 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaiyi-Diffusion-XL: Advancing Bilingual Text-to-Image Generation with Large Vision-Language Model Support
Jan 26, 2024Recent advancements in text-to-image models have significantly enhanced image generation capabilities, yet a notable gap of open-source models persists in bilingual or Chinese language support. To address this need, we present Taiyi-Diffusion-XL, a new Chinese and English bilingual text-to-image model which is developed by extending the capabilities of CLIP and Stable-Diffusion-XL through a process of bilingual continuous pre-training. This approach includes the efficient expansion of vocabulary by integrating the most frequently used Chinese characters into CLIP's tokenizer and embedding layers, coupled with an absolute position encoding expansion. Additionally, we enrich text prompts by large vision-language model, leading to better images captions and possess higher visual quality. These enhancements are subsequently applied to downstream text-to-image models. Our empirical results indicate that the developed CLIP model excels in bilingual image-text retrieval.Furthermore, the bilingual image generation capabilities of Taiyi-Diffusion-XL surpass previous models. This research leads to the development and open-sourcing of the Taiyi-Diffusion-XL model, representing a notable advancement in the field of image generation, particularly for Chinese language applications. This contribution is a step forward in addressing the need for more diverse language support in multimodal research. The model and demonstration are made publicly available at \href{https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-XL-3.5B/}{this https URL}, fostering further research and collaboration in this domain.
Unified Lattice Graph Fusion for Chinese Named Entity Recognition
Dec 28, 2023



Integrating lexicon into character-level sequence has been proven effective to leverage word boundary and semantic information in Chinese named entity recognition (NER). However, prior approaches usually utilize feature weighting and position coupling to integrate word information, but ignore the semantic and contextual correspondence between the fine-grained semantic units in the character-word space. To solve this issue, we propose a Unified Lattice Graph Fusion (ULGF) approach for Chinese NER. ULGF can explicitly capture various semantic and boundary relations across different semantic units with the adjacency matrix by converting the lattice structure into a unified graph. We stack multiple graph-based intra-source self-attention and inter-source cross-gating fusion layers that iteratively carry out semantic interactions to learn node representations. To alleviate the over-reliance on word information, we further propose to leverage lexicon entity classification as an auxiliary task. Experiments on four Chinese NER benchmark datasets demonstrate the superiority of our ULGF approach.
iDesigner: A High-Resolution and Complex-Prompt Following Text-to-Image Diffusion Model for Interior Design
Dec 19, 2023
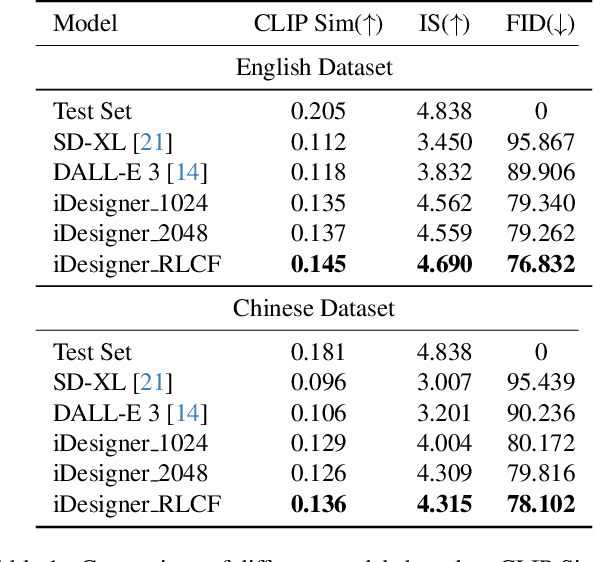

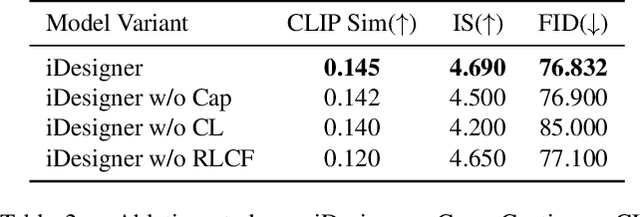
With the open-sourcing of text-to-image models (T2I) such as stable diffusion (SD) and stable diffusion XL (SD-XL), there is an influx of models fine-tuned in specific domains based on the open-source SD model, such as in anime, character portraits, etc. However, there are few specialized models in certain domains, such as interior design, which is attributed to the complex textual descriptions and detailed visual elements inherent in design, alongside the necessity for adaptable resolution. Therefore, text-to-image models for interior design are required to have outstanding prompt-following capabilities, as well as iterative collaboration with design professionals to achieve the desired outcome. In this paper, we collect and optimize text-image data in the design field and continue training in both English and Chinese on the basis of the open-source CLIP model. We also proposed a fine-tuning strategy with curriculum learning and reinforcement learning from CLIP feedback to enhance the prompt-following capabilities of our approach so as to improve the quality of image generation. The experimental results on the collected dataset demonstrate the effectiveness of the proposed approach, which achieves impressive results and outperforms strong baselines.
