 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Rejection Sampling: Trajectory Fusion for Scaling Mathematical Reasoning
Feb 04, 2026Large language models (LLMs) have made impressive strides in mathematical reasoning, often fine-tuned using rejection sampling that retains only correct reasoning trajectories. While effective, this paradigm treats supervision as a binary filter that systematically excludes teacher-generated errors, leaving a gap in how reasoning failures are modeled during training. In this paper, we propose TrajFusion, a fine-tuning strategy that reframes rejection sampling as a structured supervision construction process. Specifically, TrajFusion forms fused trajectories that explicitly model trial-and-error reasoning by interleaving selected incorrect trajectories with reflection prompts and correct trajectories. The length of each fused sample is adaptively controlled based on the frequency and diversity of teacher errors, providing richer supervision for challenging problems while safely reducing to vanilla rejection sampling fine-tuning (RFT) when error signals are uninformative. TrajFusion requires no changes to the architecture or training objective. Extensive experiments across multiple math benchmarks demonstrate that TrajFusion consistently outperforms RFT, particularly on challenging and long-form reasoning problems.
ConPress: Learning Efficient Reasoning from Multi-Question Contextual Pressure
Feb 01, 2026Large reasoning models (LRMs) typically solve reasoning-intensive tasks by generating long chain-of-thought (CoT) traces, leading to substantial inference overhead. We identify a reproducible inference-time phenomenon, termed Self-Compression: when multiple independent and answerable questions are presented within a single prompt, the model spontaneously produces shorter reasoning traces for each question. This phenomenon arises from multi-question contextual pressure during generation and consistently manifests across models and benchmarks. Building on this observation, we propose ConPress (Learning from Contextual Pressure), a lightweight self-supervised fine-tuning approach. ConPress constructs multi-question prompts to induce self-compression, samples the resulting model outputs, and parses and filters per-question traces to obtain concise yet correct reasoning trajectories. These trajectories are directly used for supervised fine-tuning, internalizing compressed reasoning behavior in single-question settings without external teachers, manual pruning, or reinforcement learning. With only 8k fine-tuning examples, ConPress reduces reasoning token usage by 59% on MATH500 and 33% on AIME25, while maintaining competitive accuracy.
Recent Advances of End-to-End Video Coding Technologies for AVS Standard Development
Jan 31, 2026Video coding standards are essential to enable the interoperability and widespread adoption of efficient video compression technologies. In pursuit of greater video compression efficiency, the AVS video coding working group launched the standardization exploration of end-to-end intelligent video coding, establishing the AVS End-to-End Intelligent Video Coding Exploration Model (AVS-EEM) project. A core design principle of AVS-EEM is its focus on practical deployment, featuring inherently low computational complexity and requiring strict adherence to the common test conditions of conventional video coding. This paper details the development history of AVS-EEM and provides a systematic introduction to its key technical framework, covering model architectures, training strategies, and inference optimizations. These innovations have collectively driven the project's rapid performance evolution, enabling continuous and significant gains under strict complexity constraints. Through over two years of iterative refinement and collaborative effort, the coding performance of AVS-EEM has seen substantial improvement. Experimental results demonstrate that its latest model achieves superior compression efficiency compared to the conventional AVS3 reference software, marking a significant step toward a deployable intelligent video coding standard.
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025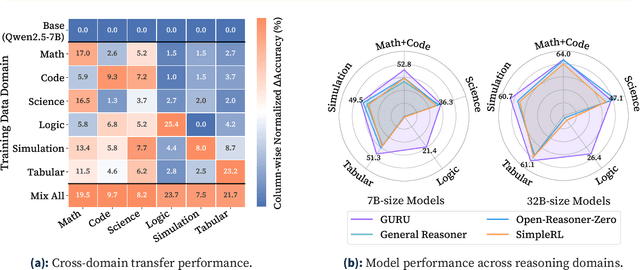
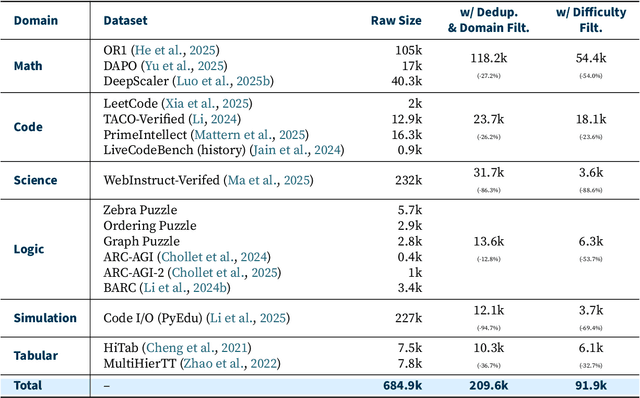
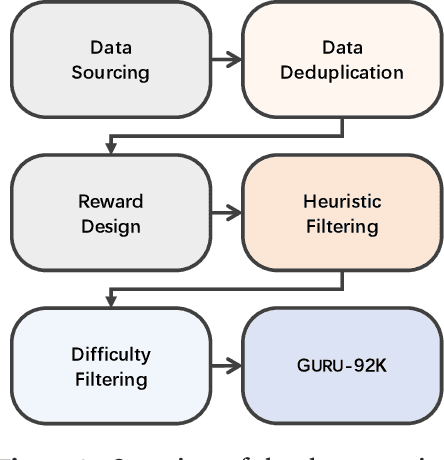

