 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Boundaries of Natural Reasoning: Interleaved Bonus from Formal-Logic Verification
Jan 30, 2026Large Language Models (LLMs) show remarkable capabilities, yet their stochastic next-token prediction creates logical inconsistencies and reward hacking that formal symbolic systems avoid. To bridge this gap, we introduce a formal logic verification-guided framework that dynamically interleaves formal symbolic verification with the natural language generation process, providing real-time feedback to detect and rectify errors as they occur. Distinguished from previous neuro-symbolic methods limited by passive post-hoc validation, our approach actively penalizes intermediate fallacies during the reasoning chain. We operationalize this framework via a novel two-stage training pipeline that synergizes formal logic verification-guided supervised fine-tuning and policy optimization. Extensive evaluation on six benchmarks spanning mathematical, logical, and general reasoning demonstrates that our 7B and 14B models outperform state-of-the-art baselines by average margins of 10.4% and 14.2%, respectively. These results validate that formal verification can serve as a scalable mechanism to significantly push the performance boundaries of advanced LLM reasoning.
Glance-or-Gaze: Incentivizing LMMs to Adaptively Focus Search via Reinforcement Learning
Jan 20, 2026Large Multimodal Models (LMMs) have achieved remarkable success in visual understanding, yet they struggle with knowledge-intensive queries involving long-tail entities or evolving information due to static parametric knowledge. Recent search-augmented approaches attempt to address this limitation, but existing methods rely on indiscriminate whole-image retrieval that introduces substantial visual redundancy and noise, and lack deep iterative reflection, limiting their effectiveness on complex visual queries. To overcome these challenges, we propose Glance-or-Gaze (GoG), a fully autonomous framework that shifts from passive perception to active visual planning. GoG introduces a Selective Gaze mechanism that dynamically chooses whether to glance at global context or gaze into high-value regions, filtering irrelevant information before retrieval. We design a dual-stage training strategy: Reflective GoG Behavior Alignment via supervised fine-tuning instills the fundamental GoG paradigm, while Complexity-Adaptive Reinforcement Learning further enhances the model's capability to handle complex queries through iterative reasoning. Experiments across six benchmarks demonstrate state-of-the-art performance. Ablation studies confirm that both Selective Gaze and complexity-adaptive RL are essential for effective visual search. We will release our data and models for further exploration soon.
SG-FSM: A Self-Guiding Zero-Shot Prompting Paradigm for Multi-Hop Question Answering Based on Finite State Machine
Oct 22, 2024



Large Language Models with chain-of-thought prompting, such as OpenAI-o1, have shown impressive capabilities in natural language inference tasks. However, Multi-hop Question Answering (MHQA) remains challenging for many existing models due to issues like hallucination, error propagation, and limited context length. To address these challenges and enhance LLMs' performance on MHQA, we propose the Self-Guiding prompting Finite State Machine (SG-FSM), designed to strengthen multi-hop reasoning abilities. Unlike traditional chain-of-thought methods, SG-FSM tackles MHQA by iteratively breaking down complex questions into sub-questions, correcting itself to improve accuracy. It processes one sub-question at a time, dynamically deciding the next step based on the current context and results, functioning much like an automaton. Experiments across various benchmarks demonstrate the effectiveness of our approach, outperforming strong baselines on challenging datasets such as Musique. SG-FSM reduces hallucination, enabling recovery of the correct final answer despite intermediate errors. It also improves adherence to specified output formats, simplifying evaluation significantly.
FSM: A Finite State Machine Based Zero-Shot Prompting Paradigm for Multi-Hop Question Answering
Jul 03, 2024Large Language Models (LLMs) with chain-of-thought (COT) prompting have demonstrated impressive abilities on simple nature language inference tasks. However, they tend to perform poorly on Multi-hop Question Answering (MHQA) tasks due to several challenges, including hallucination, error propagation and limited context length. We propose a prompting method, Finite State Machine (FSM) to enhance the reasoning capabilities of LLM for complex tasks in addition to improved effectiveness and trustworthiness. Different from COT methods, FSM addresses MHQA by iteratively decomposing a question into multi-turn sub-questions, and self-correcting in time, improving the accuracy of answers in each step. Specifically, FSM addresses one sub-question at a time and decides on the next step based on its current result and state, in an automaton-like format. Experiments on benchmarks show the effectiveness of our method. Although our method performs on par with the baseline on relatively simpler datasets, it excels on challenging datasets like Musique. Moreover, this approach mitigates the hallucination phenomenon, wherein the correct final answer can be recovered despite errors in intermediate reasoning. Furthermore, our method improves LLMs' ability to follow specified output format requirements, significantly reducing the difficulty of answer interpretation and the need for reformatting.
Never Lost in the Middle: Improving Large Language Models via Attention Strengthening Question Answering
Nov 15, 2023



