 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAspect-Controllable Opinion Summarization
Sep 07, 2021
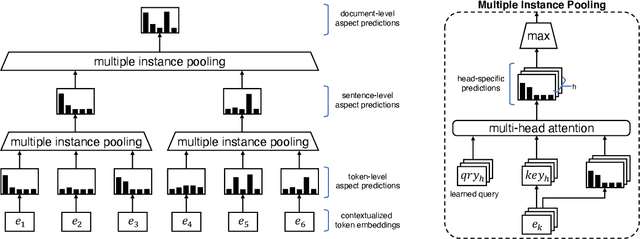
Recent work on opinion summarization produces general summaries based on a set of input reviews and the popularity of opinions expressed in them. In this paper, we propose an approach that allows the generation of customized summaries based on aspect queries (e.g., describing the location and room of a hotel). Using a review corpus, we create a synthetic training dataset of (review, summary) pairs enriched with aspect controllers which are induced by a multi-instance learning model that predicts the aspects of a document at different levels of granularity. We fine-tune a pretrained model using our synthetic dataset and generate aspect-specific summaries by modifying the aspect controllers. Experiments on two benchmarks show that our model outperforms the previous state of the art and generates personalized summaries by controlling the number of aspects discussed in them.
Convex Aggregation for Opinion Summarization
Apr 03, 2021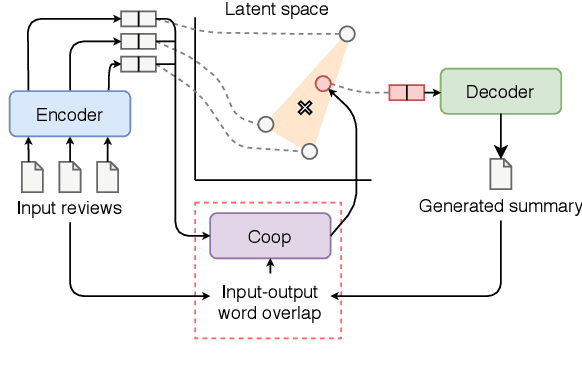
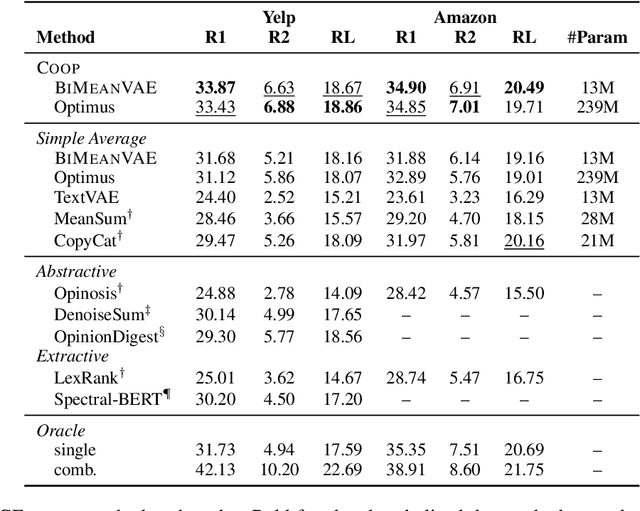
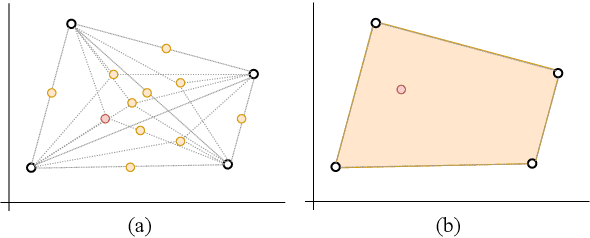
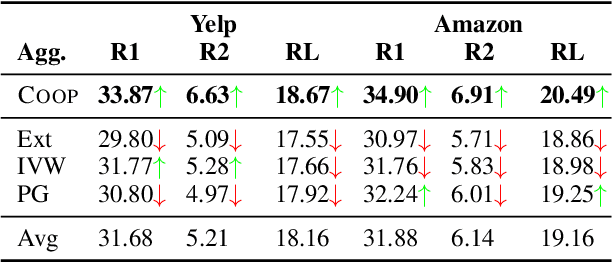
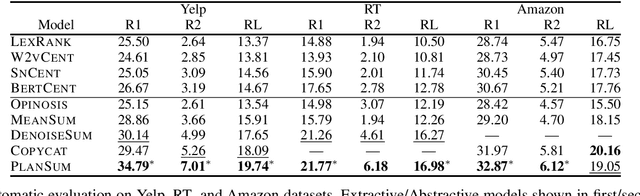
Recent approaches for unsupervised opinion summarization have predominantly used the review reconstruction training paradigm. An encoder-decoder model is trained to reconstruct single reviews and learns a latent review encoding space. At summarization time, the unweighted average of latent review vectors is decoded into a summary. In this paper, we challenge the convention of simply averaging the latent vector set, and claim that this simplistic approach fails to consider variations in the quality of input reviews or the idiosyncrasies of the decoder. We propose Coop, a convex vector aggregation framework for opinion summarization, that searches for better combinations of input reviews. Coop requires no further supervision and uses a simple word overlap objective to help the model generate summaries that are more consistent with input reviews. Experimental results show that extending opinion summarizers with Coop results in state-of-the-art performance, with ROUGE-1 improvements of 3.7% and 2.9% on the Yelp and Amazon benchmark datasets, respectively.
