 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Beyond English: Counterfactual Tests for Bias in Sentiment Analysis in Four Languages
May 19, 2023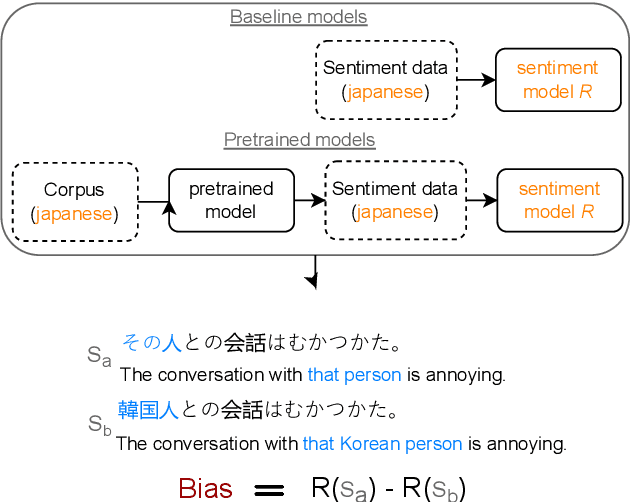


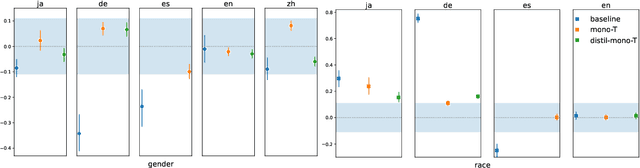
Sentiment analysis (SA) systems are used in many products and hundreds of languages. Gender and racial biases are well-studied in English SA systems, but understudied in other languages, with few resources for such studies. To remedy this, we build a counterfactual evaluation corpus for gender and racial/migrant bias in four languages. We demonstrate its usefulness by answering a simple but important question that an engineer might need to answer when deploying a system: What biases do systems import from pre-trained models when compared to a baseline with no pre-training? Our evaluation corpus, by virtue of being counterfactual, not only reveals which models have less bias, but also pinpoints changes in model bias behaviour, which enables more targeted mitigation strategies. We release our code and evaluation corpora to facilitate future research.
BookQA: Stories of Challenges and Opportunities
Oct 02, 2019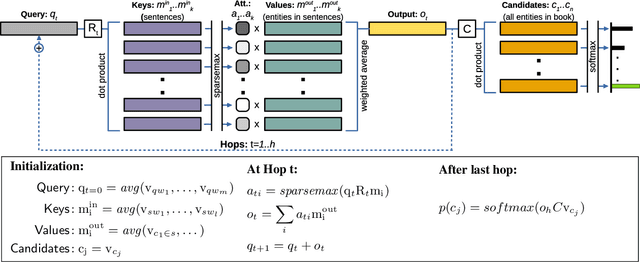
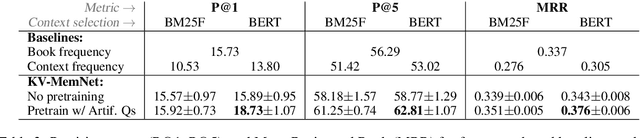
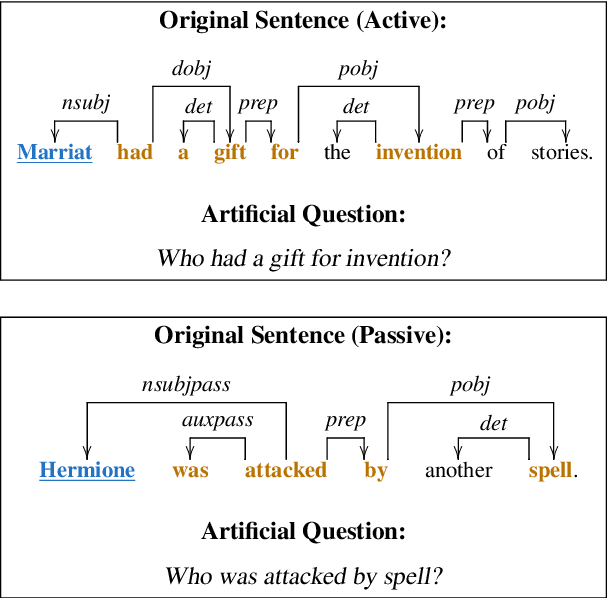
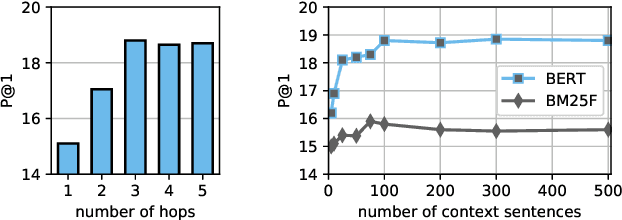
We present a system for answering questions based on the full text of books (BookQA), which first selects book passages given a question at hand, and then uses a memory network to reason and predict an answer. To improve generalization, we pretrain our memory network using artificial questions generated from book sentences. We experiment with the recently published NarrativeQA corpus, on the subset of Who questions, which expect book characters as answers. We experimentally show that BERT-based retrieval and pretraining improve over baseline results significantly. At the same time, we confirm that NarrativeQA is a highly challenging data set, and that there is need for novel research in order to achieve high-precision BookQA results. We analyze some of the bottlenecks of the current approach, and we argue that more research is needed on text representation, retrieval of relevant passages, and reasoning, including commonsense knowledge.
