 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliceWorld: A Predictive and Controllable World-State Model for CT Report Generation
May 23, 2026CT report generation (CTRG) requires models to summarize three-dimensional anatomical context and pathological findings from hundreds of axial slices. Existing methods typically learn a direct image-to-text mapping, providing limited mechanisms for modeling how CT evidence evolves across slices or how reports respond to controlled changes in latent lesion-related factors. We propose SliceWorld, a CT-specific world-state framework that treats an axial CT scan as an ordered sequence along the z-axis. SliceWorld encodes prefix CT evidence into factor-aware latent states containing anatomy, lesion, and uncertainty components, and projects these states into world tokens used for multi-step future-slice feature prediction, lesion-factor intervention, and LLM-based report generation. The model is first pretrained on CT slice sequences with predictive, factor-aware, and counterfactual objectives, and is then fine-tuned on paired CT-report data. Experiments on M3D-Cap and CT-RATE show that SliceWorld improves natural language generation metrics and clinically oriented automatic evaluation. Further analyses demonstrate multi-horizon future-slice prediction, measurable factor alignment, reduced-slice robustness, and selective lesion-sensitive report modulation.
SURGE: An Event-Centric Social Media Sentiment Time Series Benchmark with Interaction Structure
May 20, 2026Public events on social media generate large volumes of discussion whose collective dynamics carry direct value for opinion forecasting and crisis response. Capturing how these dynamics evolve across an event's lifecycle requires organizing fragmented posts into event-level time series. Existing datasets cover only a small number of events within a single category, and typically discard the interaction structure between posts when constructing time series, which restricts both transfer across event types and controlled study of how interactions shape the resulting collective dynamics. We present SURGE, a multi-event social media benchmark that pairs event-level time series with aligned text and interaction structure linking posts within an event. SURGE is built through an automated pipeline that produces calendar-aligned time series at three temporal granularities, covering 67 events and more than 800K posts across five event categories. Each time bin is paired with flat and structured textual views derived from the same selected posts, enabling controlled evaluation of whether social interaction structure affects forecasting behavior. On top of SURGE we define benchmark protocols for numerical-only forecasting, text-augmented forecasting, high-interaction evaluation, and leave-one-category-out generalization. Experiments with representative time-series and multimodal forecasting models reveal three properties of the benchmark: a strong local-persistence regime in which naive baselines remain hard to beat under absolute error, limited transfer of existing text-augmented forecasters to event-driven social-media data, and increased difficulty on reply-dense periods that aggregate metrics tend to obscure. We further include a lightweight structure-aware probe as a reference implementation, illustrating how SURGE can support interaction-aware forecasting research.
Training Data Selection with Gradient Orthogonality for Efficient Domain Adaptation
Feb 06, 2026Fine-tuning large language models (LLMs) for specialized domains often necessitates a trade-off between acquiring domain expertise and retaining general reasoning capabilities, a phenomenon known as catastrophic forgetting. Existing remedies face a dichotomy: gradient surgery methods offer geometric safety but incur prohibitive computational costs via online projections, while efficient data selection approaches reduce overhead but remain blind to conflict-inducing gradient directions. In this paper, we propose Orthogonal Gradient Selection (OGS), a data-centric method that harmonizes domain performance, general capability retention, and training efficiency. OGS shifts the geometric insights of gradient projection from the optimizer to the data selection stage by treating data selection as a constrained decision-making process. By leveraging a lightweight Navigator model and reinforcement learning techniques, OGS dynamically identifies training samples whose gradients are orthogonal to a general-knowledge anchor. This approach ensures naturally safe updates for target models without modifying the optimizer or incurring runtime projection costs. Experiments across medical, legal, and financial domains demonstrate that OGS achieves excellent results, significantly improving domain performance and training efficiency while maintaining or even enhancing performance on general tasks such as GSM8K.
LEAD: Layer-wise Expert-aligned Decoding for Faithful Radiology Report Generation
Feb 04, 2026Radiology Report Generation (RRG) aims to produce accurate and coherent diagnostics from medical images. Although large vision language models (LVLM) improve report fluency and accuracy, they exhibit hallucinations, generating plausible yet image-ungrounded pathological details. Existing methods primarily rely on external knowledge guidance to facilitate the alignment between generated text and visual information. However, these approaches often ignore the inherent decoding priors and vision-language alignment biases in pretrained models and lack robustness due to reliance on constructed guidance. In this paper, we propose Layer-wise Expert-aligned Decoding (LEAD), a novel method to inherently modify the LVLM decoding trajectory. A multiple experts module is designed for extracting distinct pathological features which are integrated into each decoder layer via a gating mechanism. This layer-wise architecture enables the LLM to consult expert features at every inference step via a learned gating function, thereby dynamically rectifying decoding biases and steering the generation toward factual consistency. Experiments conducted on multiple public datasets demonstrate that the LEAD method yields effective improvements in clinical accuracy metrics and mitigates hallucinations while preserving high generation quality.