While large language models (LLMs) are equipped with longer text input capabilities than before, they are struggling to seek correct information in long contexts. The "lost in the middle" problem challenges most LLMs, referring to the dramatic decline in accuracy when correct information is located in the middle. To overcome this crucial issue, this paper proposes to enhance the information searching and reflection ability of LLMs in long contexts via specially designed tasks called Attention Strengthening Multi-doc QA (ASM QA). Following these tasks, our model excels in focusing more precisely on the desired information. Experimental results show substantial improvement in Multi-doc QA and other benchmarks, superior to state-of-the-art models by 13.7% absolute gain in shuffled settings, by 21.5% in passage retrieval task. We release our model, Ziya-Reader to promote related research in the community.
Ziya2: Data-centric Learning is All LLMs Need
Nov 06, 2023



Various large language models (LLMs) have been proposed in recent years, including closed- and open-source ones, continually setting new records on multiple benchmarks. However, the development of LLMs still faces several issues, such as high cost of training models from scratch, and continual pre-training leading to catastrophic forgetting, etc. Although many such issues are addressed along the line of research on LLMs, an important yet practical limitation is that many studies overly pursue enlarging model sizes without comprehensively analyzing and optimizing the use of pre-training data in their learning process, as well as appropriate organization and leveraging of such data in training LLMs under cost-effective settings. In this work, we propose Ziya2, a model with 13 billion parameters adopting LLaMA2 as the foundation model, and further pre-trained on 700 billion tokens, where we focus on pre-training techniques and use data-centric optimization to enhance the learning process of Ziya2 on different stages. Experiments show that Ziya2 significantly outperforms other models in multiple benchmarks especially with promising results compared to representative open-source ones. Ziya2 (Base) is released at https://huggingface.co/IDEA-CCNL/Ziya2-13B-Base and https://modelscope.cn/models/Fengshenbang/Ziya2-13B-Base/summary.
TCBERT: A Technical Report for Chinese Topic Classification BERT
Nov 21, 2022



Bidirectional Encoder Representations from Transformers or BERT~\cite{devlin-etal-2019-bert} has been one of the base models for various NLP tasks due to its remarkable performance. Variants customized for different languages and tasks are proposed to further improve the performance. In this work, we investigate supervised continued pre-training~\cite{gururangan-etal-2020-dont} on BERT for Chinese topic classification task. Specifically, we incorporate prompt-based learning and contrastive learning into the pre-training. To adapt to the task of Chinese topic classification, we collect around 2.1M Chinese data spanning various topics. The pre-trained Chinese Topic Classification BERTs (TCBERTs) with different parameter sizes are open-sourced at \url{https://huggingface.co/IDEA-CCNL}.
Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence
Sep 07, 2022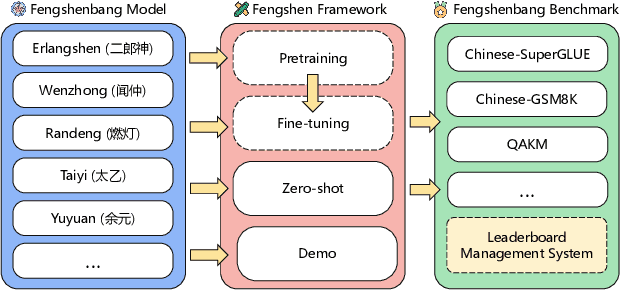
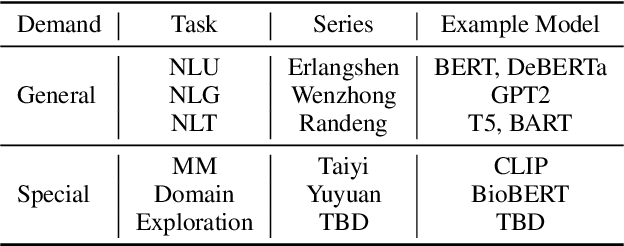

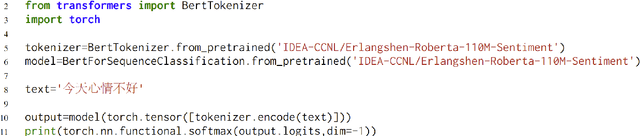
Nowadays, foundation models become one of fundamental infrastructures in artificial intelligence, paving ways to the general intelligence. However, the reality presents two urgent challenges: existing foundation models are dominated by the English-language community; users are often given limited resources and thus cannot always use foundation models. To support the development of the Chinese-language community, we introduce an open-source project, called Fengshenbang, which leads by the research center for Cognitive Computing and Natural Language (CCNL). Our project has comprehensive capabilities, including large pre-trained models, user-friendly APIs, benchmarks, datasets, and others. We wrap all these in three sub-projects: the Fengshenbang Model, the Fengshen Framework, and the Fengshen Benchmark. An open-source roadmap, Fengshenbang, aims to re-evaluate the open-source community of Chinese pre-trained large-scale models, prompting the development of the entire Chinese large-scale model community. We also want to build a user-centered open-source ecosystem to allow individuals to access the desired models to match their computing resources. Furthermore, we invite companies, colleges, and research institutions to collaborate with us to build the large-scale open-source model-based ecosystem. We hope that this project will be the foundation of Chinese cognitive intelligence.