 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovement Graph Convolution Collaborative Filtering with Weighted addition input
Mar 27, 2025Graph Neural Networks have been extensively applied in the field of machine learning to find features of graphs, and recommendation systems are no exception. The ratings of users on considered items can be represented by graphs which are input for many efficient models to find out the characteristics of the users and the items. From these insights, relevant items are recommended to users. However, user's decisions on the items have varying degrees of effects on different users, and this information should be learned so as not to be lost in the process of information mining. In this publication, we propose to build an additional graph showing the recommended weight of an item to a target user to improve the accuracy of GNN models. Although the users' friendships were not recorded, their correlation was still evident through the commonalities in consumption behavior. We build a model WiGCN (Weighted input GCN) to describe and experiment on well-known datasets. Conclusions will be stated after comparing our results with state-of-the-art such as GCMC, NGCF and LightGCN. The source code is also included at https://github.com/trantin84/WiGCN.
Oblique and rotation double random forest
Nov 06, 2021
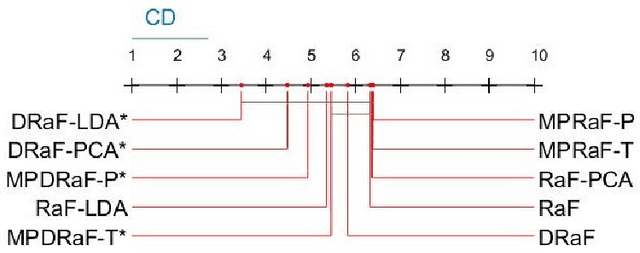

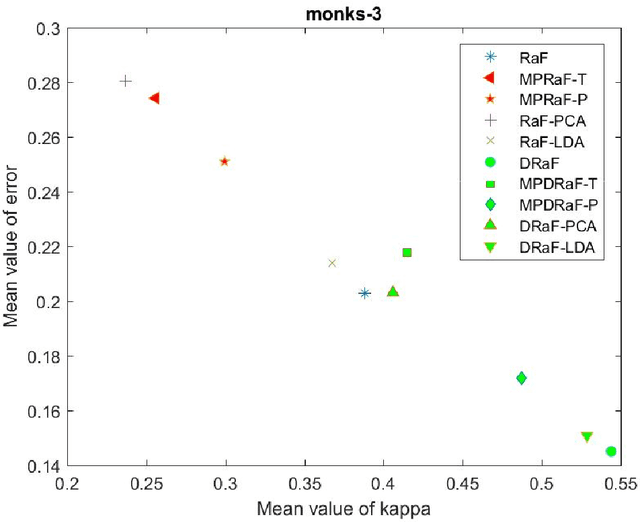
An ensemble of decision trees is known as Random Forest. As suggested by Breiman, the strength of unstable learners and the diversity among them are the ensemble models' core strength. In this paper, we propose two approaches known as oblique and rotation double random forests. In the first approach, we propose a rotation based double random forest. In rotation based double random forests, transformation or rotation of the feature space is generated at each node. At each node different random feature subspace is chosen for evaluation, hence the transformation at each node is different. Different transformations result in better diversity among the base learners and hence, better generalization performance. With the double random forest as base learner, the data at each node is transformed via two different transformations namely, principal component analysis and linear discriminant analysis. In the second approach, we propose oblique double random forest. Decision trees in random forest and double random forest are univariate, and this results in the generation of axis parallel split which fails to capture the geometric structure of the data. Also, the standard random forest may not grow sufficiently large decision trees resulting in suboptimal performance. To capture the geometric properties and to grow the decision trees of sufficient depth, we propose oblique double random forest. The oblique double random forest models are multivariate decision trees. At each non-leaf node, multisurface proximal support vector machine generates the optimal plane for better generalization performance. Also, different regularization techniques (Tikhonov regularisation and axis-parallel split regularisation) are employed for tackling the small sample size problems in the decision trees of oblique double random forest.