 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSc-V2: Zero-Shot Multimodal Industrial Anomaly Classification and Segmentation with Mutual Scoring of Unlabeled Samples
Nov 13, 2025Zero-shot anomaly classification (AC) and segmentation (AS) methods aim to identify and outline defects without using any labeled samples. In this paper, we reveal a key property that is overlooked by existing methods: normal image patches across industrial products typically find many other similar patches, not only in 2D appearance but also in 3D shapes, while anomalies remain diverse and isolated. To explicitly leverage this discriminative property, we propose a Mutual Scoring framework (MuSc-V2) for zero-shot AC/AS, which flexibly supports single 2D/3D or multimodality. Specifically, our method begins by improving 3D representation through Iterative Point Grouping (IPG), which reduces false positives from discontinuous surfaces. Then we use Similarity Neighborhood Aggregation with Multi-Degrees (SNAMD) to fuse 2D/3D neighborhood cues into more discriminative multi-scale patch features for mutual scoring. The core comprises a Mutual Scoring Mechanism (MSM) that lets samples within each modality to assign score to each other, and Cross-modal Anomaly Enhancement (CAE) that fuses 2D and 3D scores to recover modality-specific missing anomalies. Finally, Re-scoring with Constrained Neighborhood (RsCon) suppresses false classification based on similarity to more representative samples. Our framework flexibly works on both the full dataset and smaller subsets with consistently robust performance, ensuring seamless adaptability across diverse product lines. In aid of the novel framework, MuSc-V2 achieves significant performance improvements: a $\textbf{+23.7\%}$ AP gain on the MVTec 3D-AD dataset and a $\textbf{+19.3\%}$ boost on the Eyecandies dataset, surpassing previous zero-shot benchmarks and even outperforming most few-shot methods. The code will be available at The code will be available at \href{https://github.com/HUST-SLOW/MuSc-V2}{https://github.com/HUST-SLOW/MuSc-V2}.
RoBiS: Robust Binary Segmentation for High-Resolution Industrial Images
May 27, 2025Robust unsupervised anomaly detection (AD) in real-world scenarios is an important task. Current methods exhibit severe performance degradation on the MVTec AD 2 benchmark due to its complex real-world challenges. To solve this problem, we propose a robust framework RoBiS, which consists of three core modules: (1) Swin-Cropping, a high-resolution image pre-processing strategy to preserve the information of small anomalies through overlapping window cropping. (2) The data augmentation of noise addition and lighting simulation is carried out on the training data to improve the robustness of AD model. We use INP-Former as our baseline, which could generate better results on the various sub-images. (3) The traditional statistical-based binarization strategy (mean+3std) is combined with our previous work, MEBin (published in CVPR2025), for joint adaptive binarization. Then, SAM is further employed to refine the segmentation results. Compared with some methods reported by the MVTec AD 2, our RoBiS achieves a 29.2% SegF1 improvement (from 21.8% to 51.00%) on Test_private and 29.82% SegF1 gains (from 16.7% to 46.52%) on Test_private_mixed. Code is available at https://github.com/xrli-U/RoBiS.
Intelligent Anti-Money Laundering Solution Based upon Novel Community Detection in Massive Transaction Networks on Spark
Jan 08, 2025Criminals are using every means available to launder the profits from their illegal activities into ostensibly legitimate assets. Meanwhile, most commercial anti-money laundering systems are still rule-based, which cannot adapt to the ever-changing tricks. Although some machine learning methods have been proposed, they are mainly focused on the perspective of abnormal behavior for single accounts. Considering money laundering activities are often involved in gang criminals, these methods are still not intelligent enough to crack down on criminal gangs all-sidedly. In this paper, a systematic solution is presented to find suspicious money laundering gangs. A temporal-directed Louvain algorithm has been proposed to detect communities according to relevant anti-money laundering patterns. All processes are implemented and optimized on Spark platform. This solution can greatly improve the efficiency of anti-money laundering work for financial regulation agencies.
Heterogeneous Graph Pre-training Based Model for Secure and Efficient Prediction of Default Risk Propagation among Bond Issuers
Jan 04, 2025

Efficient prediction of default risk for bond-issuing enterprises is pivotal for maintaining stability and fostering growth in the bond market. Conventional methods usually rely solely on an enterprise's internal data for risk assessment. In contrast, graph-based techniques leverage interconnected corporate information to enhance default risk identification for targeted bond issuers. Traditional graph techniques such as label propagation algorithm or deepwalk fail to effectively integrate a enterprise's inherent attribute information with its topological network data. Additionally, due to data scarcity and security privacy concerns between enterprises, end-to-end graph neural network (GNN) algorithms may struggle in delivering satisfactory performance for target tasks. To address these challenges, we present a novel two-stage model. In the first stage, we employ an innovative Masked Autoencoders for Heterogeneous Graph (HGMAE) to pre-train on a vast enterprise knowledge graph. Subsequently, in the second stage, a specialized classifier model is trained to predict default risk propagation probabilities. The classifier leverages concatenated feature vectors derived from the pre-trained encoder with the enterprise's task-specific feature vectors. Through the two-stage training approach, our model not only boosts the importance of unique bond characteristics for specific default prediction tasks, but also securely and efficiently leverage the global information pre-trained from other enterprises. Experimental results demonstrate that our proposed model outperforms existing approaches in predicting default risk for bond issuers.
SeaS: Few-shot Industrial Anomaly Image Generation with Separation and Sharing Fine-tuning
Oct 19, 2024



