 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context with Discrete Diffusion in Vector Quantised Modelling for Image Generation
Paper and Code
Dec 03, 2021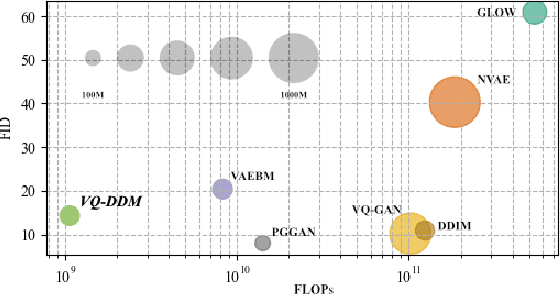
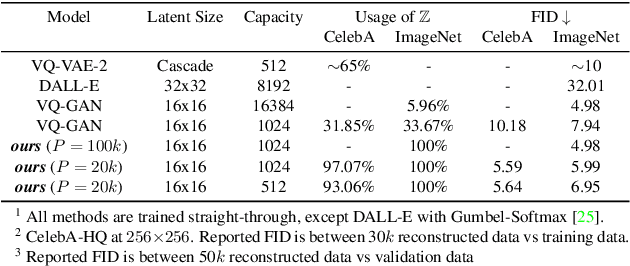
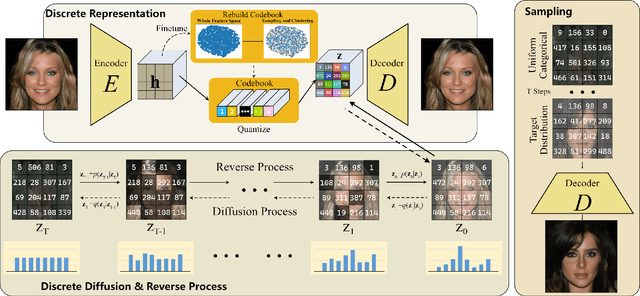
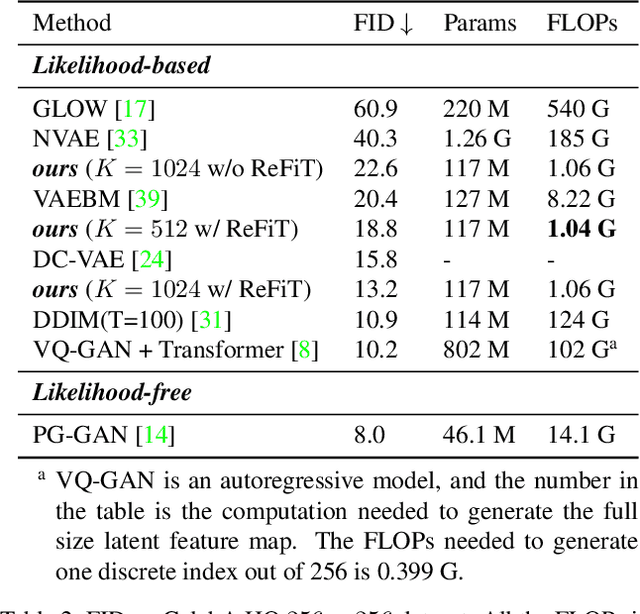
The integration of Vector Quantised Variational AutoEncoder (VQ-VAE) with autoregressive models as generation part has yielded high-quality results on image generation. However, the autoregressive models will strictly follow the progressive scanning order during the sampling phase. This leads the existing VQ series models to hardly escape the trap of lacking global information. Denoising Diffusion Probabilistic Models (DDPM) in the continuous domain have shown a capability to capture the global context, while generating high-quality images. In the discrete state space, some works have demonstrated the potential to perform text generation and low resolution image generation. We show that with the help of a content-rich discrete visual codebook from VQ-VAE, the discrete diffusion model can also generate high fidelity images with global context, which compensates for the deficiency of the classical autoregressive model along pixel space. Meanwhile, the integration of the discrete VAE with the diffusion model resolves the drawback of conventional autoregressive models being oversized, and the diffusion model which demands excessive time in the sampling process when generating images. It is found that the quality of the generated images is heavily dependent on the discrete visual codebook. Extensive experiments demonstrate that the proposed Vector Quantised Discrete Diffusion Model (VQ-DDM) is able to achieve comparable performance to top-tier methods with low complexity. It also demonstrates outstanding advantages over other vectors quantised with autoregressive models in terms of image inpainting tasks without additional training.