TwitterPaul: Extracting and Aggregating Twitter Predictions
Nov 30, 2012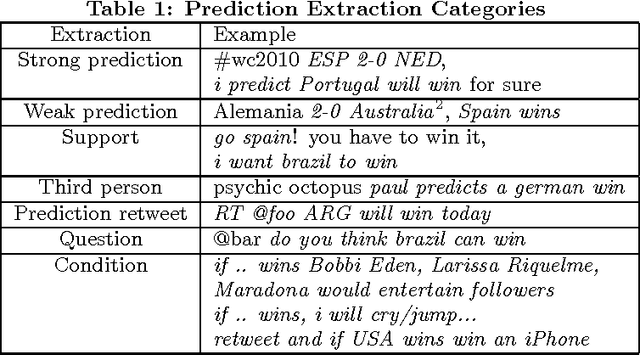
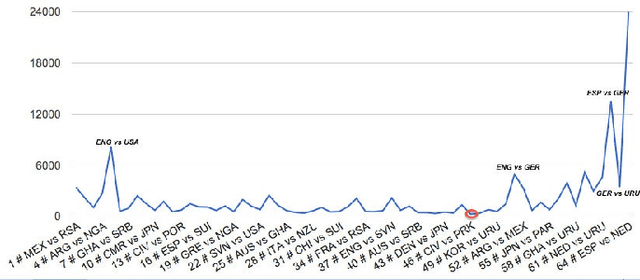
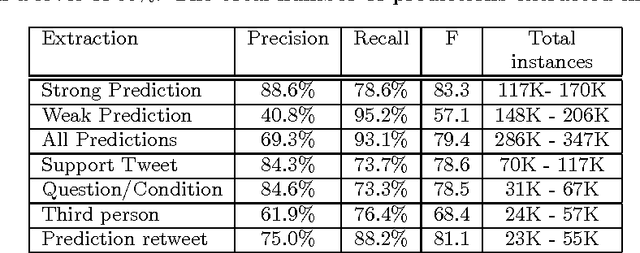
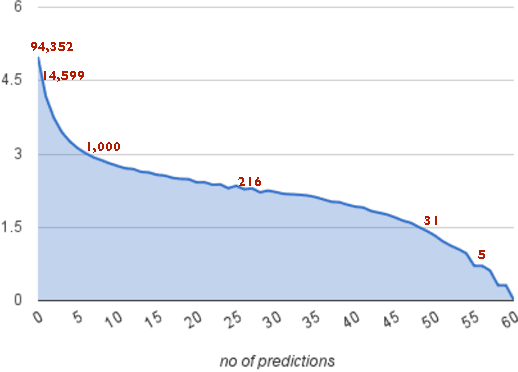
This paper introduces TwitterPaul, a system designed to make use of Social Media data to help to predict game outcomes for the 2010 FIFA World Cup tournament. To this end, we extracted over 538K mentions to football games from a large sample of tweets that occurred during the World Cup, and we classified into different types with a precision of up to 88%. The different mentions were aggregated in order to make predictions about the outcomes of the actual games. We attempt to learn which Twitter users are accurate predictors and explore several techniques in order to exploit this information to make more accurate predictions. We compare our results to strong baselines and against the betting line (prediction market) and found that the quality of extractions is more important than the quantity, suggesting that high precision methods working on a medium-sized dataset are preferable over low precision methods that use a larger amount of data. Finally, by aggregating some classes of predictions, the system performance is close to the one of the betting line. Furthermore, we believe that this domain independent framework can help to predict other sports, elections, product release dates and other future events that people talk about in social media.