 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINT: Multimodal Imaging-to-Speech Knowledge Transfer for Early Alzheimer's Screening
Feb 27, 2026Alzheimer's disease is a progressive neurodegenerative disorder in which mild cognitive impairment (MCI) marks a critical transition between aging and dementia. Neuroimaging modalities, such as structural MRI, provide biomarkers of this transition; however, their high costs and infrastructure needs limit their deployment at a population scale. Speech analysis offers a non-invasive alternative, but speech-only classifiers are developed independently of neuroimaging, leaving decision boundaries biologically ungrounded and limiting reliability on the subtle CN-versus-MCI distinction. We propose MINT (Multimodal Imaging-to-Speech Knowledge Transfer), a three-stage cross-modal framework that transfers biomarker structure from MRI into a speech encoder at training time. An MRI teacher, trained on 1,228 subjects, defines a compact neuroimaging embedding space for CN-versus-MCI classification. A residual projection head aligns speech representations to this frozen imaging manifold via a combined geometric loss, adapting speech to the learned biomarker space while preserving imaging encoder fidelity. The frozen MRI classifier, which is never exposed to speech, is applied to aligned embeddings at inference and requires no scanner. Evaluation on ADNI-4 shows aligned speech achieves performance comparable to speech-only baselines (AUC 0.720 vs 0.711) while requiring no imaging at inference, demonstrating that MRI-derived decision boundaries can ground speech representations. Multimodal fusion improves over MRI alone (0.973 vs 0.958). Ablation studies identify dropout regularization and self-supervised pretraining as critical design decisions. To our knowledge, this is the first demonstration of MRI-to-speech knowledge transfer for early Alzheimer's screening, establishing a biologically grounded pathway for population-level cognitive triage without neuroimaging at inference.
A Unified Framework for EEG Seizure Detection Using Universum-Integrated Generalized Eigenvalues Proximal Support Vector Machine
Dec 24, 2025The paper presents novel Universum-enhanced classifiers: the Universum Generalized Eigenvalue Proximal Support Vector Machine (U-GEPSVM) and the Improved U-GEPSVM (IU-GEPSVM) for EEG signal classification. Using the computational efficiency of generalized eigenvalue decomposition and the generalization benefits of Universum learning, the proposed models address critical challenges in EEG analysis: non-stationarity, low signal-to-noise ratio, and limited labeled data. U-GEPSVM extends the GEPSVM framework by incorporating Universum constraints through a ratio-based objective function, while IU-GEPSVM enhances stability through a weighted difference-based formulation that provides independent control over class separation and Universum alignment. The models are evaluated on the Bonn University EEG dataset across two binary classification tasks: (O vs S)-healthy (eyes closed) vs seizure, and (Z vs S)-healthy (eyes open) vs seizure. IU-GEPSVM achieves peak accuracies of 85% (O vs S) and 80% (Z vs S), with mean accuracies of 81.29% and 77.57% respectively, outperforming baseline methods.
MAVEN: Multi-modal Attention for Valence-Arousal Emotion Network
Mar 16, 2025This paper introduces MAVEN (Multi-modal Attention for Valence-Arousal Emotion Network), a novel architecture for dynamic emotion recognition through dimensional modeling of affect. The model uniquely integrates visual, audio, and textual modalities via a bi-directional cross-modal attention mechanism with six distinct attention pathways, enabling comprehensive interactions between all modality pairs. Our proposed approach employs modality-specific encoders to extract rich feature representations from synchronized video frames, audio segments, and transcripts. The architecture's novelty lies in its cross-modal enhancement strategy, where each modality representation is refined through weighted attention from other modalities, followed by self-attention refinement through modality-specific encoders. Rather than directly predicting valence-arousal values, MAVEN predicts emotions in a polar coordinate form, aligning with psychological models of the emotion circumplex. Experimental evaluation on the Aff-Wild2 dataset demonstrates the effectiveness of our approach, with performance measured using Concordance Correlation Coefficient (CCC). The multi-stage architecture demonstrates superior ability to capture the complex, nuanced nature of emotional expressions in conversational videos, advancing the state-of-the-art (SOTA) in continuous emotion recognition in-the-wild. Code can be found at: https://github.com/Vrushank-Ahire/MAVEN_8th_ABAW.
