 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaiyi-Diffusion-XL: Advancing Bilingual Text-to-Image Generation with Large Vision-Language Model Support
Jan 26, 2024Recent advancements in text-to-image models have significantly enhanced image generation capabilities, yet a notable gap of open-source models persists in bilingual or Chinese language support. To address this need, we present Taiyi-Diffusion-XL, a new Chinese and English bilingual text-to-image model which is developed by extending the capabilities of CLIP and Stable-Diffusion-XL through a process of bilingual continuous pre-training. This approach includes the efficient expansion of vocabulary by integrating the most frequently used Chinese characters into CLIP's tokenizer and embedding layers, coupled with an absolute position encoding expansion. Additionally, we enrich text prompts by large vision-language model, leading to better images captions and possess higher visual quality. These enhancements are subsequently applied to downstream text-to-image models. Our empirical results indicate that the developed CLIP model excels in bilingual image-text retrieval.Furthermore, the bilingual image generation capabilities of Taiyi-Diffusion-XL surpass previous models. This research leads to the development and open-sourcing of the Taiyi-Diffusion-XL model, representing a notable advancement in the field of image generation, particularly for Chinese language applications. This contribution is a step forward in addressing the need for more diverse language support in multimodal research. The model and demonstration are made publicly available at \href{https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-XL-3.5B/}{this https URL}, fostering further research and collaboration in this domain.
iDesigner: A High-Resolution and Complex-Prompt Following Text-to-Image Diffusion Model for Interior Design
Dec 19, 2023
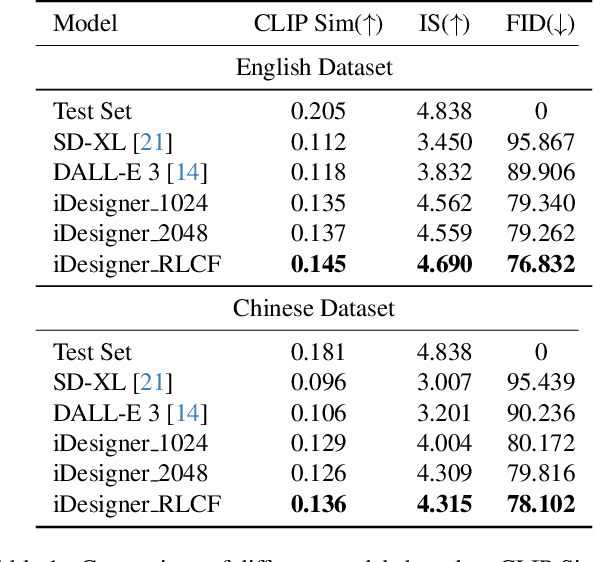

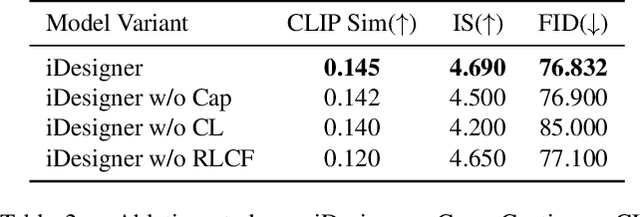
With the open-sourcing of text-to-image models (T2I) such as stable diffusion (SD) and stable diffusion XL (SD-XL), there is an influx of models fine-tuned in specific domains based on the open-source SD model, such as in anime, character portraits, etc. However, there are few specialized models in certain domains, such as interior design, which is attributed to the complex textual descriptions and detailed visual elements inherent in design, alongside the necessity for adaptable resolution. Therefore, text-to-image models for interior design are required to have outstanding prompt-following capabilities, as well as iterative collaboration with design professionals to achieve the desired outcome. In this paper, we collect and optimize text-image data in the design field and continue training in both English and Chinese on the basis of the open-source CLIP model. We also proposed a fine-tuning strategy with curriculum learning and reinforcement learning from CLIP feedback to enhance the prompt-following capabilities of our approach so as to improve the quality of image generation. The experimental results on the collected dataset demonstrate the effectiveness of the proposed approach, which achieves impressive results and outperforms strong baselines.
