 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSG-FSM: A Self-Guiding Zero-Shot Prompting Paradigm for Multi-Hop Question Answering Based on Finite State Machine
Oct 22, 2024



Large Language Models with chain-of-thought prompting, such as OpenAI-o1, have shown impressive capabilities in natural language inference tasks. However, Multi-hop Question Answering (MHQA) remains challenging for many existing models due to issues like hallucination, error propagation, and limited context length. To address these challenges and enhance LLMs' performance on MHQA, we propose the Self-Guiding prompting Finite State Machine (SG-FSM), designed to strengthen multi-hop reasoning abilities. Unlike traditional chain-of-thought methods, SG-FSM tackles MHQA by iteratively breaking down complex questions into sub-questions, correcting itself to improve accuracy. It processes one sub-question at a time, dynamically deciding the next step based on the current context and results, functioning much like an automaton. Experiments across various benchmarks demonstrate the effectiveness of our approach, outperforming strong baselines on challenging datasets such as Musique. SG-FSM reduces hallucination, enabling recovery of the correct final answer despite intermediate errors. It also improves adherence to specified output formats, simplifying evaluation significantly.
Fostering Natural Conversation in Large Language Models with NICO: a Natural Interactive COnversation dataset
Aug 18, 2024
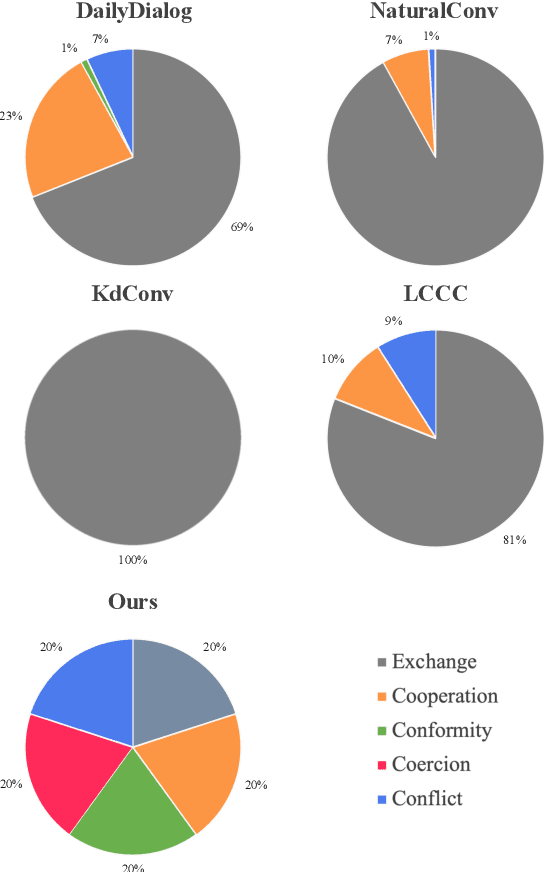
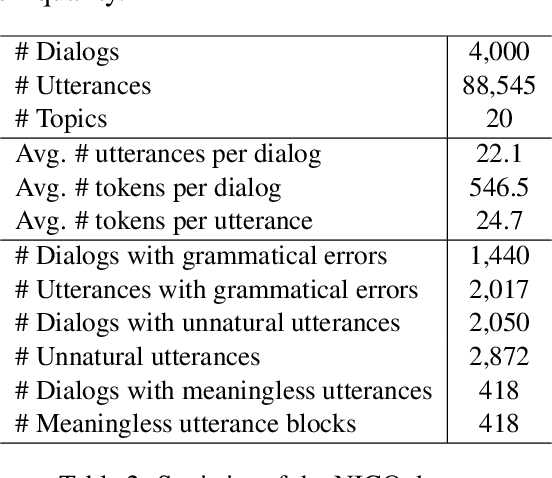
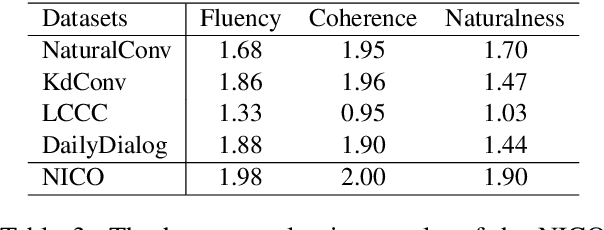
Benefiting from diverse instruction datasets, contemporary Large Language Models (LLMs) perform effectively as AI assistants in collaborating with humans. However, LLMs still struggle to generate natural and colloquial responses in real-world applications such as chatbots and psychological counseling that require more human-like interactions. To address these limitations, we introduce NICO, a Natural Interactive COnversation dataset in Chinese. We first use GPT-4-turbo to generate dialogue drafts and make them cover 20 daily-life topics and 5 types of social interactions. Then, we hire workers to revise these dialogues to ensure that they are free of grammatical errors and unnatural utterances. We define two dialogue-level natural conversation tasks and two sentence-level tasks for identifying and rewriting unnatural sentences. Multiple open-source and closed-source LLMs are tested and analyzed in detail. The experimental results highlight the challenge of the tasks and demonstrate how NICO can help foster the natural dialogue capabilities of LLMs. The dataset will be released.
FSM: A Finite State Machine Based Zero-Shot Prompting Paradigm for Multi-Hop Question Answering
Jul 03, 2024Large Language Models (LLMs) with chain-of-thought (COT) prompting have demonstrated impressive abilities on simple nature language inference tasks. However, they tend to perform poorly on Multi-hop Question Answering (MHQA) tasks due to several challenges, including hallucination, error propagation and limited context length. We propose a prompting method, Finite State Machine (FSM) to enhance the reasoning capabilities of LLM for complex tasks in addition to improved effectiveness and trustworthiness. Different from COT methods, FSM addresses MHQA by iteratively decomposing a question into multi-turn sub-questions, and self-correcting in time, improving the accuracy of answers in each step. Specifically, FSM addresses one sub-question at a time and decides on the next step based on its current result and state, in an automaton-like format. Experiments on benchmarks show the effectiveness of our method. Although our method performs on par with the baseline on relatively simpler datasets, it excels on challenging datasets like Musique. Moreover, this approach mitigates the hallucination phenomenon, wherein the correct final answer can be recovered despite errors in intermediate reasoning. Furthermore, our method improves LLMs' ability to follow specified output format requirements, significantly reducing the difficulty of answer interpretation and the need for reformatting.
Never Lost in the Middle: Improving Large Language Models via Attention Strengthening Question Answering
Nov 15, 2023



