 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Named Entity Recognition with Attentive Ensemble of Syntactic Information
Oct 29, 2020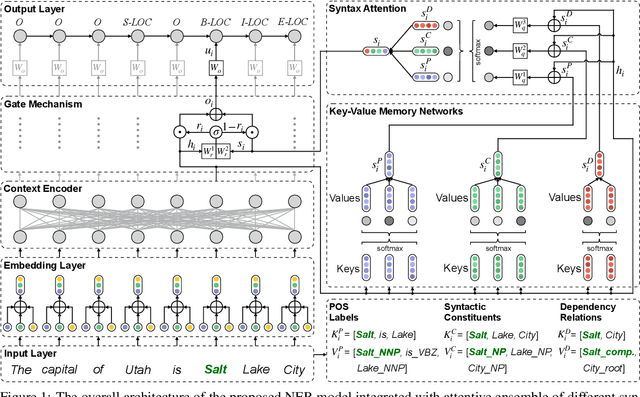
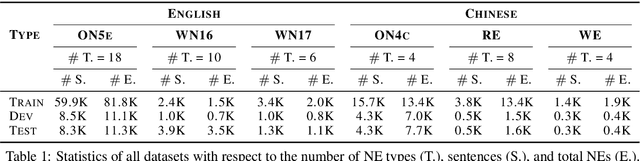
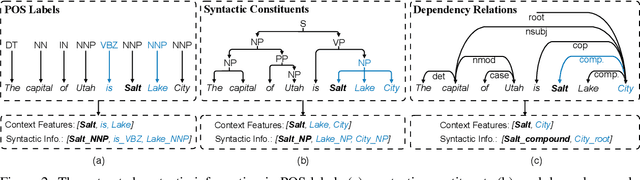
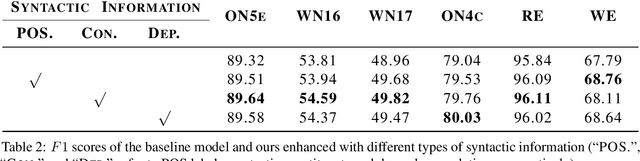
Named entity recognition (NER) is highly sensitive to sentential syntactic and semantic properties where entities may be extracted according to how they are used and placed in the running text. To model such properties, one could rely on existing resources to providing helpful knowledge to the NER task; some existing studies proved the effectiveness of doing so, and yet are limited in appropriately leveraging the knowledge such as distinguishing the important ones for particular context. In this paper, we improve NER by leveraging different types of syntactic information through attentive ensemble, which functionalizes by the proposed key-value memory networks, syntax attention, and the gate mechanism for encoding, weighting and aggregating such syntactic information, respectively. Experimental results on six English and Chinese benchmark datasets suggest the effectiveness of the proposed model and show that it outperforms previous studies on all experiment datasets.
Named Entity Recognition for Social Media Texts with Semantic Augmentation
Oct 29, 2020
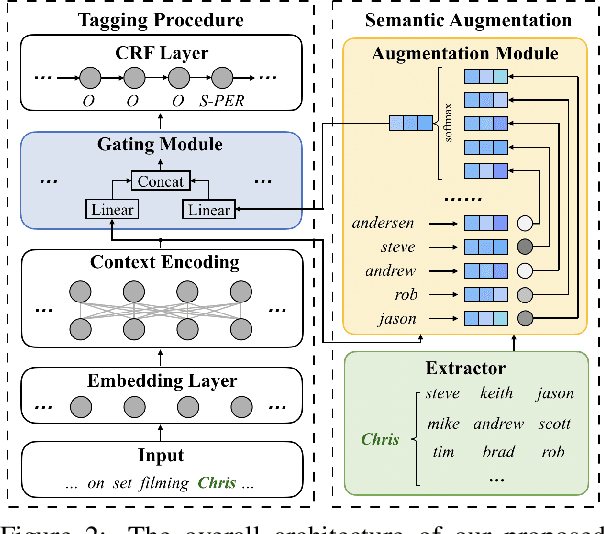


Existing approaches for named entity recognition suffer from data sparsity problems when conducted on short and informal texts, especially user-generated social media content. Semantic augmentation is a potential way to alleviate this problem. Given that rich semantic information is implicitly preserved in pre-trained word embeddings, they are potential ideal resources for semantic augmentation. In this paper, we propose a neural-based approach to NER for social media texts where both local (from running text) and augmented semantics are taken into account. In particular, we obtain the augmented semantic information from a large-scale corpus, and propose an attentive semantic augmentation module and a gate module to encode and aggregate such information, respectively. Extensive experiments are performed on three benchmark datasets collected from English and Chinese social media platforms, where the results demonstrate the superiority of our approach to previous studies across all three datasets.