 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Action: Generative Adversarial Synthesis from Language to Action
Oct 24, 2017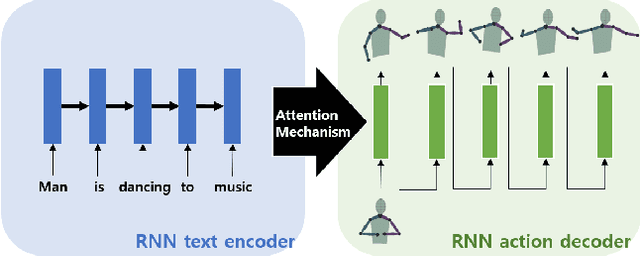



In this paper, we propose a generative model which learns the relationship between language and human action in order to generate a human action sequence given a sentence describing human behavior. The proposed generative model is a generative adversarial network (GAN), which is based on the sequence to sequence (SEQ2SEQ) model. Using the proposed generative network, we can synthesize various actions for a robot or a virtual agent using a text encoder recurrent neural network (RNN) and an action decoder RNN. The proposed generative network is trained from 29,770 pairs of actions and sentence annotations extracted from MSR-Video-to-Text (MSR-VTT), a large-scale video dataset. We demonstrate that the network can generate human-like actions which can be transferred to a Baxter robot, such that the robot performs an action based on a provided sentence. Results show that the proposed generative network correctly models the relationship between language and action and can generate a diverse set of actions from the same sentence.