Unsupervised Opinion Summarization with Content Planning
Dec 14, 2020
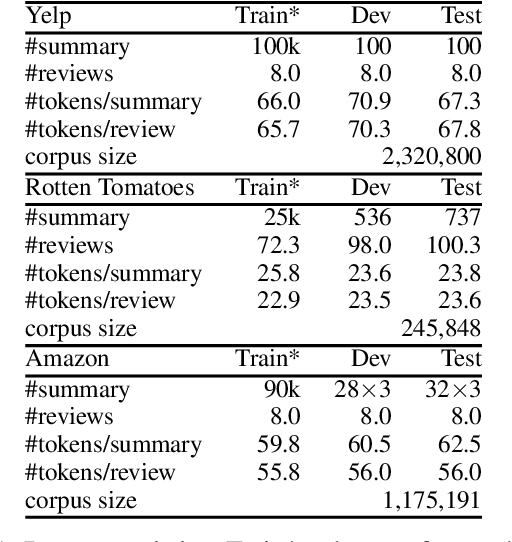
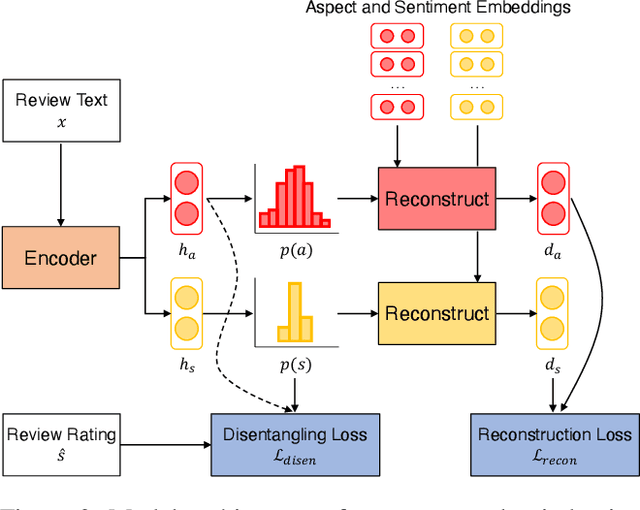
The recent success of deep learning techniques for abstractive summarization is predicated on the availability of large-scale datasets. When summarizing reviews (e.g., for products or movies), such training data is neither available nor can be easily sourced, motivating the development of methods which rely on synthetic datasets for supervised training. We show that explicitly incorporating content planning in a summarization model not only yields output of higher quality, but also allows the creation of synthetic datasets which are more natural, resembling real world document-summary pairs. Our content plans take the form of aspect and sentiment distributions which we induce from data without access to expensive annotations. Synthetic datasets are created by sampling pseudo-reviews from a Dirichlet distribution parametrized by our content planner, while our model generates summaries based on input reviews and induced content plans. Experimental results on three domains show that our approach outperforms competitive models in generating informative, coherent, and fluent summaries that capture opinion consensus.
