 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Generation of Long Text
Paper and Code
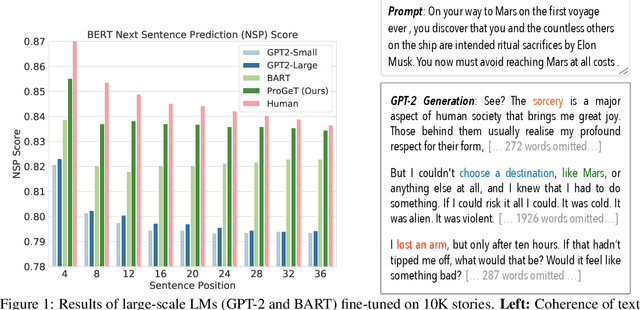
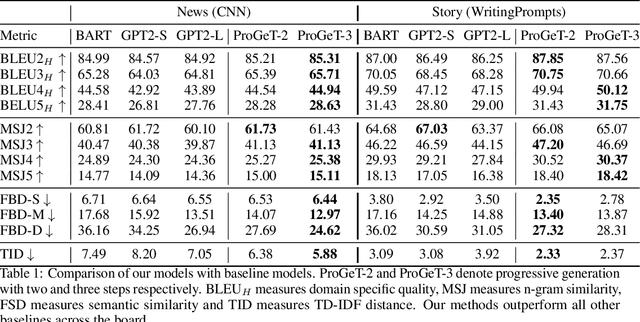
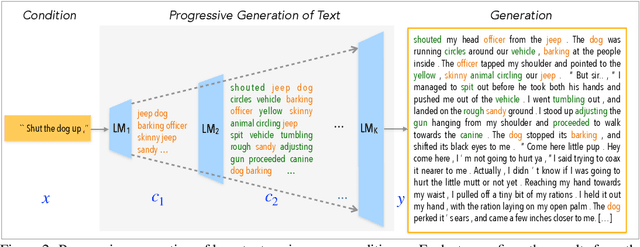
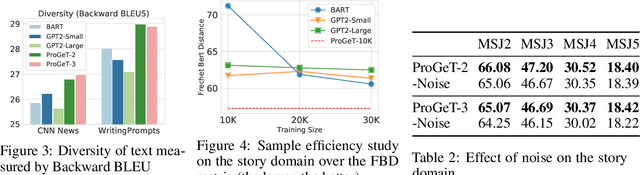
Large-scale language models pretrained on massive corpora of text, such as GPT-2, are powerful open-domain text generators. However, as our systematic examination reveals, it is still challenging for such models to generate coherent long passages of text ($>$1000 tokens), especially when the models are fine-tuned to the target domain on a small corpus. To overcome the limitation, we propose a simple but effective method of generating text in a progressive manner, inspired by generating images from low to high resolution. Our method first produces domain-specific content keywords and then progressively refines them into complete passages in multiple stages. The simple design allows our approach to take advantage of pretrained language models at each stage and effectively adapt to any target domain given only a small set of examples. We conduct a comprehensive empirical study with a broad set of evaluation metrics, and show that our approach significantly improves upon the fine-tuned GPT-2 in terms of domain-specific quality and sample efficiency. The coarse-to-fine nature of progressive generation also allows for a higher degree of control over the generated content.