 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multi-Document Opinion Summarization as Copycat-Review Generation
Paper and Code

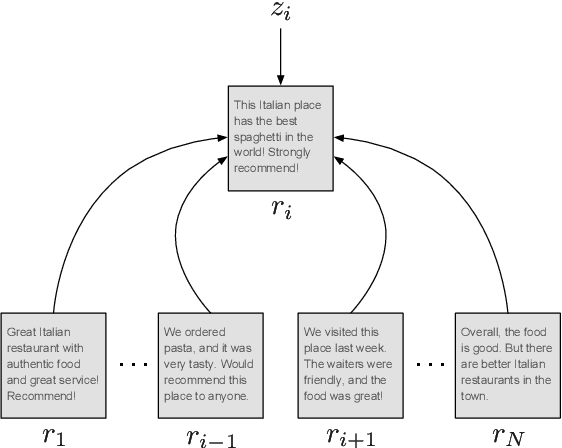
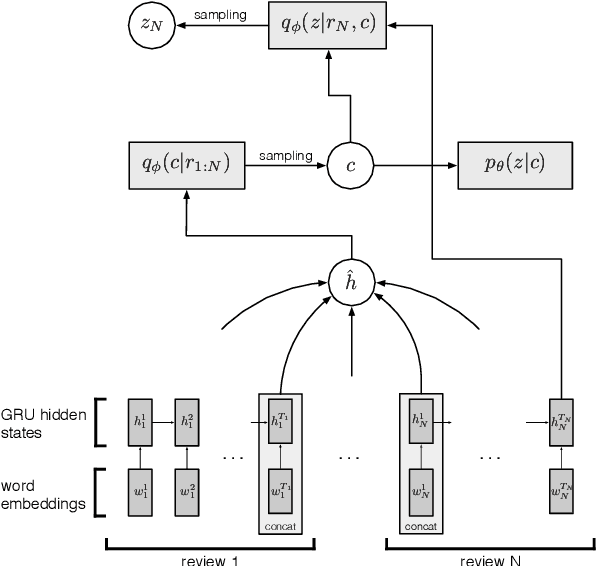
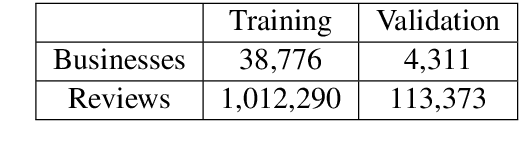
Summarization of opinions is the process of automatically creating text summaries that reflect subjective information expressed in input documents, such as product reviews. While most previous research in opinion summarization has focused on the extractive setting, i.e. selecting fragments of the input documents to produce a summary, we let the model generate novel sentences and hence produce fluent text. Supervised abstractive summarization methods typically rely on large quantities of document-summary pairs which are expensive to acquire. In contrast, we consider the unsupervised setting, in other words, we do not use any summaries in training. We define a generative model for a multi-product review collection. Intuitively, we want to design such a model that, when generating a new review given a set of other reviews of the product, we can control the `amount of novelty' going into the new review or, equivalently, vary the degree of deviation from the input reviews. At test time, when generating summaries, we force the novelty to be minimal, and produce a text reflecting consensus opinions. We capture this intuition by defining a hierarchical variational autoencoder model. Both individual reviews and products they correspond to are associated with stochastic latent codes, and the review generator ('decoder') has direct access to the text of input reviews through the pointer-generator mechanism. In experiments on Amazon and Yelp data, we show that in this model by setting at test time the review's latent code to its mean, we produce fluent and coherent summaries.