Extractive Opinion Summarization in Quantized Transformer Spaces
Dec 08, 2020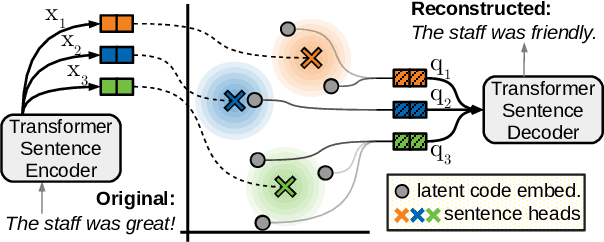

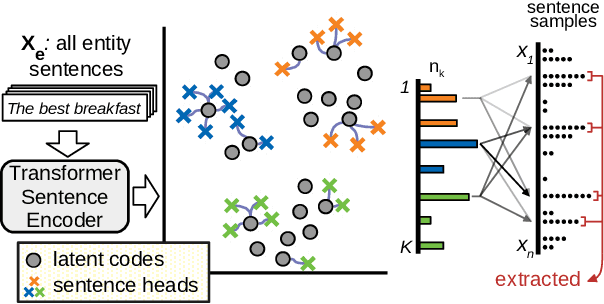
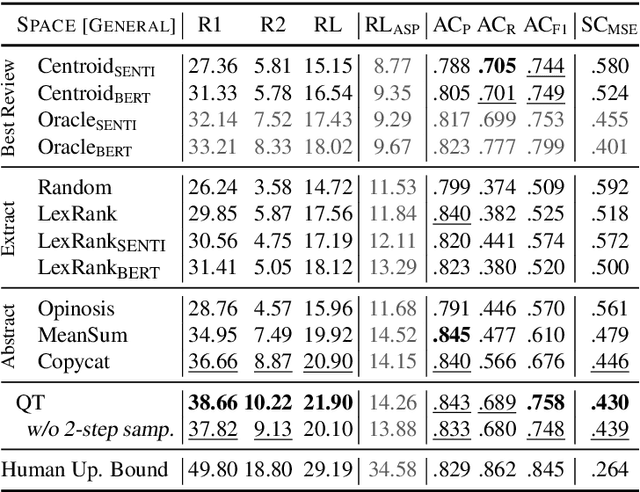
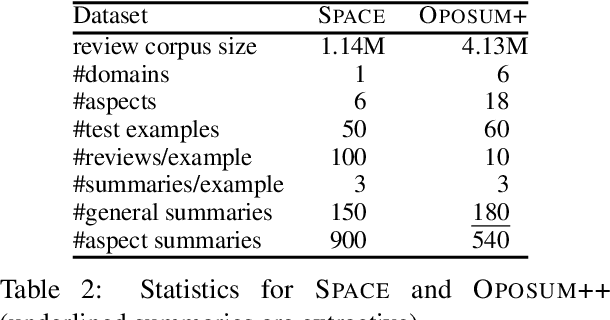
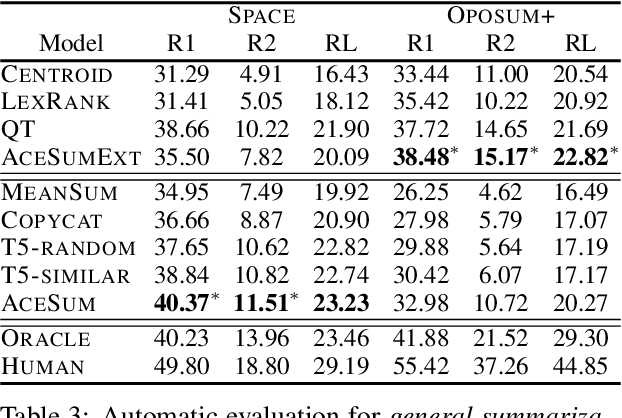
We present the Quantized Transformer (QT), an unsupervised system for extractive opinion summarization. QT is inspired by Vector-Quantized Variational Autoencoders, which we repurpose for popularity-driven summarization. It uses a clustering interpretation of the quantized space and a novel extraction algorithm to discover popular opinions among hundreds of reviews, a significant step towards opinion summarization of practical scope. In addition, QT enables controllable summarization without further training, by utilizing properties of the quantized space to extract aspect-specific summaries. We also make publicly available SPACE, a large-scale evaluation benchmark for opinion summarizers, comprising general and aspect-specific summaries for 50 hotels. Experiments demonstrate the promise of our approach, which is validated by human studies where judges showed clear preference for our method over competitive baselines.
