 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language-Driven Global Mapping of Martian Landforms
Jan 22, 2026Planetary surfaces are typically analyzed using high-level semantic concepts in natural language, yet vast orbital image archives remain organized at the pixel level. This mismatch limits scalable, open-ended exploration of planetary surfaces. Here we present MarScope, a planetary-scale vision-language framework enabling natural language-driven, label-free mapping of Martian landforms. MarScope aligns planetary images and text in a shared semantic space, trained on over 200,000 curated image-text pairs. This framework transforms global geomorphic mapping on Mars by replacing pre-defined classifications with flexible semantic retrieval, enabling arbitrary user queries across the entire planet in 5 seconds with F1 scores up to 0.978. Applications further show that it extends beyond morphological classification to facilitate process-oriented analysis and similarity-based geomorphological mapping at a planetary scale. MarScope establishes a new paradigm where natural language serves as a direct interface for scientific discovery over massive geospatial datasets.
Astrea: A MOE-based Visual Understanding Model with Progressive Alignment
Mar 12, 2025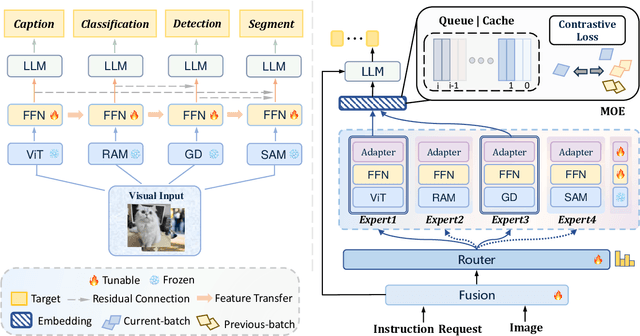
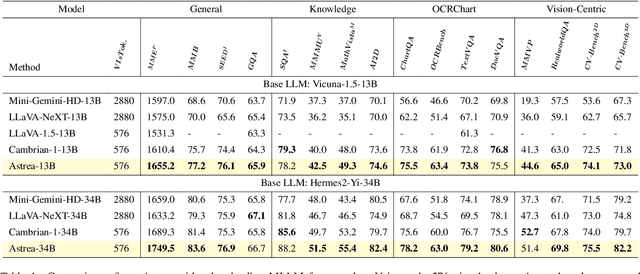
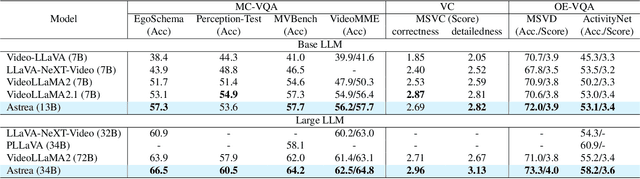
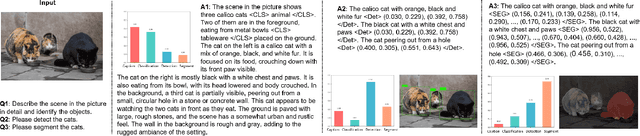
Vision-Language Models (VLMs) based on Mixture-of-Experts (MoE) architectures have emerged as a pivotal paradigm in multimodal understanding, offering a powerful framework for integrating visual and linguistic information. However, the increasing complexity and diversity of tasks present significant challenges in coordinating load balancing across heterogeneous visual experts, where optimizing one specialist's performance often compromises others' capabilities. To address task heterogeneity and expert load imbalance, we propose Astrea, a novel multi-expert collaborative VLM architecture based on progressive pre-alignment. Astrea introduces three key innovations: 1) A heterogeneous expert coordination mechanism that integrates four specialized models (detection, segmentation, classification, captioning) into a comprehensive expert matrix covering essential visual comprehension elements; 2) A dynamic knowledge fusion strategy featuring progressive pre-alignment to harmonize experts within the VLM latent space through contrastive learning, complemented by probabilistically activated stochastic residual connections to preserve knowledge continuity; 3) An enhanced optimization framework utilizing momentum contrastive learning for long-range dependency modeling and adaptive weight allocators for real-time expert contribution calibration. Extensive evaluations across 12 benchmark tasks spanning VQA, image captioning, and cross-modal retrieval demonstrate Astrea's superiority over state-of-the-art models, achieving an average performance gain of +4.7\%. This study provides the first empirical demonstration that progressive pre-alignment strategies enable VLMs to overcome task heterogeneity limitations, establishing new methodological foundations for developing general-purpose multimodal agents.
Fine-tuning can Help Detect Pretraining Data from Large Language Models
Oct 09, 2024


