 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempEval-3: Evaluating Events, Time Expressions, and Temporal Relations
May 25, 2014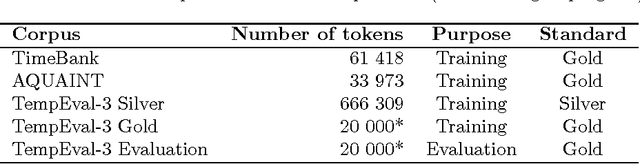
We describe the TempEval-3 task which is currently in preparation for the SemEval-2013 evaluation exercise. The aim of TempEval is to advance research on temporal information processing. TempEval-3 follows on from previous TempEval events, incorporating: a three-part task structure covering event, temporal expression and temporal relation extraction; a larger dataset; and single overall task quality scores.
TimeML-strict: clarifying temporal annotation
Apr 26, 2013TimeML is an XML-based schema for annotating temporal information over discourse. The standard has been used to annotate a variety of resources and is followed by a number of tools, the creation of which constitute hundreds of thousands of man-hours of research work. However, the current state of resources is such that many are not valid, or do not produce valid output, or contain ambiguous or custom additions and removals. Difficulties arising from these variances were highlighted in the TempEval-3 exercise, which included its own extra stipulations over conventional TimeML as a response. To unify the state of current resources, and to make progress toward easy adoption of its current incarnation ISO-TimeML, this paper introduces TimeML-strict: a valid, unambiguous, and easy-to-process subset of TimeML. We also introduce three resources -- a schema for TimeML-strict; a validator tool for TimeML-strict, so that one may ensure documents are in the correct form; and a repair tool that corrects common invalidating errors and adds disambiguating markup in order to convert documents from the laxer TimeML standard to TimeML-strict.
TwitterPaul: Extracting and Aggregating Twitter Predictions
Nov 30, 2012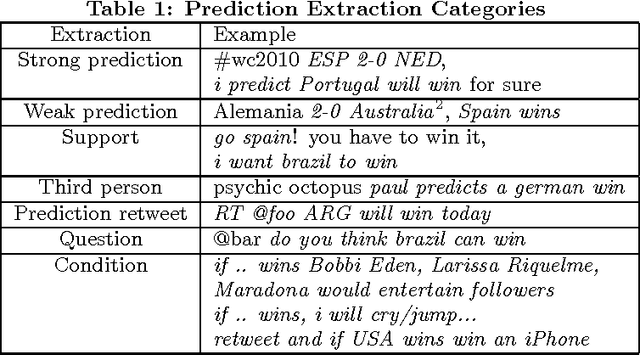
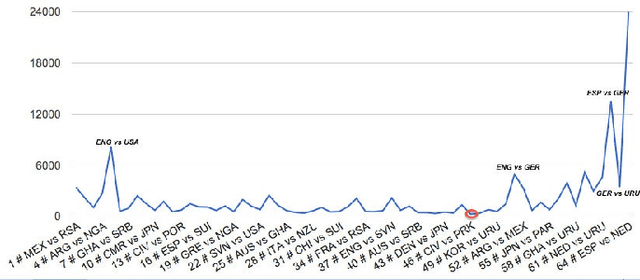
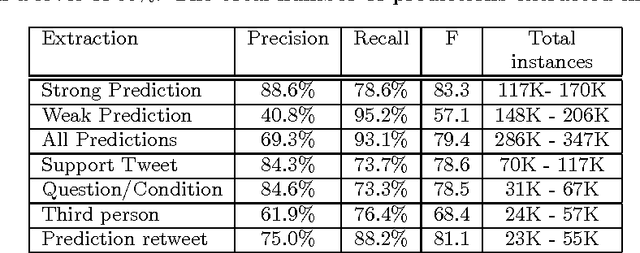
This paper introduces TwitterPaul, a system designed to make use of Social Media data to help to predict game outcomes for the 2010 FIFA World Cup tournament. To this end, we extracted over 538K mentions to football games from a large sample of tweets that occurred during the World Cup, and we classified into different types with a precision of up to 88%. The different mentions were aggregated in order to make predictions about the outcomes of the actual games. We attempt to learn which Twitter users are accurate predictors and explore several techniques in order to exploit this information to make more accurate predictions. We compare our results to strong baselines and against the betting line (prediction market) and found that the quality of extractions is more important than the quantity, suggesting that high precision methods working on a medium-sized dataset are preferable over low precision methods that use a larger amount of data. Finally, by aggregating some classes of predictions, the system performance is close to the one of the betting line. Furthermore, we believe that this domain independent framework can help to predict other sports, elections, product release dates and other future events that people talk about in social media.