Granular Ball K-Class Twin Support Vector Classifier
Dec 06, 2024



This paper introduces the Granular Ball K-Class Twin Support Vector Classifier (GB-TWKSVC), a novel multi-class classification framework that combines Twin Support Vector Machines (TWSVM) with granular ball computing. The proposed method addresses key challenges in multi-class classification by utilizing granular ball representation for improved noise robustness and TWSVM's non-parallel hyperplane architecture solves two smaller quadratic programming problems, enhancing efficiency. Our approach introduces a novel formulation that effectively handles multi-class scenarios, advancing traditional binary classification methods. Experimental evaluation on diverse benchmark datasets shows that GB-TWKSVC significantly outperforms current state-of-the-art classifiers in both accuracy and computational performance. The method's effectiveness is validated through comprehensive statistical tests and complexity analysis. Our work advances classification algorithms by providing a mathematically sound framework that addresses the scalability and robustness needs of modern machine learning applications. The results demonstrate GB-TWKSVC's broad applicability across domains including pattern recognition, fault diagnosis, and large-scale data analytics, establishing it as a valuable addition to the classification algorithm landscape.
MIP-GAF: A MLLM-annotated Benchmark for Most Important Person Localization and Group Context Understanding
Sep 10, 2024Estimating the Most Important Person (MIP) in any social event setup is a challenging problem mainly due to contextual complexity and scarcity of labeled data. Moreover, the causality aspects of MIP estimation are quite subjective and diverse. To this end, we aim to address the problem by annotating a large-scale `in-the-wild' dataset for identifying human perceptions about the `Most Important Person (MIP)' in an image. The paper provides a thorough description of our proposed Multimodal Large Language Model (MLLM) based data annotation strategy, and a thorough data quality analysis. Further, we perform a comprehensive benchmarking of the proposed dataset utilizing state-of-the-art MIP localization methods, indicating a significant drop in performance compared to existing datasets. The performance drop shows that the existing MIP localization algorithms must be more robust with respect to `in-the-wild' situations. We believe the proposed dataset will play a vital role in building the next-generation social situation understanding methods. The code and data is available at https://github.com/surbhimadan92/MIP-GAF.
Intuitionistic Fuzzy Generalized Eigenvalue Proximal Support Vector Machine
Aug 03, 2024Generalized eigenvalue proximal support vector machine (GEPSVM) has attracted widespread attention due to its simple architecture, rapid execution, and commendable performance. GEPSVM gives equal significance to all samples, thereby diminishing its robustness and efficacy when confronted with real-world datasets containing noise and outliers. In order to reduce the impact of noises and outliers, we propose a novel intuitionistic fuzzy generalized eigenvalue proximal support vector machine (IF-GEPSVM). The proposed IF-GEPSVM assigns the intuitionistic fuzzy score to each training sample based on its location and surroundings in the high-dimensional feature space by using a kernel function. The solution of the IF-GEPSVM optimization problem is obtained by solving a generalized eigenvalue problem. Further, we propose an intuitionistic fuzzy improved GEPSVM (IF-IGEPSVM) by solving the standard eigenvalue decomposition resulting in simpler optimization problems with less computation cost which leads to an efficient intuitionistic fuzzy-based model. We conduct a comprehensive evaluation of the proposed IF-GEPSVM and IF-IGEPSVM models on UCI and KEEL datasets. Moreover, to evaluate the robustness of the proposed IF-GEPSVM and IF-IGEPSVM models, label noise is introduced into some UCI and KEEL datasets. The experimental findings showcase the superior generalization performance of the proposed models when compared to the existing baseline models, both with and without label noise. Our experimental results, supported by rigorous statistical analyses, confirm the superior generalization abilities of the proposed IF-GEPSVM and IF-IGEPSVM models over the baseline models. Furthermore, we implement the proposed IF-GEPSVM and IF-IGEPSVM models on the USPS recognition dataset, yielding promising results that underscore the models' effectiveness in practical and real-world applications.