Current segmentation methods require many training images and precise masks, while insufficient anomaly images hinder their application in industrial scenarios. To address such an issue, we explore producing diverse anomalies and accurate pixel-wise annotations. By observing the real production lines, we find that anomalies vary randomly in shape and appearance, whereas products hold globally consistent patterns with slight local variations. Such a characteristic inspires us to develop a Separation and Sharing Fine-tuning (SeaS) approach using only a few abnormal and some normal images. Firstly, we propose the Unbalanced Abnormal (UA) Text Prompt tailored to industrial anomaly generation, consisting of one product token and several anomaly tokens. Then, for anomaly images, we propose a Decoupled Anomaly Alignment (DA) loss to bind the attributes of the anomalies to different anomaly tokens. Re-blending such attributes may produce never-seen anomalies, achieving a high diversity of anomalies. For normal images, we propose a Normal-image Alignment (NA) loss to learn the products' key features that are used to synthesize products with both global consistency and local variations. The two training processes are separated but conducted on a shared U-Net. Finally, SeaS produces high-fidelity annotations for the generated anomalies by fusing discriminative features of U-Net and high-resolution VAE features. Extensive evaluations on the challenging MVTec AD and MVTec 3D AD dataset demonstrate the effectiveness of our approach. For anomaly image generation, we achieve 1.88 on IS and 0.34 on IC-LPIPS on MVTec AD dataset, 1.95 on IS and 0.30 on IC-LPIPS on MVTec 3D AD dataset. For downstream task, using our generated anomaly image-mask pairs, three common segmentation methods achieve an average 11.17% improvement on IoU on MVTec AD dataset, and a 15.49% enhancement in IoU on MVTec 3D AD dataset.
AnomalyNCD: Towards Novel Anomaly Class Discovery in Industrial Scenarios
Oct 18, 2024



In the industrial scenario, anomaly detection could locate but cannot classify anomalies. To complete their capability, we study to automatically discover and recognize visual classes of industrial anomalies. In terms of multi-class anomaly classification, previous methods cluster anomalies represented by frozen pre-trained models but often fail due to poor discrimination. Novel class discovery (NCD) has the potential to tackle this. However, it struggles with non-prominent and semantically weak anomalies that challenge network learning focus. To address these, we introduce AnomalyNCD, a multi-class anomaly classification framework compatible with existing anomaly detection methods. This framework learns anomaly-specific features and classifies anomalies in a self-supervised manner. Initially, a technique called Main Element Binarization (MEBin) is first designed, which segments primary anomaly regions into masks to alleviate the impact of incorrect detections on learning. Subsequently, we employ mask-guided contrastive representation learning to improve feature discrimination, which focuses network attention on isolated anomalous regions and reduces the confusion of erroneous inputs through re-corrected pseudo labels. Finally, to enable flexible classification at both region and image levels during inference, we develop a region merging strategy that determines the overall image category based on the classified anomaly regions. Our method outperforms the state-of-the-art works on the MVTec AD and MTD datasets. Compared with the current methods, AnomalyNCD combined with zero-shot anomaly detection method achieves a 10.8% $F_1$ gain, 8.8% NMI gain, and 9.5% ARI gain on MVTec AD, 12.8% $F_1$ gain, 5.7% NMI gain, and 10.8% ARI gain on MTD. The source code is available at https://github.com/HUST-SLOW/AnomalyNCD.
A Speaker Turn-Aware Multi-Task Adversarial Network for Joint User Satisfaction Estimation and Sentiment Analysis
Oct 12, 2024



User Satisfaction Estimation is an important task and increasingly being applied in goal-oriented dialogue systems to estimate whether the user is satisfied with the service. It is observed that whether the user's needs are met often triggers various sentiments, which can be pertinent to the successful estimation of user satisfaction, and vice versa. Thus, User Satisfaction Estimation (USE) and Sentiment Analysis (SA) should be treated as a joint, collaborative effort, considering the strong connections between the sentiment states of speakers and the user satisfaction. Existing joint learning frameworks mainly unify the two highly pertinent tasks over cascade or shared-bottom implementations, however they fail to distinguish task-specific and common features, which will produce sub-optimal utterance representations for downstream tasks. In this paper, we propose a novel Speaker Turn-Aware Multi-Task Adversarial Network (STMAN) for dialogue-level USE and utterance-level SA. Specifically, we first introduce a multi-task adversarial strategy which trains a task discriminator to make utterance representation more task-specific, and then utilize a speaker-turn aware multi-task interaction strategy to extract the common features which are complementary to each task. Extensive experiments conducted on two real-world service dialogue datasets show that our model outperforms several state-of-the-art methods.
AT-MoE: Adaptive Task-planning Mixture of Experts via LoRA Approach
Oct 12, 2024The advent of Large Language Models (LLMs) has ushered in a new era of artificial intelligence, with the potential to transform various sectors through automation and insightful analysis. The Mixture of Experts (MoE) architecture has been proposed as a solution to enhance model performance in complex tasks. Yet, existing MoE models struggle with task-specific learning and interpretability, especially in fields like medicine where precision is critical. This paper introduces the Adaptive Task-planing Mixture of Experts(AT-MoE), an innovative architecture designed to address these limitations. We first train task-specific experts via LoRA approach to enhance problem-solving capabilities and interpretability in specialized areas. Subsequently, we introduce a layer-wise adaptive grouped routing module that optimizes module fusion based on complex task instructions, ensuring optimal task resolution. The grouped routing module first perform overall weight allocation from the dimension of the expert group, and then conduct local weight normalization adjustments within the group. This design maintains multi-dimensional balance, controllability, and interpretability, while facilitating task-specific fusion in response to complex instructions.
MuSc: Zero-Shot Industrial Anomaly Classification and Segmentation with Mutual Scoring of the Unlabeled Images
Jan 30, 2024