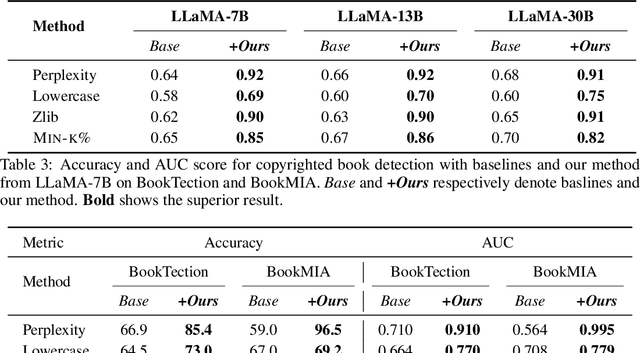
In the era of large language models (LLMs), detecting pretraining data has been increasingly important due to concerns about fair evaluation and ethical risks. Current methods differentiate members and non-members by designing scoring functions, like Perplexity and Min-k%. However, the diversity and complexity of training data magnifies the difficulty of distinguishing, leading to suboptimal performance in detecting pretraining data. In this paper, we first explore the benefits of unseen data, which can be easily collected after the release of the LLM. We find that the perplexities of LLMs perform differently for members and non-members, after fine-tuning with a small amount of previously unseen data. In light of this, we introduce a novel and effective method termed Fine-tuned Score Deviation (FSD), which improves the performance of current scoring functions for pretraining data detection. In particular, we propose to measure the deviation distance of current scores after fine-tuning on a small amount of unseen data within the same domain. In effect, using a few unseen data can largely decrease the scores of all non-members, leading to a larger deviation distance than members. Extensive experiments demonstrate the effectiveness of our method, significantly improving the AUC score on common benchmark datasets across various models.
Exploring Learning Complexity for Downstream Data Pruning
Feb 08, 2024



The over-parameterized pre-trained models pose a great challenge to fine-tuning with limited computation resources. An intuitive solution is to prune the less informative samples from the fine-tuning dataset. A series of training-based scoring functions are proposed to quantify the informativeness of the data subset but the pruning cost becomes non-negligible due to the heavy parameter updating. For efficient pruning, it is viable to adapt the similarity scoring function of geometric-based methods from training-based to training-free. However, we empirically show that such adaption distorts the original pruning and results in inferior performance on the downstream tasks. In this paper, we propose to treat the learning complexity (LC) as the scoring function for classification and regression tasks. Specifically, the learning complexity is defined as the average predicted confidence of subnets with different capacities, which encapsulates data processing within a converged model. Then we preserve the diverse and easy samples for fine-tuning. Extensive experiments with vision datasets demonstrate the effectiveness and efficiency of the proposed scoring function for classification tasks. For the instruction fine-tuning of large language models, our method achieves state-of-the-art performance with stable convergence, outperforming the full training with only 10\% of the instruction dataset.
Never Lost in the Middle: Improving Large Language Models via Attention Strengthening Question Answering
Nov 15, 2023



While large language models (LLMs) are equipped with longer text input capabilities than before, they are struggling to seek correct information in long contexts. The "lost in the middle" problem challenges most LLMs, referring to the dramatic decline in accuracy when correct information is located in the middle. To overcome this crucial issue, this paper proposes to enhance the information searching and reflection ability of LLMs in long contexts via specially designed tasks called Attention Strengthening Multi-doc QA (ASM QA). Following these tasks, our model excels in focusing more precisely on the desired information. Experimental results show substantial improvement in Multi-doc QA and other benchmarks, superior to state-of-the-art models by 13.7% absolute gain in shuffled settings, by 21.5% in passage retrieval task. We release our model, Ziya-Reader to promote related research in the community.