Graph Embedded Intuitionistic Fuzzy RVFL for Class Imbalance Learning
Jul 15, 2023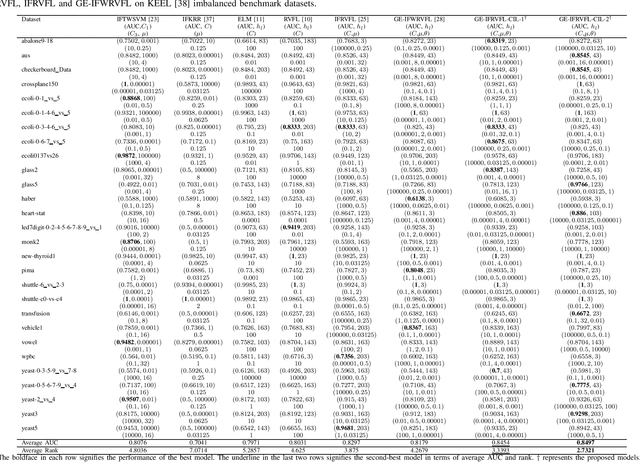

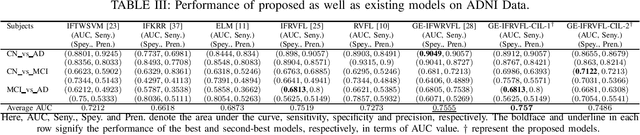
The domain of machine learning is confronted with a crucial research area known as class imbalance learning, which presents considerable hurdles in the precise classification of minority classes. This issue can result in biased models where the majority class takes precedence in the training process, leading to the underrepresentation of the minority class. The random vector functional link (RVFL) network is a widely-used and effective learning model for classification due to its speed and efficiency. However, it suffers from low accuracy when dealing with imbalanced datasets. To overcome this limitation, we propose a novel graph embedded intuitionistic fuzzy RVFL for class imbalance learning (GE-IFRVFL-CIL) model incorporating a weighting mechanism to handle imbalanced datasets. The proposed GE-IFRVFL-CIL model has a plethora of benefits, such as $(i)$ it leverages graph embedding to extract semantically rich information from the dataset, $(ii)$ it uses intuitionistic fuzzy sets to handle uncertainty and imprecision in the data, $(iii)$ and the most important, it tackles class imbalance learning. The amalgamation of a weighting scheme, graph embedding, and intuitionistic fuzzy sets leads to the superior performance of the proposed model on various benchmark imbalanced datasets, including UCI and KEEL. Furthermore, we implement the proposed GE-IFRVFL-CIL on the ADNI dataset and achieved promising results, demonstrating the model's effectiveness in real-world applications. The proposed method provides a promising solution for handling class imbalance in machine learning and has the potential to be applied to other classification problems.
Heterogeneous Oblique Double Random Forest
Apr 13, 2023



The decision tree ensembles use a single data feature at each node for splitting the data. However, splitting in this manner may fail to capture the geometric properties of the data. Thus, oblique decision trees generate the oblique hyperplane for splitting the data at each non-leaf node. Oblique decision trees capture the geometric properties of the data and hence, show better generalization. The performance of the oblique decision trees depends on the way oblique hyperplanes are generate and the data used for the generation of those hyperplanes. Recently, multiple classifiers have been used in a heterogeneous random forest (RaF) classifier, however, it fails to generate the trees of proper depth. Moreover, double RaF studies highlighted that larger trees can be generated via bootstrapping the data at each non-leaf node and splitting the original data instead of the bootstrapped data recently. The study of heterogeneous RaF lacks the generation of larger trees while as the double RaF based model fails to take over the geometric characteristics of the data. To address these shortcomings, we propose heterogeneous oblique double RaF. The proposed model employs several linear classifiers at each non-leaf node on the bootstrapped data and splits the original data based on the optimal linear classifier. The optimal hyperplane corresponds to the models based on the optimized impurity criterion. The experimental analysis indicates that the performance of the introduced heterogeneous double random forest is comparatively better than the baseline models. To demonstrate the effectiveness of the proposed heterogeneous double random forest, we used it for the diagnosis of Schizophrenia disease. The proposed model predicted the disease more accurately compared to the baseline models.
