 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Representation Learning for Unified Online Top-K Recommendation
Oct 24, 2023



In large-scale industrial e-commerce, the efficiency of an online recommendation system is crucial in delivering highly relevant item/content advertising that caters to diverse business scenarios. However, most existing studies focus solely on item advertising, neglecting the significance of content advertising. This oversight results in inconsistencies within the multi-entity structure and unfair retrieval. Furthermore, the challenge of retrieving top-k advertisements from multi-entity advertisements across different domains adds to the complexity. Recent research proves that user-entity behaviors within different domains exhibit characteristics of differentiation and homogeneity. Therefore, the multi-domain matching models typically rely on the hybrid-experts framework with domain-invariant and domain-specific representations. Unfortunately, most approaches primarily focus on optimizing the combination mode of different experts, failing to address the inherent difficulty in optimizing the expert modules themselves. The existence of redundant information across different domains introduces interference and competition among experts, while the distinct learning objectives of each domain lead to varying optimization challenges among experts. To tackle these issues, we propose robust representation learning for the unified online top-k recommendation. Our approach constructs unified modeling in entity space to ensure data fairness. The robust representation learning employs domain adversarial learning and multi-view wasserstein distribution learning to learn robust representations. Moreover, the proposed method balances conflicting objectives through the homoscedastic uncertainty weights and orthogonality constraints. Various experiments validate the effectiveness and rationality of our proposed method, which has been successfully deployed online to serve real business scenarios.
Adaptive Domain Interest Network for Multi-domain Recommendation
Jun 20, 2022


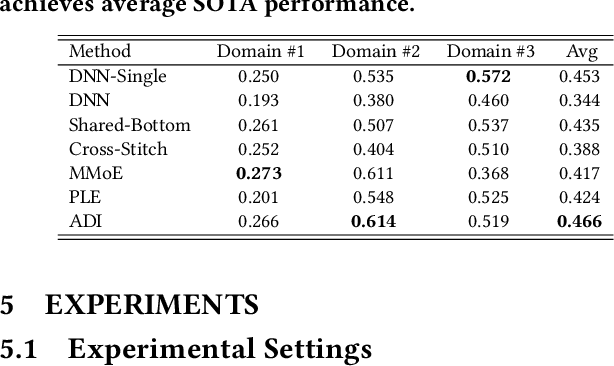
Industrial recommender systems usually hold data from multiple business scenarios and are expected to provide recommendation services for these scenarios simultaneously. In the retrieval step, the topK high-quality items selected from a large number of corpus usually need to be various for multiple scenarios. Take Alibaba display advertising system for example, not only because the behavior patterns of Taobao users are diverse, but also differentiated scenarios' bid prices assigned by advertisers vary significantly. Traditional methods either train models for each scenario separately, ignoring the cross-domain overlapping of user groups and items, or simply mix all samples and maintain a shared model which makes it difficult to capture significant diversities between scenarios. In this paper, we present Adaptive Domain Interest network that adaptively handles the commonalities and diversities across scenarios, making full use of multi-scenarios data during training. Then the proposed method is able to improve the performance of each business domain by giving various topK candidates for different scenarios during online inference. Specifically, our proposed ADI models the commonalities and diversities for different domains by shared networks and domain-specific networks, respectively. In addition, we apply the domain-specific batch normalization and design the domain interest adaptation layer for feature-level domain adaptation. A self training strategy is also incorporated to capture label-level connections across domains.ADI has been deployed in the display advertising system of Alibaba, and obtains 1.8% improvement on advertising revenue.
Construct Informative Triplet with Two-stage Hard-sample Generation
Dec 04, 2021In this paper, we propose a robust sample generation scheme to construct informative triplets. The proposed hard sample generation is a two-stage synthesis framework that produces hard samples through effective positive and negative sample generators in two stages, respectively. The first stage stretches the anchor-positive pairs with piecewise linear manipulation and enhances the quality of generated samples by skillfully designing a conditional generative adversarial network to lower the risk of mode collapse. The second stage utilizes an adaptive reverse metric constraint to generate the final hard samples. Extensive experiments on several benchmark datasets verify that our method achieves superior performance than the existing hard-sample generation algorithms. Besides, we also find that our proposed hard sample generation method combining the existing triplet mining strategies can further boost the deep metric learning performance.