Lyrics: Boosting Fine-grained Language-Vision Alignment and Comprehension via Semantic-aware Visual Objects
Dec 08, 2023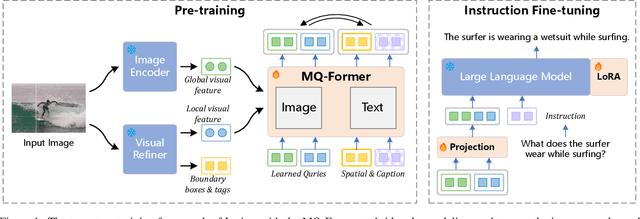
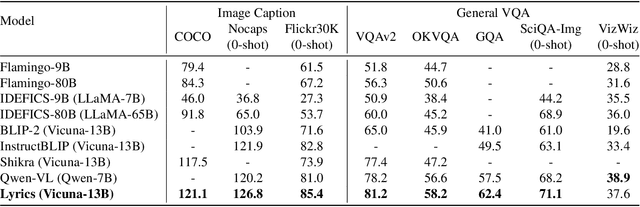
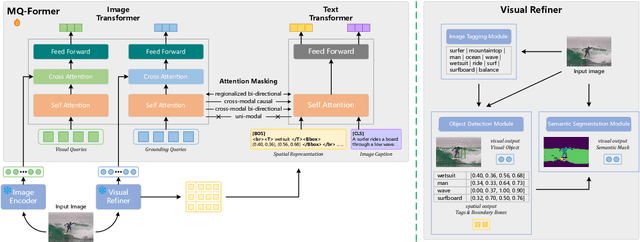
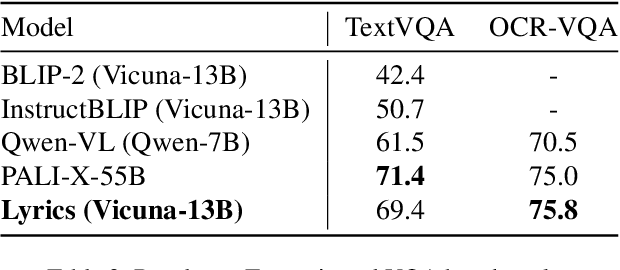
Large Vision Language Models (LVLMs) have demonstrated impressive zero-shot capabilities in various vision-language dialogue scenarios. However, the absence of fine-grained visual object detection hinders the model from understanding the details of images, leading to irreparable visual hallucinations and factual errors. In this paper, we propose Lyrics, a novel multi-modal pre-training and instruction fine-tuning paradigm that bootstraps vision-language alignment from fine-grained cross-modal collaboration. Building on the foundation of BLIP-2, Lyrics infuses local visual features extracted from a visual refiner that includes image tagging, object detection and semantic segmentation modules into the Querying Transformer, while on the text side, the language inputs equip the boundary boxes and tags derived from the visual refiner. We further introduce a two-stage training scheme, in which the pre-training stage bridges the modality gap through explicit and comprehensive vision-language alignment targets. During the instruction fine-tuning stage, we introduce semantic-aware visual feature extraction, a crucial method that enables the model to extract informative features from concrete visual objects. Our approach achieves strong performance on 13 held-out datasets across various vision-language tasks, and demonstrates promising multi-modal understanding and detailed depiction capabilities in real dialogue scenarios.
