 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Body and Face Motion: Datasets, Performance Evaluation Metrics and Generative Techniques
Dec 09, 2025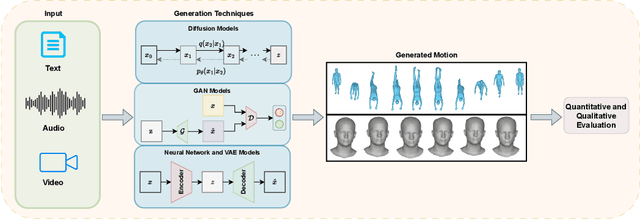
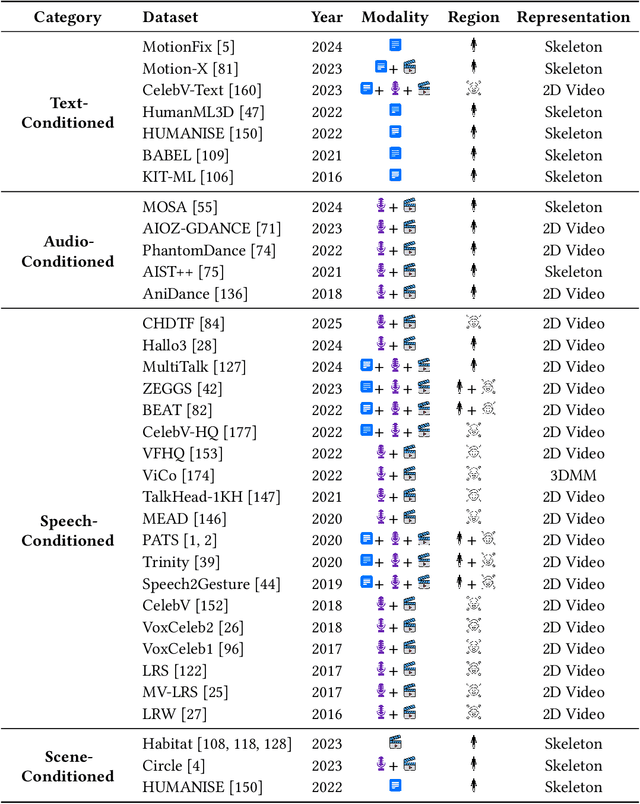
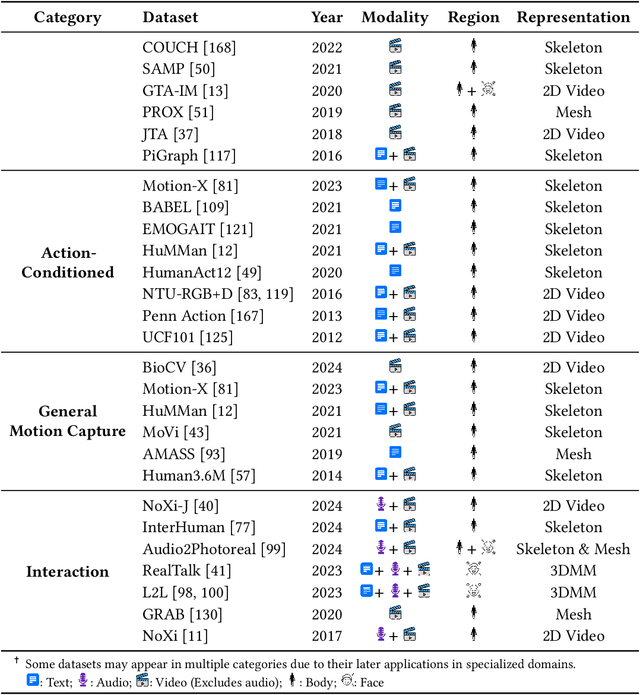

Body and face motion play an integral role in communication. They convey crucial information on the participants. Advances in generative modeling and multi-modal learning have enabled motion generation from signals such as speech, conversational context and visual cues. However, generating expressive and coherent face and body dynamics remains challenging due to the complex interplay of verbal / non-verbal cues and individual personality traits. This survey reviews body and face motion generation, covering core concepts, representations techniques, generative approaches, datasets and evaluation metrics. We highlight future directions to enhance the realism, coherence and expressiveness of avatars in dyadic settings. To the best of our knowledge, this work is the first comprehensive review to cover both body and face motion. Detailed resources are listed on https://lownish23csz0010.github.io/mogen/.
MAVEN: Multi-modal Attention for Valence-Arousal Emotion Network
Mar 16, 2025This paper introduces MAVEN (Multi-modal Attention for Valence-Arousal Emotion Network), a novel architecture for dynamic emotion recognition through dimensional modeling of affect. The model uniquely integrates visual, audio, and textual modalities via a bi-directional cross-modal attention mechanism with six distinct attention pathways, enabling comprehensive interactions between all modality pairs. Our proposed approach employs modality-specific encoders to extract rich feature representations from synchronized video frames, audio segments, and transcripts. The architecture's novelty lies in its cross-modal enhancement strategy, where each modality representation is refined through weighted attention from other modalities, followed by self-attention refinement through modality-specific encoders. Rather than directly predicting valence-arousal values, MAVEN predicts emotions in a polar coordinate form, aligning with psychological models of the emotion circumplex. Experimental evaluation on the Aff-Wild2 dataset demonstrates the effectiveness of our approach, with performance measured using Concordance Correlation Coefficient (CCC). The multi-stage architecture demonstrates superior ability to capture the complex, nuanced nature of emotional expressions in conversational videos, advancing the state-of-the-art (SOTA) in continuous emotion recognition in-the-wild. Code can be found at: https://github.com/Vrushank-Ahire/MAVEN_8th_ABAW.
MIP-GAF: A MLLM-annotated Benchmark for Most Important Person Localization and Group Context Understanding
Sep 10, 2024Estimating the Most Important Person (MIP) in any social event setup is a challenging problem mainly due to contextual complexity and scarcity of labeled data. Moreover, the causality aspects of MIP estimation are quite subjective and diverse. To this end, we aim to address the problem by annotating a large-scale `in-the-wild' dataset for identifying human perceptions about the `Most Important Person (MIP)' in an image. The paper provides a thorough description of our proposed Multimodal Large Language Model (MLLM) based data annotation strategy, and a thorough data quality analysis. Further, we perform a comprehensive benchmarking of the proposed dataset utilizing state-of-the-art MIP localization methods, indicating a significant drop in performance compared to existing datasets. The performance drop shows that the existing MIP localization algorithms must be more robust with respect to `in-the-wild' situations. We believe the proposed dataset will play a vital role in building the next-generation social situation understanding methods. The code and data is available at https://github.com/surbhimadan92/MIP-GAF.