Deep Learning for Brain Age Estimation: A Systematic Review
Dec 07, 2022Over the years, Machine Learning models have been successfully employed on neuroimaging data for accurately predicting brain age. Deviations from the healthy brain aging pattern are associated to the accelerated brain aging and brain abnormalities. Hence, efficient and accurate diagnosis techniques are required for eliciting accurate brain age estimations. Several contributions have been reported in the past for this purpose, resorting to different data-driven modeling methods. Recently, deep neural networks (also referred to as deep learning) have become prevalent in manifold neuroimaging studies, including brain age estimation. In this review, we offer a comprehensive analysis of the literature related to the adoption of deep learning for brain age estimation with neuroimaging data. We detail and analyze different deep learning architectures used for this application, pausing at research works published to date quantitatively exploring their application. We also examine different brain age estimation frameworks, comparatively exposing their advantages and weaknesses. Finally, the review concludes with an outlook towards future directions that should be followed by prospective studies. The ultimate goal of this paper is to establish a common and informed reference for newcomers and experienced researchers willing to approach brain age estimation by using deep learning models
Diagnosis of Schizophrenia: A comprehensive evaluation
Mar 22, 2022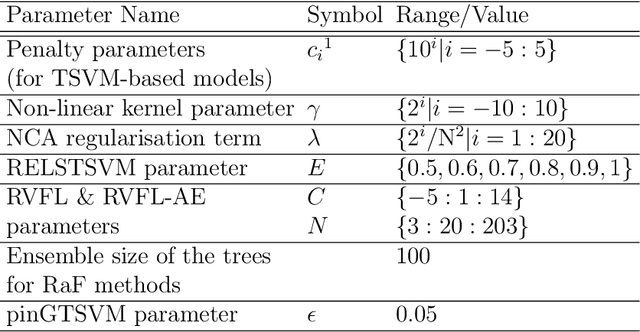
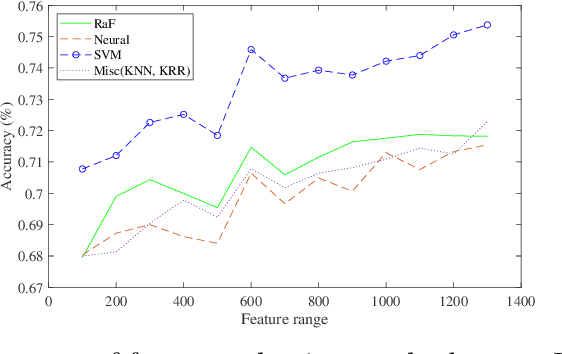
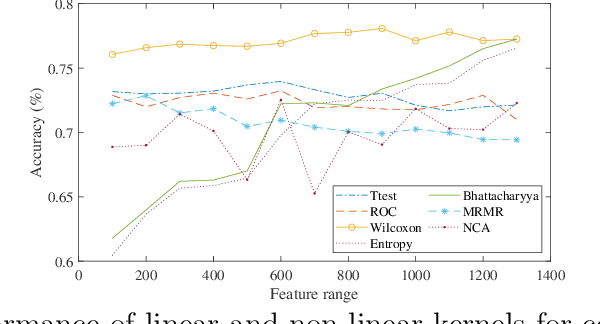
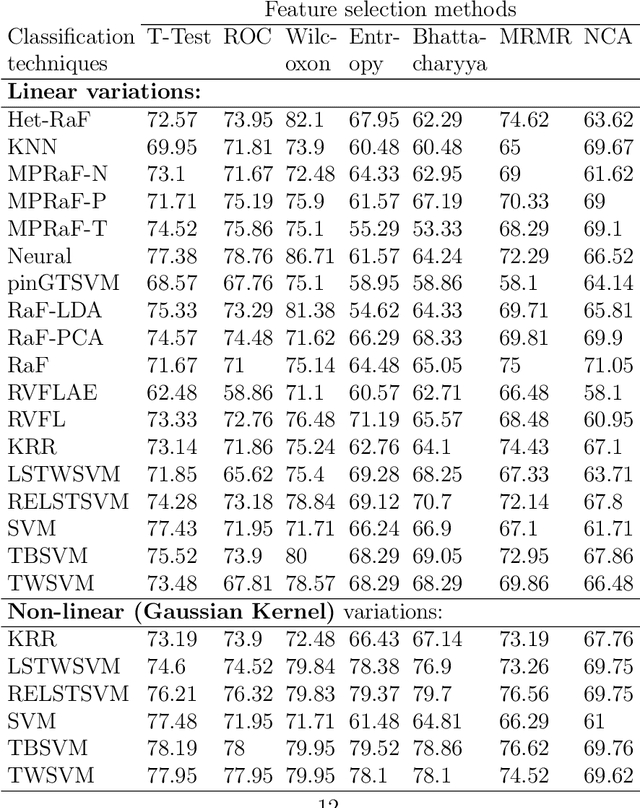
Machine learning models have been successfully employed in the diagnosis of Schizophrenia disease. The impact of classification models and the feature selection techniques on the diagnosis of Schizophrenia have not been evaluated. Here, we sought to access the performance of classification models along with different feature selection approaches on the structural magnetic resonance imaging data. The data consist of 72 subjects with Schizophrenia and 74 healthy control subjects. We evaluated different classification algorithms based on support vector machine (SVM), random forest, kernel ridge regression and randomized neural networks. Moreover, we evaluated T-Test, Receiver Operator Characteristics (ROC), Wilcoxon, entropy, Bhattacharyya, Minimum Redundancy Maximum Relevance (MRMR) and Neighbourhood Component Analysis (NCA) as the feature selection techniques. Based on the evaluation, SVM based models with Gaussian kernel proved better compared to other classification models and Wilcoxon feature selection emerged as the best feature selection approach. Moreover, in terms of data modality the performance on integration of the grey matter and white matter proved better compared to the performance on the grey and white matter individually. Our evaluation showed that classification algorithms along with the feature selection approaches impact the diagnosis of Schizophrenia disease. This indicates that proper selection of the features and the classification models can improve the diagnosis of Schizophrenia.