ChiMed-GPT: A Chinese Medical Large Language Model with Full Training Regime and Better Alignment to Human Preferences
Nov 23, 2023Recently, the increasing demand for superior medical services has highlighted the discrepancies in the medical infrastructure. With big data, especially texts, forming the foundation of medical services, there is an exigent need for effective natural language processing (NLP) solutions tailored to the healthcare domain. Conventional approaches leveraging pre-trained models present promising results in this domain and current large language models (LLMs) offer advanced foundation for medical text processing. However, most medical LLMs are trained only with supervised fine-tuning (SFT), even though it efficiently empowers LLMs to understand and respond to medical instructions but is ineffective in learning domain knowledge and aligning with human preference. Another engineering barrier that prevents current medical LLM from better text processing ability is their restricted context length (e.g., 2,048 tokens), making it hard for the LLMs to process long context, which is frequently required in the medical domain. In this work, we propose ChiMed-GPT, a new benchmark LLM designed explicitly for Chinese medical domain, with enlarged context length to 4,096 tokens and undergoes a comprehensive training regime with pre-training, SFT, and RLHF. Evaluations on real-world tasks including information extraction, question answering, and dialogue generation demonstrate ChiMed-GPT's superior performance over general domain LLMs. Furthermore, we analyze possible biases through prompting ChiMed-GPT to perform attitude scales regarding discrimination of patients, so as to contribute to further responsible development of LLMs in the medical domain. The code and model are released at https://github.com/synlp/ChiMed-GPT.
Ziya2: Data-centric Learning is All LLMs Need
Nov 06, 2023



Various large language models (LLMs) have been proposed in recent years, including closed- and open-source ones, continually setting new records on multiple benchmarks. However, the development of LLMs still faces several issues, such as high cost of training models from scratch, and continual pre-training leading to catastrophic forgetting, etc. Although many such issues are addressed along the line of research on LLMs, an important yet practical limitation is that many studies overly pursue enlarging model sizes without comprehensively analyzing and optimizing the use of pre-training data in their learning process, as well as appropriate organization and leveraging of such data in training LLMs under cost-effective settings. In this work, we propose Ziya2, a model with 13 billion parameters adopting LLaMA2 as the foundation model, and further pre-trained on 700 billion tokens, where we focus on pre-training techniques and use data-centric optimization to enhance the learning process of Ziya2 on different stages. Experiments show that Ziya2 significantly outperforms other models in multiple benchmarks especially with promising results compared to representative open-source ones. Ziya2 (Base) is released at https://huggingface.co/IDEA-CCNL/Ziya2-13B-Base and https://modelscope.cn/models/Fengshenbang/Ziya2-13B-Base/summary.
Ziya-Visual: Bilingual Large Vision-Language Model via Multi-Task Instruction Tuning
Oct 29, 2023



Recent advancements enlarge the capabilities of large language models (LLMs) in zero-shot image-to-text generation and understanding by integrating multi-modal inputs. However, such success is typically limited to English scenarios due to the lack of large-scale and high-quality non-English multi-modal resources, making it extremely difficult to establish competitive counterparts in other languages. In this paper, we introduce the Ziya-Visual series, a set of bilingual large-scale vision-language models (LVLMs) designed to incorporate visual semantics into LLM for multi-modal dialogue. Composed of Ziya-Visual-Base and Ziya-Visual-Chat, our models adopt the Querying Transformer from BLIP-2, further exploring the assistance of optimization schemes such as instruction tuning, multi-stage training and low-rank adaptation module for visual-language alignment. In addition, we stimulate the understanding ability of GPT-4 in multi-modal scenarios, translating our gathered English image-text datasets into Chinese and generating instruction-response through the in-context learning method. The experiment results demonstrate that compared to the existing LVLMs, Ziya-Visual achieves competitive performance across a wide range of English-only tasks including zero-shot image-text retrieval, image captioning, and visual question answering. The evaluation leaderboard accessed by GPT-4 also indicates that our models possess satisfactory image-text understanding and generation capabilities in Chinese multi-modal scenario dialogues. Code, demo and models are available at ~\url{https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1}.
