 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNever Lost in the Middle: Improving Large Language Models via Attention Strengthening Question Answering
Nov 15, 2023



While large language models (LLMs) are equipped with longer text input capabilities than before, they are struggling to seek correct information in long contexts. The "lost in the middle" problem challenges most LLMs, referring to the dramatic decline in accuracy when correct information is located in the middle. To overcome this crucial issue, this paper proposes to enhance the information searching and reflection ability of LLMs in long contexts via specially designed tasks called Attention Strengthening Multi-doc QA (ASM QA). Following these tasks, our model excels in focusing more precisely on the desired information. Experimental results show substantial improvement in Multi-doc QA and other benchmarks, superior to state-of-the-art models by 13.7% absolute gain in shuffled settings, by 21.5% in passage retrieval task. We release our model, Ziya-Reader to promote related research in the community.
Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence
Sep 07, 2022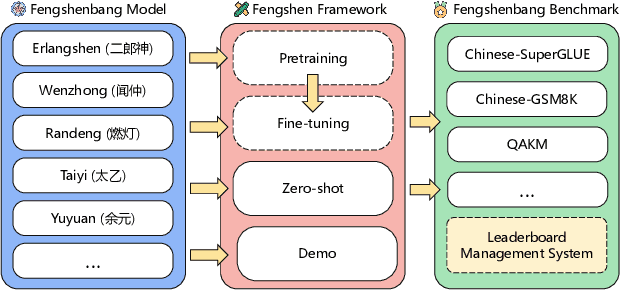
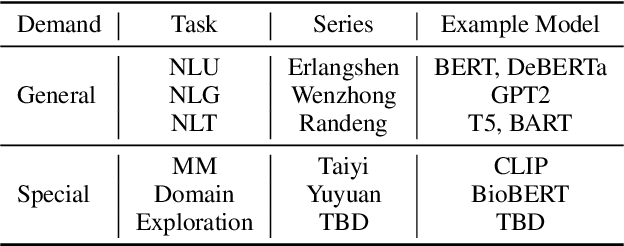

Nowadays, foundation models become one of fundamental infrastructures in artificial intelligence, paving ways to the general intelligence. However, the reality presents two urgent challenges: existing foundation models are dominated by the English-language community; users are often given limited resources and thus cannot always use foundation models. To support the development of the Chinese-language community, we introduce an open-source project, called Fengshenbang, which leads by the research center for Cognitive Computing and Natural Language (CCNL). Our project has comprehensive capabilities, including large pre-trained models, user-friendly APIs, benchmarks, datasets, and others. We wrap all these in three sub-projects: the Fengshenbang Model, the Fengshen Framework, and the Fengshen Benchmark. An open-source roadmap, Fengshenbang, aims to re-evaluate the open-source community of Chinese pre-trained large-scale models, prompting the development of the entire Chinese large-scale model community. We also want to build a user-centered open-source ecosystem to allow individuals to access the desired models to match their computing resources. Furthermore, we invite companies, colleges, and research institutions to collaborate with us to build the large-scale open-source model-based ecosystem. We hope that this project will be the foundation of Chinese cognitive intelligence.