Lyrics: Boosting Fine-grained Language-Vision Alignment and Comprehension via Semantic-aware Visual Objects
Dec 08, 2023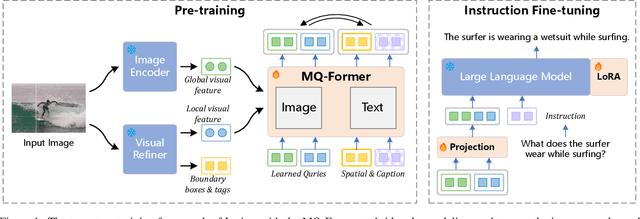
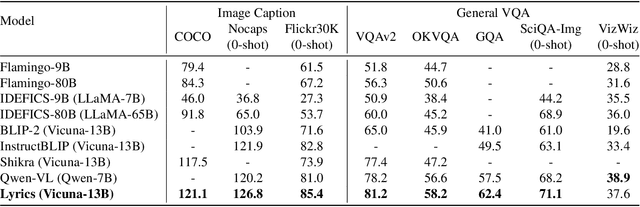
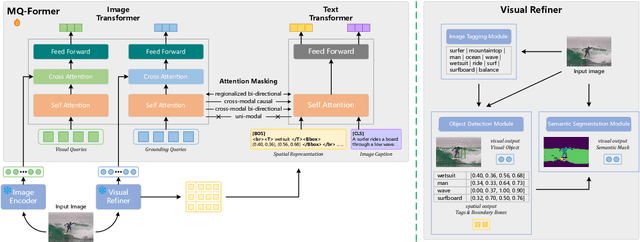
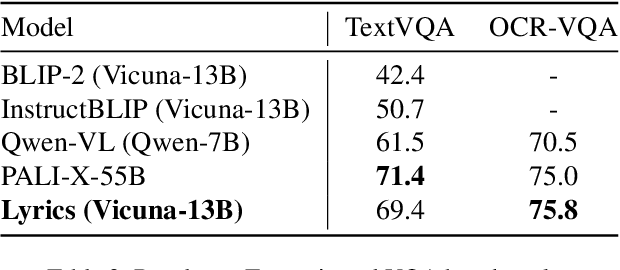
Large Vision Language Models (LVLMs) have demonstrated impressive zero-shot capabilities in various vision-language dialogue scenarios. However, the absence of fine-grained visual object detection hinders the model from understanding the details of images, leading to irreparable visual hallucinations and factual errors. In this paper, we propose Lyrics, a novel multi-modal pre-training and instruction fine-tuning paradigm that bootstraps vision-language alignment from fine-grained cross-modal collaboration. Building on the foundation of BLIP-2, Lyrics infuses local visual features extracted from a visual refiner that includes image tagging, object detection and semantic segmentation modules into the Querying Transformer, while on the text side, the language inputs equip the boundary boxes and tags derived from the visual refiner. We further introduce a two-stage training scheme, in which the pre-training stage bridges the modality gap through explicit and comprehensive vision-language alignment targets. During the instruction fine-tuning stage, we introduce semantic-aware visual feature extraction, a crucial method that enables the model to extract informative features from concrete visual objects. Our approach achieves strong performance on 13 held-out datasets across various vision-language tasks, and demonstrates promising multi-modal understanding and detailed depiction capabilities in real dialogue scenarios.
Ziya2: Data-centric Learning is All LLMs Need
Nov 06, 2023



Various large language models (LLMs) have been proposed in recent years, including closed- and open-source ones, continually setting new records on multiple benchmarks. However, the development of LLMs still faces several issues, such as high cost of training models from scratch, and continual pre-training leading to catastrophic forgetting, etc. Although many such issues are addressed along the line of research on LLMs, an important yet practical limitation is that many studies overly pursue enlarging model sizes without comprehensively analyzing and optimizing the use of pre-training data in their learning process, as well as appropriate organization and leveraging of such data in training LLMs under cost-effective settings. In this work, we propose Ziya2, a model with 13 billion parameters adopting LLaMA2 as the foundation model, and further pre-trained on 700 billion tokens, where we focus on pre-training techniques and use data-centric optimization to enhance the learning process of Ziya2 on different stages. Experiments show that Ziya2 significantly outperforms other models in multiple benchmarks especially with promising results compared to representative open-source ones. Ziya2 (Base) is released at https://huggingface.co/IDEA-CCNL/Ziya2-13B-Base and https://modelscope.cn/models/Fengshenbang/Ziya2-13B-Base/summary.