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
Toward Exploring the Code Understanding Capabilities of Pre-trained Code Generation Models
Jun 18, 2024Recently, large code generation models trained in a self-supervised manner on extensive unlabeled programming language data have achieved remarkable success. While these models acquire vast amounts of code knowledge, they perform poorly on code understanding tasks, such as code search and clone detection, as they are specifically trained for generation. Pre-training a larger encoder-only architecture model from scratch on massive code data can improve understanding performance. However, this approach is costly and time-consuming, making it suboptimal. In this paper, we pioneer the transfer of knowledge from pre-trained code generation models to code understanding tasks, significantly reducing training costs. We examine effective strategies for enabling decoder-only models to acquire robust code representations. Furthermore, we introduce CL4D, a contrastive learning method designed to enhance the representation capabilities of decoder-only models. Comprehensive experiments demonstrate that our approach achieves state-of-the-art performance in understanding tasks such as code search and clone detection. Our analysis shows that our method effectively reduces the distance between semantically identical samples in the representation space. These findings suggest the potential for unifying code understanding and generation tasks using a decoder-only structured model.
AcademicGPT: Empowering Academic Research
Nov 21, 2023



Large Language Models (LLMs) have demonstrated exceptional capabilities across various natural language processing tasks. Yet, many of these advanced LLMs are tailored for broad, general-purpose applications. In this technical report, we introduce AcademicGPT, designed specifically to empower academic research. AcademicGPT is a continual training model derived from LLaMA2-70B. Our training corpus mainly consists of academic papers, thesis, content from some academic domain, high-quality Chinese data and others. While it may not be extensive in data scale, AcademicGPT marks our initial venture into a domain-specific GPT tailored for research area. We evaluate AcademicGPT on several established public benchmarks such as MMLU and CEval, as well as on some specialized academic benchmarks like PubMedQA, SCIEval, and our newly-created ComputerScienceQA, to demonstrate its ability from general knowledge ability, to Chinese ability, and to academic ability. Building upon AcademicGPT's foundation model, we also developed several applications catered to the academic area, including General Academic Question Answering, AI-assisted Paper Reading, Paper Review, and AI-assisted Title and Abstract Generation.
Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation
Oct 22, 2023



Large language models (LLMs) have showcased remarkable prowess in code generation. However, automated code generation is still challenging since it requires a high-level semantic mapping between natural language requirements and codes. Most existing LLMs-based approaches for code generation rely on decoder-only causal language models often treate codes merely as plain text tokens, i.e., feeding the requirements as a prompt input, and outputing code as flat sequence of tokens, potentially missing the rich semantic features inherent in source code. To bridge this gap, this paper proposes the "Semantic Chain-of-Thought" approach to intruduce semantic information of code, named SeCoT. Our motivation is that the semantic information of the source code (\eg data flow and control flow) describes more precise program execution behavior, intention and function. By guiding LLM consider and integrate semantic information, we can achieve a more granular understanding and representation of code, enhancing code generation accuracy. Meanwhile, while traditional techniques leveraging such semantic information require complex static or dynamic code analysis to obtain features such as data flow and control flow, SeCoT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (i.e., in-context learning), while being generalizable and applicable to challenging domains. While SeCoT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: ChatGPT(close-source model) and WizardCoder(open-source model). The experimental study on three popular DL benchmarks (i.e., HumanEval, HumanEval-ET and MBPP) shows that SeCoT can achieves state-of-the-art performance, greatly improving the potential for large models and code generation.
Towards Effective and Compact Contextual Representation for Conformer Transducer Speech Recognition Systems
Jun 26, 2023Current ASR systems are mainly trained and evaluated at the utterance level. Long range cross utterance context can be incorporated. A key task is to derive a suitable compact representation of the most relevant history contexts. In contrast to previous researches based on either LSTM-RNN encoded histories that attenuate the information from longer range contexts, or frame level concatenation of transformer context embeddings, in this paper compact low-dimensional cross utterance contextual features are learned in the Conformer-Transducer Encoder using specially designed attention pooling layers that are applied over efficiently cached preceding utterances history vectors. Experiments on the 1000-hr Gigaspeech corpus demonstrate that the proposed contextualized streaming Conformer-Transducers outperform the baseline using utterance internal context only with statistically significant WER reductions of 0.7% to 0.5% absolute (4.3% to 3.1% relative) on the dev and test data.
BioBART: Pretraining and Evaluation of A Biomedical Generative Language Model
Apr 08, 2022


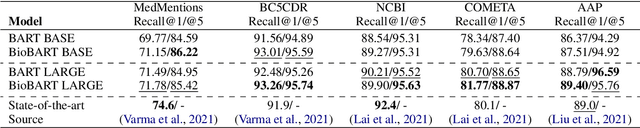
Pretrained language models have served as important backbones for natural language processing. Recently, in-domain pretraining has been shown to benefit various domain-specific downstream tasks. In the biomedical domain, natural language generation (NLG) tasks are of critical importance, while understudied. Approaching natural language understanding (NLU) tasks as NLG achieves satisfying performance in the general domain through constrained language generation or language prompting. We emphasize the lack of in-domain generative language models and the unsystematic generative downstream benchmarks in the biomedical domain, hindering the development of the research community. In this work, we introduce the generative language model BioBART that adapts BART to the biomedical domain. We collate various biomedical language generation tasks including dialogue, summarization, entity linking, and named entity recognition. BioBART pretrained on PubMed abstracts has enhanced performance compared to BART and set strong baselines on several tasks. Furthermore, we conduct ablation studies on the pretraining tasks for BioBART and find that sentence permutation has negative effects on downstream tasks.