While large language models (LLMs) are equipped with longer text input capabilities than before, they are struggling to seek correct information in long contexts. The "lost in the middle" problem challenges most LLMs, referring to the dramatic decline in accuracy when correct information is located in the middle. To overcome this crucial issue, this paper proposes to enhance the information searching and reflection ability of LLMs in long contexts via specially designed tasks called Attention Strengthening Multi-doc QA (ASM QA). Following these tasks, our model excels in focusing more precisely on the desired information. Experimental results show substantial improvement in Multi-doc QA and other benchmarks, superior to state-of-the-art models by 13.7% absolute gain in shuffled settings, by 21.5% in passage retrieval task. We release our model, Ziya-Reader to promote related research in the community.
Orca: A Few-shot Benchmark for Chinese Conversational Machine Reading Comprehension
Feb 27, 2023



The conversational machine reading comprehension (CMRC) task aims to answer questions in conversations, which has been a hot research topic in recent years because of its wide applications. However, existing CMRC benchmarks in which each conversation is assigned a static passage are inconsistent with real scenarios. Thus, model's comprehension ability towards real scenarios are hard to evaluate reasonably. To this end, we propose the first Chinese CMRC benchmark Orca and further provide zero-shot/few-shot settings to evaluate model's generalization ability towards diverse domains. We collect 831 hot-topic driven conversations with 4,742 turns in total. Each turn of a conversation is assigned with a response-related passage, aiming to evaluate model's comprehension ability more reasonably. The topics of conversations are collected from social media platform and cover 33 domains, trying to be consistent with real scenarios. Importantly, answers in Orca are all well-annotated natural responses rather than the specific spans or short phrase in previous datasets. Besides, we implement three strong baselines to tackle the challenge in Orca. The results indicate the great challenge of our CMRC benchmark. Our datatset and checkpoints are available at https://github.com/nuochenpku/Orca.
Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence
Sep 07, 2022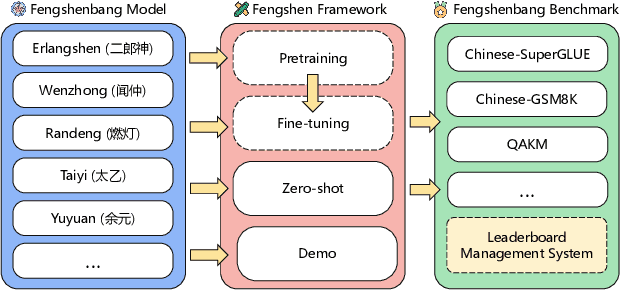
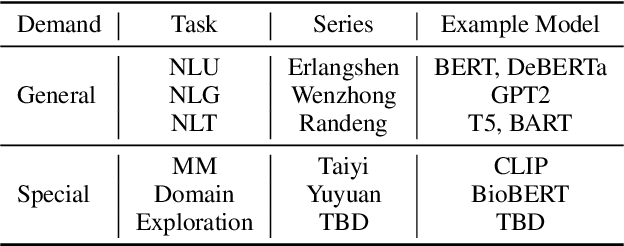

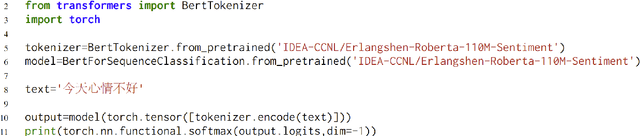
Nowadays, foundation models become one of fundamental infrastructures in artificial intelligence, paving ways to the general intelligence. However, the reality presents two urgent challenges: existing foundation models are dominated by the English-language community; users are often given limited resources and thus cannot always use foundation models. To support the development of the Chinese-language community, we introduce an open-source project, called Fengshenbang, which leads by the research center for Cognitive Computing and Natural Language (CCNL). Our project has comprehensive capabilities, including large pre-trained models, user-friendly APIs, benchmarks, datasets, and others. We wrap all these in three sub-projects: the Fengshenbang Model, the Fengshen Framework, and the Fengshen Benchmark. An open-source roadmap, Fengshenbang, aims to re-evaluate the open-source community of Chinese pre-trained large-scale models, prompting the development of the entire Chinese large-scale model community. We also want to build a user-centered open-source ecosystem to allow individuals to access the desired models to match their computing resources. Furthermore, we invite companies, colleges, and research institutions to collaborate with us to build the large-scale open-source model-based ecosystem. We hope that this project will be the foundation of Chinese cognitive intelligence.