Explainable Multimodal Aspect-Based Sentiment Analysis with Dependency-guided Large Language Model
Jan 11, 2026Multimodal aspect-based sentiment analysis (MABSA) aims to identify aspect-level sentiments by jointly modeling textual and visual information, which is essential for fine-grained opinion understanding in social media. Existing approaches mainly rely on discriminative classification with complex multimodal fusion, yet lacking explicit sentiment explainability. In this paper, we reformulate MABSA as a generative and explainable task, proposing a unified framework that simultaneously predicts aspect-level sentiment and generates natural language explanations. Based on multimodal large language models (MLLMs), our approach employs a prompt-based generative paradigm, jointly producing sentiment and explanation. To further enhance aspect-oriented reasoning capabilities, we propose a dependency-syntax-guided sentiment cue strategy. This strategy prunes and textualizes the aspect-centered dependency syntax tree, guiding the model to distinguish different sentiment aspects and enhancing its explainability. To enable explainability, we use MLLMs to construct new datasets with sentiment explanations to fine-tune. Experiments show that our approach not only achieves consistent gains in sentiment classification accuracy, but also produces faithful, aspect-grounded explanations.
Fine-grained Verbal Attack Detection via a Hierarchical Divide-and-Conquer Framework
Jan 11, 2026In the digital era, effective identification and analysis of verbal attacks are essential for maintaining online civility and ensuring social security. However, existing research is limited by insufficient modeling of conversational structure and contextual dependency, particularly in Chinese social media where implicit attacks are prevalent. Current attack detection studies often emphasize general semantic understanding while overlooking user response relationships, hindering the identification of implicit and context-dependent attacks. To address these challenges, we present the novel "Hierarchical Attack Comment Detection" dataset and propose a divide-and-conquer, fine-grained framework for verbal attack recognition based on spatiotemporal information. The proposed dataset explicitly encodes hierarchical reply structures and chronological order, capturing complex interaction patterns in multi-turn discussions. Building on this dataset, the framework decomposes attack detection into hierarchical subtasks, where specialized lightweight models handle explicit detection, implicit intent inference, and target identification under constrained context. Extensive experiments on the proposed dataset and benchmark intention detection datasets show that smaller models using our framework significantly outperform larger monolithic models relying on parameter scaling, demonstrating the effectiveness of structured task decomposition.
Chain-of-thought Reviewing and Correction for Time Series Question Answering
Dec 27, 2025With the advancement of large language models (LLMs), diverse time series analysis tasks are reformulated as time series question answering (TSQA) through a unified natural language interface. However, existing LLM-based approaches largely adopt general natural language processing techniques and are prone to reasoning errors when handling complex numerical sequences. Different from purely textual tasks, time series data are inherently verifiable, enabling consistency checking between reasoning steps and the original input. Motivated by this property, we propose T3LLM, which performs multi-step reasoning with an explicit correction mechanism for time series question answering. The T3LLM framework consists of three LLMs, namely, a worker, a reviewer, and a student, that are responsible for generation, review, and reasoning learning, respectively. Within this framework, the worker generates step-wise chains of thought (CoT) under structured prompts, while the reviewer inspects the reasoning, identifies erroneous steps, and provides corrective comments. The collaboratively generated corrected CoT are used to fine-tune the student model, internalizing multi-step reasoning and self-correction into its parameters. Experiments on multiple real-world TSQA benchmarks demonstrate that T3LLM achieves state-of-the-art performance over strong LLM-based baselines.
MoE Pathfinder: Trajectory-driven Expert Pruning
Dec 20, 2025Mixture-of-experts (MoE) architectures used in large language models (LLMs) achieve state-of-the-art performance across diverse tasks yet face practical challenges such as deployment complexity and low activation efficiency. Expert pruning has thus emerged as a promising solution to reduce computational overhead and simplify the deployment of MoE models. However, existing expert pruning approaches conventionally rely on local importance metrics and often apply uniform layer-wise pruning, leveraging only partial evaluation signals and overlooking the heterogeneous contributions of experts across layers. To address these limitations, we propose an expert pruning approach based on the trajectory of activated experts across layers, which treats MoE as a weighted computation graph and casts expert selection as a global optimal path planning problem. Within this framework, we integrate complementary importance signals from reconstruction error, routing probabilities, and activation strength at the trajectory level, which naturally yields non-uniform expert retention across layers. Experiments show that our approach achieves superior pruning performance on nearly all tasks compared with most existing approaches.
