 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRejuvenating image-GPT as Strong Visual Representation Learners
Paper and Code
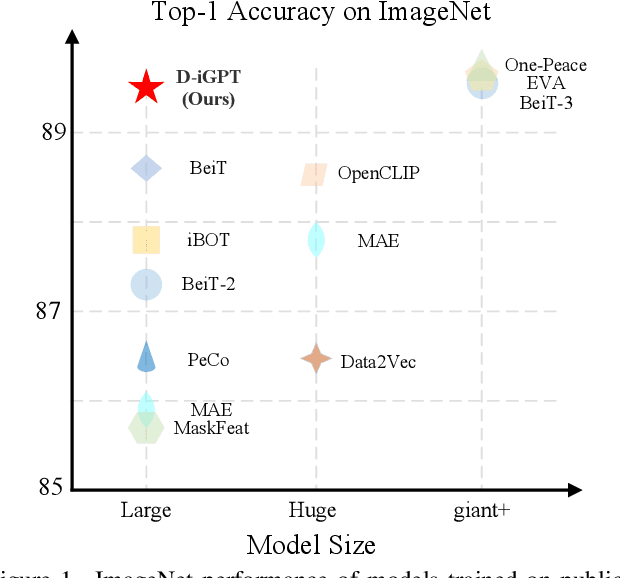
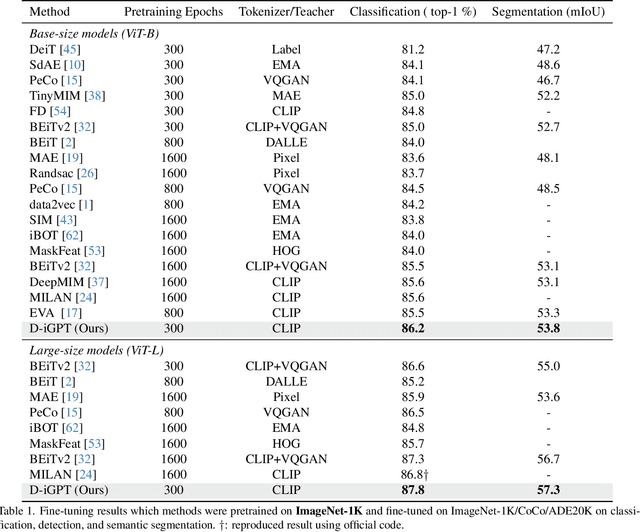
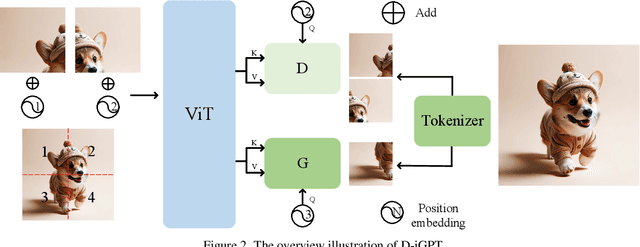
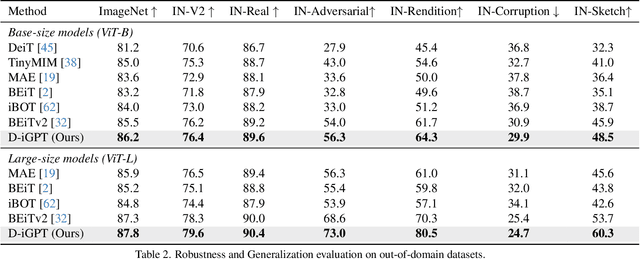
This paper enhances image-GPT (iGPT), one of the pioneering works that introduce autoregressive pretraining to predict next pixels for visual representation learning. Two simple yet essential changes are made. First, we shift the prediction target from raw pixels to semantic tokens, enabling a higher-level understanding of visual content. Second, we supplement the autoregressive modeling by instructing the model to predict not only the next tokens but also the visible tokens. This pipeline is particularly effective when semantic tokens are encoded by discriminatively trained models, such as CLIP. We introduce this novel approach as D-iGPT. Extensive experiments showcase that D-iGPT excels as a strong learner of visual representations: A notable achievement of D-iGPT is its compelling performance on the ImageNet-1K dataset -- by training on publicly available datasets, D-iGPT achieves 89.5\% top-1 accuracy with a vanilla ViT-Large model. This model also shows strong generalization on the downstream task and robustness on out-of-distribution samples. Code is avaiable at \href{https://github.com/OliverRensu/D-iGPT}{https://github.com/OliverRensu/D-iGPT}.