UniEX: An Effective and Efficient Framework for Unified Information Extraction via a Span-extractive Perspective
May 22, 2023We propose a new paradigm for universal information extraction (IE) that is compatible with any schema format and applicable to a list of IE tasks, such as named entity recognition, relation extraction, event extraction and sentiment analysis. Our approach converts the text-based IE tasks as the token-pair problem, which uniformly disassembles all extraction targets into joint span detection, classification and association problems with a unified extractive framework, namely UniEX. UniEX can synchronously encode schema-based prompt and textual information, and collaboratively learn the generalized knowledge from pre-defined information using the auto-encoder language models. We develop a traffine attention mechanism to integrate heterogeneous factors including tasks, labels and inside tokens, and obtain the extraction target via a scoring matrix. Experiment results show that UniEX can outperform generative universal IE models in terms of performance and inference-speed on $14$ benchmarks IE datasets with the supervised setting. The state-of-the-art performance in low-resource scenarios also verifies the transferability and effectiveness of UniEX.
Orca: A Few-shot Benchmark for Chinese Conversational Machine Reading Comprehension
Feb 27, 2023



The conversational machine reading comprehension (CMRC) task aims to answer questions in conversations, which has been a hot research topic in recent years because of its wide applications. However, existing CMRC benchmarks in which each conversation is assigned a static passage are inconsistent with real scenarios. Thus, model's comprehension ability towards real scenarios are hard to evaluate reasonably. To this end, we propose the first Chinese CMRC benchmark Orca and further provide zero-shot/few-shot settings to evaluate model's generalization ability towards diverse domains. We collect 831 hot-topic driven conversations with 4,742 turns in total. Each turn of a conversation is assigned with a response-related passage, aiming to evaluate model's comprehension ability more reasonably. The topics of conversations are collected from social media platform and cover 33 domains, trying to be consistent with real scenarios. Importantly, answers in Orca are all well-annotated natural responses rather than the specific spans or short phrase in previous datasets. Besides, we implement three strong baselines to tackle the challenge in Orca. The results indicate the great challenge of our CMRC benchmark. Our datatset and checkpoints are available at https://github.com/nuochenpku/Orca.
TCBERT: A Technical Report for Chinese Topic Classification BERT
Nov 21, 2022



Bidirectional Encoder Representations from Transformers or BERT~\cite{devlin-etal-2019-bert} has been one of the base models for various NLP tasks due to its remarkable performance. Variants customized for different languages and tasks are proposed to further improve the performance. In this work, we investigate supervised continued pre-training~\cite{gururangan-etal-2020-dont} on BERT for Chinese topic classification task. Specifically, we incorporate prompt-based learning and contrastive learning into the pre-training. To adapt to the task of Chinese topic classification, we collect around 2.1M Chinese data spanning various topics. The pre-trained Chinese Topic Classification BERTs (TCBERTs) with different parameter sizes are open-sourced at \url{https://huggingface.co/IDEA-CCNL}.
Solving Math Word Problem via Cooperative Reasoning induced Language Models
Oct 28, 2022Large-scale pre-trained language models (PLMs) bring new opportunities to challenge problems, especially those that need high-level intelligence, such as the math word problem (MWPs). However, directly applying existing PLMs to MWPs can fail as the generation process lacks sufficient supervision and thus lacks fast adaptivity as humans. We notice that human reasoning has a dual reasoning framework that consists of an immediate reaction system (system 1) and a delicate reasoning system (system 2), where the entire reasoning is determined by their interaction. This inspires us to develop a cooperative reasoning-induced PLM for solving MWPs, called Cooperative Reasoning (CoRe), resulting in a human-like reasoning architecture with system 1 as the generator and system 2 as the verifier. In our approach, the generator is responsible for generating reasoning paths, and the verifiers are used to supervise the evaluation in order to obtain reliable feedback for the generator. We evaluate our CoRe framework on several mathematical reasoning datasets and achieve decent improvement over state-of-the-art methods, up to 9.8% increase over best baselines.