Frustratingly Easy Task-aware Pruning for Large Language Models
Oct 26, 2025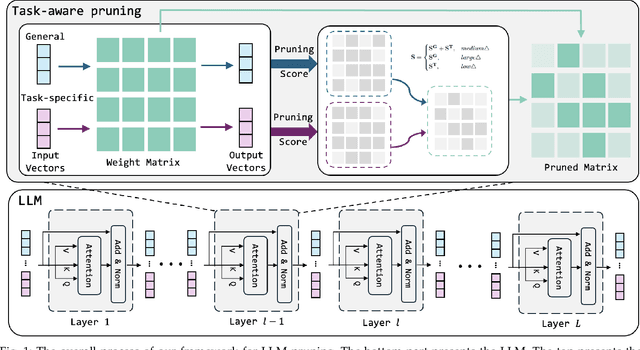
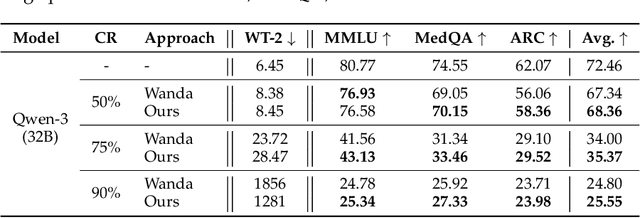
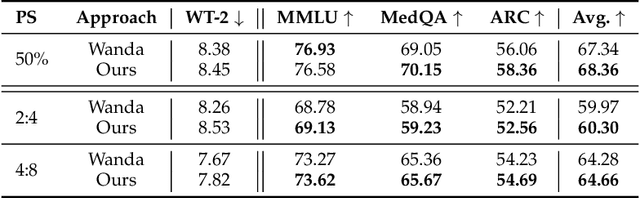
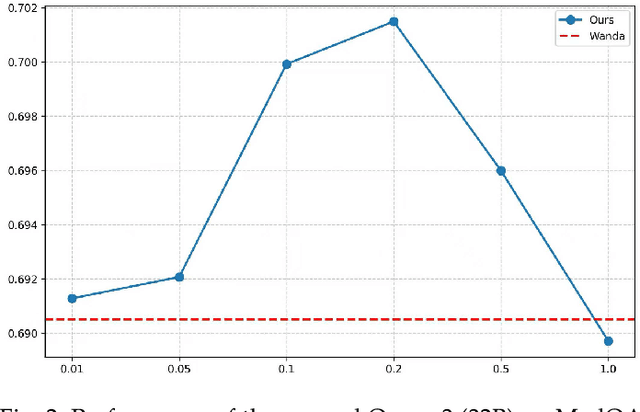
Pruning provides a practical solution to reduce the resources required to run large language models (LLMs) to benefit from their effective capabilities as well as control their cost for training and inference. Research on LLM pruning often ranks the importance of LLM parameters using their magnitudes and calibration-data activations and removes (or masks) the less important ones, accordingly reducing LLMs' size. However, these approaches primarily focus on preserving the LLM's ability to generate fluent sentences, while neglecting performance on specific domains and tasks. In this paper, we propose a simple yet effective pruning approach for LLMs that preserves task-specific capabilities while shrinking their parameter space. We first analyze how conventional pruning minimizes loss perturbation under general-domain calibration and extend this formulation by incorporating task-specific feature distributions into the importance computation of existing pruning algorithms. Thus, our framework computes separate importance scores using both general and task-specific calibration data, partitions parameters into shared and exclusive groups based on activation-norm differences, and then fuses their scores to guide the pruning process. This design enables our method to integrate seamlessly with various foundation pruning techniques and preserve the LLM's specialized abilities under compression. Experiments on widely used benchmarks demonstrate that our approach is effective and consistently outperforms the baselines with identical pruning ratios and different settings.
Recurrent Visual Feature Extraction and Stereo Attentions for CT Report Generation
Jun 24, 2025



Generating reports for computed tomography (CT) images is a challenging task, while similar to existing studies for medical image report generation, yet has its unique characteristics, such as spatial encoding of multiple images, alignment between image volume and texts, etc. Existing solutions typically use general 2D or 3D image processing techniques to extract features from a CT volume, where they firstly compress the volume and then divide the compressed CT slices into patches for visual encoding. These approaches do not explicitly account for the transformations among CT slices, nor do they effectively integrate multi-level image features, particularly those containing specific organ lesions, to instruct CT report generation (CTRG). In considering the strong correlation among consecutive slices in CT scans, in this paper, we propose a large language model (LLM) based CTRG method with recurrent visual feature extraction and stereo attentions for hierarchical feature modeling. Specifically, we use a vision Transformer to recurrently process each slice in a CT volume, and employ a set of attentions over the encoded slices from different perspectives to selectively obtain important visual information and align them with textual features, so as to better instruct an LLM for CTRG. Experiment results and further analysis on the benchmark M3D-Cap dataset show that our method outperforms strong baseline models and achieves state-of-the-art results, demonstrating its validity and effectiveness.