ExplainIt: Explainable Review Summarization with Opinion Causality Graphs
May 29, 2020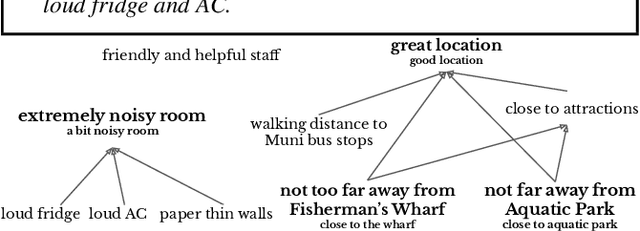


We present ExplainIt, a review summarization system centered around opinion explainability: the simple notion of high-level opinions (e.g. "noisy room") being explainable by lower-level ones (e.g., "loud fridge"). ExplainIt utilizes a combination of supervised and unsupervised components to mine the opinion phrases from reviews and organize them in an Opinion Causality Graph (OCG), a novel semi-structured representation which summarizes causal relations. To construct an OCG, we cluster semantically similar opinions in single nodes, thus canonicalizing opinion paraphrases, and draw directed edges between node pairs that are likely connected by a causal relation. OCGs can be used to generate structured summaries at different levels of granularity and for certain aspects of interest, while simultaneously providing explanations. In this paper, we present the system's individual components and evaluate their effectiveness on their respective sub-tasks, where we report substantial improvements over baselines across two domains. Finally, we validate these results with a user study, showing that ExplainIt produces reasonable opinion explanations according to human judges.
OpinionDigest: A Simple Framework for Opinion Summarization
May 05, 2020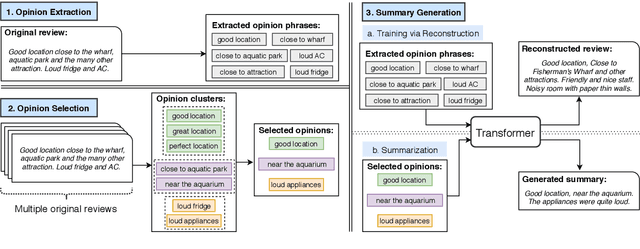
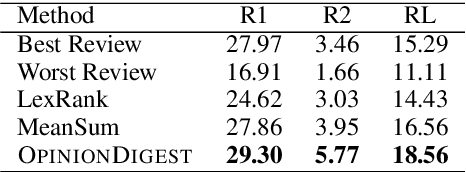
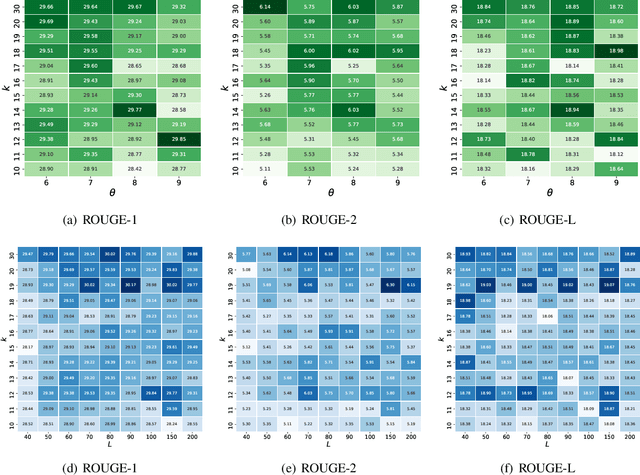
We present OpinionDigest, an abstractive opinion summarization framework, which does not rely on gold-standard summaries for training. The framework uses an Aspect-based Sentiment Analysis model to extract opinion phrases from reviews, and trains a Transformer model to reconstruct the original reviews from these extractions. At summarization time, we merge extractions from multiple reviews and select the most popular ones. The selected opinions are used as input to the trained Transformer model, which verbalizes them into an opinion summary. OpinionDigest can also generate customized summaries, tailored to specific user needs, by filtering the selected opinions according to their aspect and/or sentiment. Automatic evaluation on Yelp data shows that our framework outperforms competitive baselines. Human studies on two corpora verify that OpinionDigest produces informative summaries and shows promising customization capabilities.