This paper studies zero-shot anomaly classification (AC) and segmentation (AS) in industrial vision. We reveal that the abundant normal and abnormal cues implicit in unlabeled test images can be exploited for anomaly determination, which is ignored by prior methods. Our key observation is that for the industrial product images, the normal image patches could find a relatively large number of similar patches in other unlabeled images, while the abnormal ones only have a few similar patches. We leverage such a discriminative characteristic to design a novel zero-shot AC/AS method by Mutual Scoring (MuSc) of the unlabeled images, which does not need any training or prompts. Specifically, we perform Local Neighborhood Aggregation with Multiple Degrees (LNAMD) to obtain the patch features that are capable of representing anomalies in varying sizes. Then we propose the Mutual Scoring Mechanism (MSM) to leverage the unlabeled test images to assign the anomaly score to each other. Furthermore, we present an optimization approach named Re-scoring with Constrained Image-level Neighborhood (RsCIN) for image-level anomaly classification to suppress the false positives caused by noises in normal images. The superior performance on the challenging MVTec AD and VisA datasets demonstrates the effectiveness of our approach. Compared with the state-of-the-art zero-shot approaches, MuSc achieves a $\textbf{21.1%}$ PRO absolute gain (from 72.7% to 93.8%) on MVTec AD, a $\textbf{19.4%}$ pixel-AP gain and a $\textbf{14.7%}$ pixel-AUROC gain on VisA. In addition, our zero-shot approach outperforms most of the few-shot approaches and is comparable to some one-class methods. Code is available at https://github.com/xrli-U/MuSc.
Towards Human-like Perception: Learning Structural Causal Model in Heterogeneous Graph
Dec 10, 2023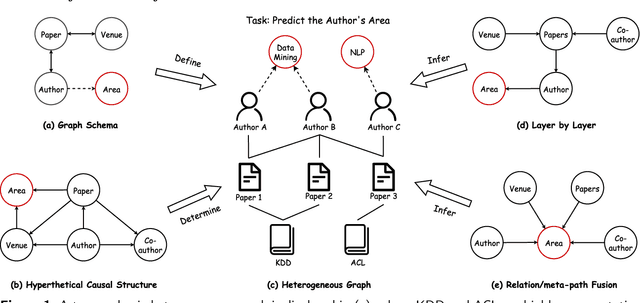
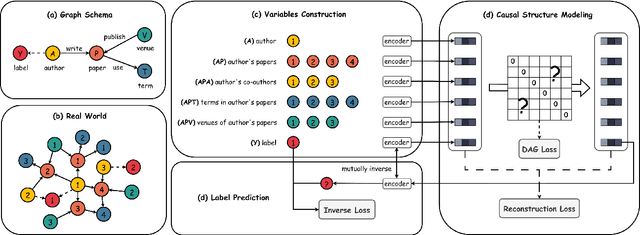

Heterogeneous graph neural networks have become popular in various domains. However, their generalizability and interpretability are limited due to the discrepancy between their inherent inference flows and human reasoning logic or underlying causal relationships for the learning problem. This study introduces a novel solution, HG-SCM (Heterogeneous Graph as Structural Causal Model). It can mimic the human perception and decision process through two key steps: constructing intelligible variables based on semantics derived from the graph schema and automatically learning task-level causal relationships among these variables by incorporating advanced causal discovery techniques. We compared HG-SCM to seven state-of-the-art baseline models on three real-world datasets, under three distinct and ubiquitous out-of-distribution settings. HG-SCM achieved the highest average performance rank with minimal standard deviation, substantiating its effectiveness and superiority in terms of both predictive power and generalizability. Additionally, the visualization and analysis of the auto-learned causal diagrams for the three tasks aligned well with domain knowledge and human cognition, demonstrating prominent interpretability. HG-SCM's human-like nature and its enhanced generalizability and interpretability make it a promising solution for special scenarios where transparency and trustworthiness are paramount.
* 28 pages, 10 figures, 6 tables, accepted by Information Processing & Management