Ziya-Visual: Bilingual Large Vision-Language Model via Multi-Task Instruction Tuning
Oct 29, 2023



Recent advancements enlarge the capabilities of large language models (LLMs) in zero-shot image-to-text generation and understanding by integrating multi-modal inputs. However, such success is typically limited to English scenarios due to the lack of large-scale and high-quality non-English multi-modal resources, making it extremely difficult to establish competitive counterparts in other languages. In this paper, we introduce the Ziya-Visual series, a set of bilingual large-scale vision-language models (LVLMs) designed to incorporate visual semantics into LLM for multi-modal dialogue. Composed of Ziya-Visual-Base and Ziya-Visual-Chat, our models adopt the Querying Transformer from BLIP-2, further exploring the assistance of optimization schemes such as instruction tuning, multi-stage training and low-rank adaptation module for visual-language alignment. In addition, we stimulate the understanding ability of GPT-4 in multi-modal scenarios, translating our gathered English image-text datasets into Chinese and generating instruction-response through the in-context learning method. The experiment results demonstrate that compared to the existing LVLMs, Ziya-Visual achieves competitive performance across a wide range of English-only tasks including zero-shot image-text retrieval, image captioning, and visual question answering. The evaluation leaderboard accessed by GPT-4 also indicates that our models possess satisfactory image-text understanding and generation capabilities in Chinese multi-modal scenario dialogues. Code, demo and models are available at ~\url{https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1}.
Flat Multi-modal Interaction Transformer for Named Entity Recognition
Aug 23, 2022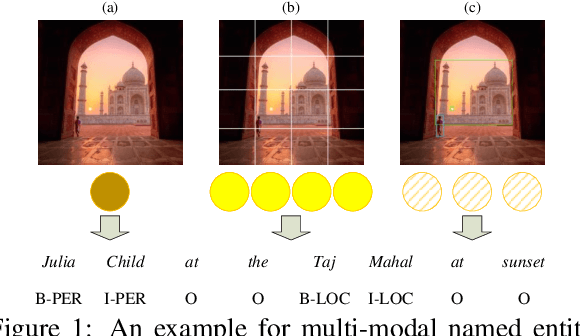
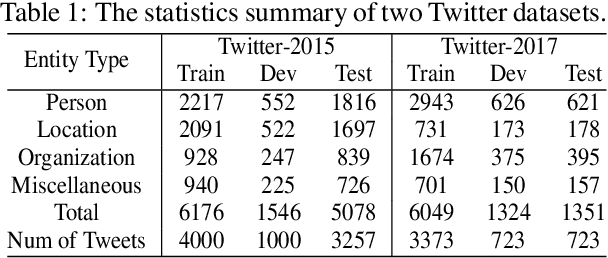
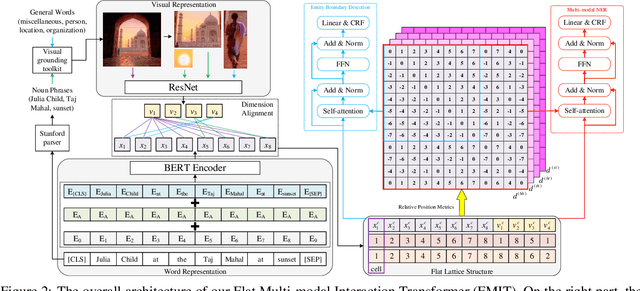
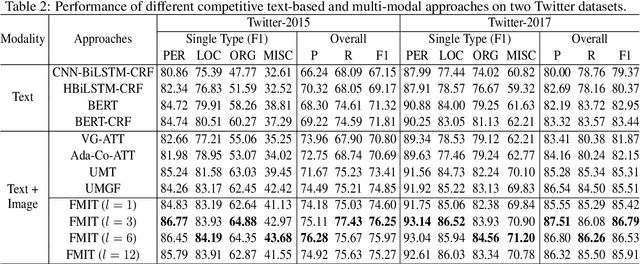
Multi-modal named entity recognition (MNER) aims at identifying entity spans and recognizing their categories in social media posts with the aid of images. However, in dominant MNER approaches, the interaction of different modalities is usually carried out through the alternation of self-attention and cross-attention or over-reliance on the gating machine, which results in imprecise and biased correspondence between fine-grained semantic units of text and image. To address this issue, we propose a Flat Multi-modal Interaction Transformer (FMIT) for MNER. Specifically, we first utilize noun phrases in sentences and general domain words to obtain visual cues. Then, we transform the fine-grained semantic representation of the vision and text into a unified lattice structure and design a novel relative position encoding to match different modalities in Transformer. Meanwhile, we propose to leverage entity boundary detection as an auxiliary task to alleviate visual bias. Experiments show that our methods achieve the new state-of-the-art performance on two benchmark datasets.