 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiDesigner: A High-Resolution and Complex-Prompt Following Text-to-Image Diffusion Model for Interior Design
Paper and Code
Dec 19, 2023
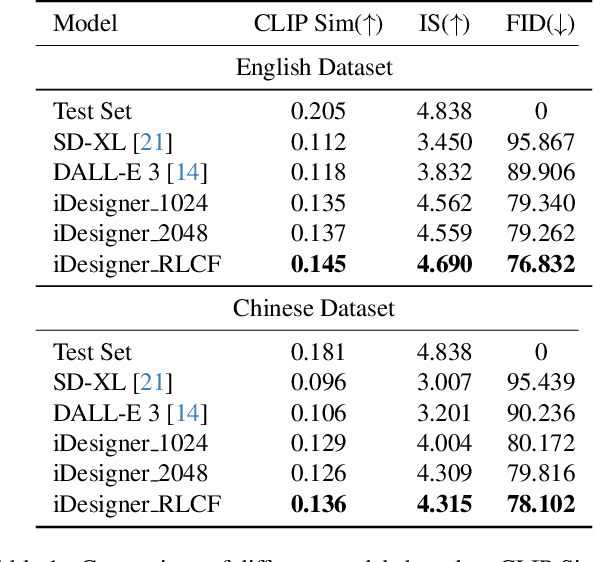

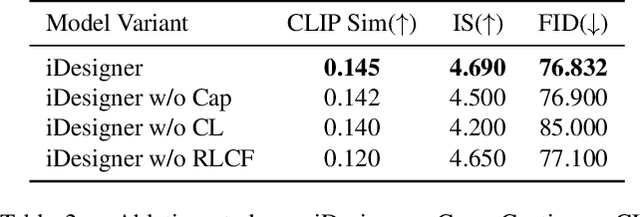
With the open-sourcing of text-to-image models (T2I) such as stable diffusion (SD) and stable diffusion XL (SD-XL), there is an influx of models fine-tuned in specific domains based on the open-source SD model, such as in anime, character portraits, etc. However, there are few specialized models in certain domains, such as interior design, which is attributed to the complex textual descriptions and detailed visual elements inherent in design, alongside the necessity for adaptable resolution. Therefore, text-to-image models for interior design are required to have outstanding prompt-following capabilities, as well as iterative collaboration with design professionals to achieve the desired outcome. In this paper, we collect and optimize text-image data in the design field and continue training in both English and Chinese on the basis of the open-source CLIP model. We also proposed a fine-tuning strategy with curriculum learning and reinforcement learning from CLIP feedback to enhance the prompt-following capabilities of our approach so as to improve the quality of image generation. The experimental results on the collected dataset demonstrate the effectiveness of the proposed approach, which achieves impressive results and outperforms strong baselines.