BookQA: Stories of Challenges and Opportunities
Oct 02, 2019
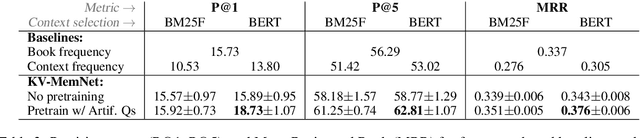
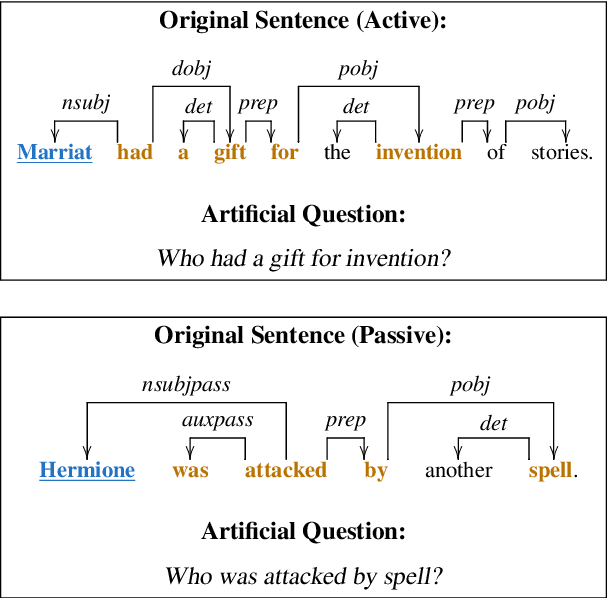
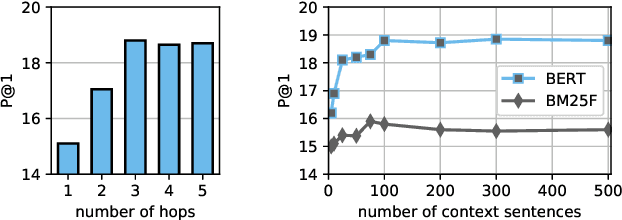
We present a system for answering questions based on the full text of books (BookQA), which first selects book passages given a question at hand, and then uses a memory network to reason and predict an answer. To improve generalization, we pretrain our memory network using artificial questions generated from book sentences. We experiment with the recently published NarrativeQA corpus, on the subset of Who questions, which expect book characters as answers. We experimentally show that BERT-based retrieval and pretraining improve over baseline results significantly. At the same time, we confirm that NarrativeQA is a highly challenging data set, and that there is need for novel research in order to achieve high-precision BookQA results. We analyze some of the bottlenecks of the current approach, and we argue that more research is needed on text representation, retrieval of relevant passages, and reasoning, including commonsense knowledge.
Summarizing Opinions: Aspect Extraction Meets Sentiment Prediction and They Are Both Weakly Supervised
Aug 27, 2018

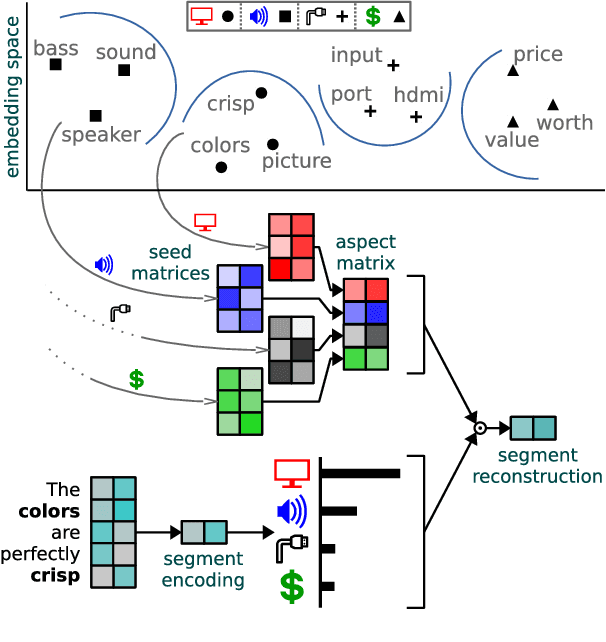

We present a neural framework for opinion summarization from online product reviews which is knowledge-lean and only requires light supervision (e.g., in the form of product domain labels and user-provided ratings). Our method combines two weakly supervised components to identify salient opinions and form extractive summaries from multiple reviews: an aspect extractor trained under a multi-task objective, and a sentiment predictor based on multiple instance learning. We introduce an opinion summarization dataset that includes a training set of product reviews from six diverse domains and human-annotated development and test sets with gold standard aspect annotations, salience labels, and opinion summaries. Automatic evaluation shows significant improvements over baselines, and a large-scale study indicates that our opinion summaries are preferred by human judges according to multiple criteria.
Multiple Instance Learning Networks for Fine-Grained Sentiment Analysis
Jan 26, 2018We consider the task of fine-grained sentiment analysis from the perspective of multiple instance learning (MIL). Our neural model is trained on document sentiment labels, and learns to predict the sentiment of text segments, i.e. sentences or elementary discourse units (EDUs), without segment-level supervision. We introduce an attention-based polarity scoring method for identifying positive and negative text snippets and a new dataset which we call SPOT (as shorthand for Segment-level POlariTy annotations) for evaluating MIL-style sentiment models like ours. Experimental results demonstrate superior performance against multiple baselines, whereas a judgement elicitation study shows that EDU-level opinion extraction produces more informative summaries than sentence-based alternatives.
* Final published version. Please cite using appropriate date (2018). Link to journal: http://www.transacl.org/ojs/index.php/tacl/article/view/1225/277