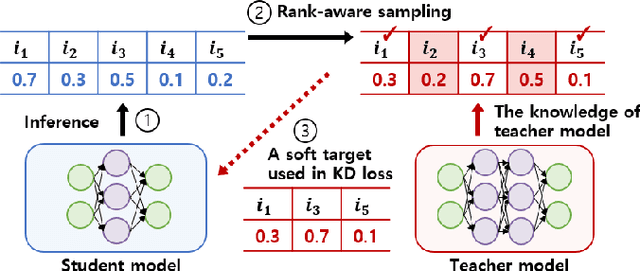
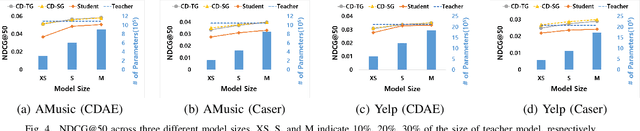
Knowledge distillation (KD) is a well-known method to reduce inference latency by compressing a cumbersome teacher model to a small student model. Despite the success of KD in the classification task, applying KD to recommender models is challenging due to the sparsity of positive feedback, the ambiguity of missing feedback, and the ranking problem associated with the top-N recommendation. To address the issues, we propose a new KD model for the collaborative filtering approach, namely collaborative distillation (CD). Specifically, (1) we reformulate a loss function to deal with the ambiguity of missing feedback. (2) We exploit probabilistic rank-aware sampling for the top-N recommendation. (3) To train the proposed model effectively, we develop two training strategies for the student model, called the teacher- and the student-guided training methods, selecting the most useful feedback from the teacher model. Via experimental results, we demonstrate that the proposed model outperforms the state-of-the-art method by 2.7-33.2% and 2.7-29.1% in hit rate (HR) and normalized discounted cumulative gain (NDCG), respectively. Moreover, the proposed model achieves the performance comparable to the teacher model.