 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlat Multi-modal Interaction Transformer for Named Entity Recognition
Paper and Code
Aug 23, 2022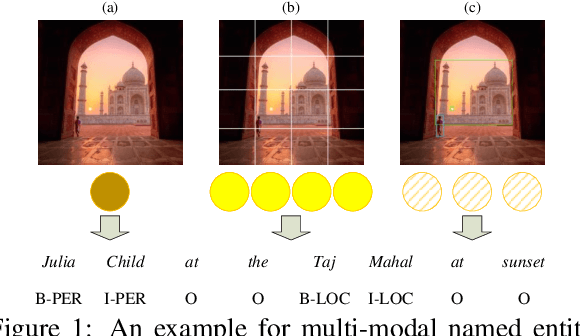
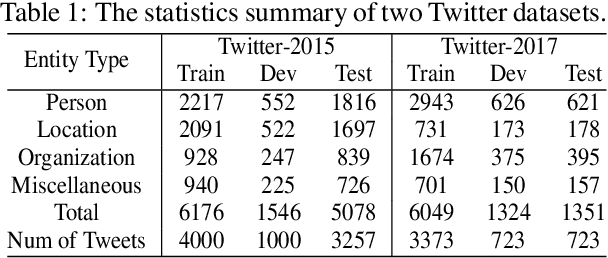
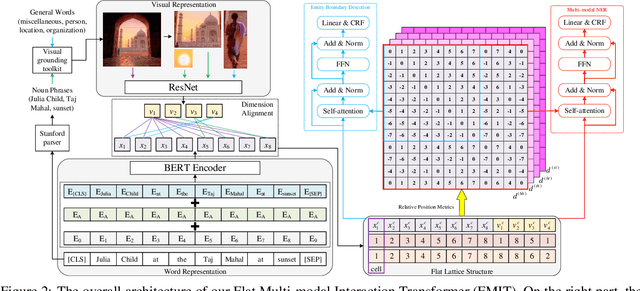
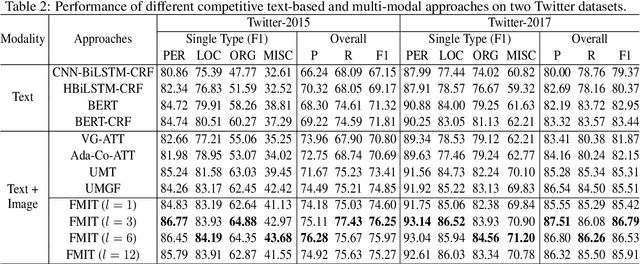
Multi-modal named entity recognition (MNER) aims at identifying entity spans and recognizing their categories in social media posts with the aid of images. However, in dominant MNER approaches, the interaction of different modalities is usually carried out through the alternation of self-attention and cross-attention or over-reliance on the gating machine, which results in imprecise and biased correspondence between fine-grained semantic units of text and image. To address this issue, we propose a Flat Multi-modal Interaction Transformer (FMIT) for MNER. Specifically, we first utilize noun phrases in sentences and general domain words to obtain visual cues. Then, we transform the fine-grained semantic representation of the vision and text into a unified lattice structure and design a novel relative position encoding to match different modalities in Transformer. Meanwhile, we propose to leverage entity boundary detection as an auxiliary task to alleviate visual bias. Experiments show that our methods achieve the new state-of-the-art performance on two benchmark datasets.