 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Craftax: Benchmarking Open-Ended Multi-Agent Reinforcement Learning at the Hyperscale
Nov 07, 2025Progress in multi-agent reinforcement learning (MARL) requires challenging benchmarks that assess the limits of current methods. However, existing benchmarks often target narrow short-horizon challenges that do not adequately stress the long-term dependencies and generalization capabilities inherent in many multi-agent systems. To address this, we first present \textit{Craftax-MA}: an extension of the popular open-ended RL environment, Craftax, that supports multiple agents and evaluates a wide range of general abilities within a single environment. Written in JAX, \textit{Craftax-MA} is exceptionally fast with a training run using 250 million environment interactions completing in under an hour. To provide a more compelling challenge for MARL, we also present \textit{Craftax-Coop}, an extension introducing heterogeneous agents, trading and more mechanics that require complex cooperation among agents for success. We provide analysis demonstrating that existing algorithms struggle with key challenges in this benchmark, including long-horizon credit assignment, exploration and cooperation, and argue for its potential to drive long-term research in MARL.
Kinetix: Investigating the Training of General Agents through Open-Ended Physics-Based Control Tasks
Oct 30, 2024While large models trained with self-supervised learning on offline datasets have shown remarkable capabilities in text and image domains, achieving the same generalisation for agents that act in sequential decision problems remains an open challenge. In this work, we take a step towards this goal by procedurally generating tens of millions of 2D physics-based tasks and using these to train a general reinforcement learning (RL) agent for physical control. To this end, we introduce Kinetix: an open-ended space of physics-based RL environments that can represent tasks ranging from robotic locomotion and grasping to video games and classic RL environments, all within a unified framework. Kinetix makes use of our novel hardware-accelerated physics engine Jax2D that allows us to cheaply simulate billions of environment steps during training. Our trained agent exhibits strong physical reasoning capabilities, being able to zero-shot solve unseen human-designed environments. Furthermore, fine-tuning this general agent on tasks of interest shows significantly stronger performance than training an RL agent *tabula rasa*. This includes solving some environments that standard RL training completely fails at. We believe this demonstrates the feasibility of large scale, mixed-quality pre-training for online RL and we hope that Kinetix will serve as a useful framework to investigate this further.
JaxLife: An Open-Ended Agentic Simulator
Sep 01, 2024Human intelligence emerged through the process of natural selection and evolution on Earth. We investigate what it would take to re-create this process in silico. While past work has often focused on low-level processes (such as simulating physics or chemistry), we instead take a more targeted approach, aiming to evolve agents that can accumulate open-ended culture and technologies across generations. Towards this, we present JaxLife: an artificial life simulator in which embodied agents, parameterized by deep neural networks, must learn to survive in an expressive world containing programmable systems. First, we describe the environment and show that it can facilitate meaningful Turing-complete computation. We then analyze the evolved emergent agents' behavior, such as rudimentary communication protocols, agriculture, and tool use. Finally, we investigate how complexity scales with the amount of compute used. We believe JaxLife takes a step towards studying evolved behavior in more open-ended simulations. Our code is available at https://github.com/luchris429/JaxLife
Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning
Feb 26, 2024

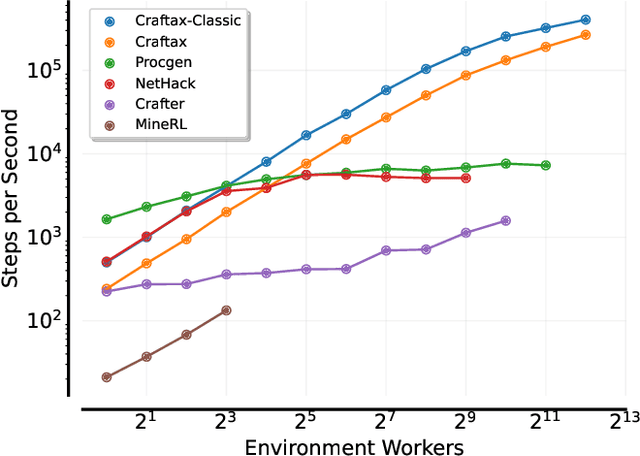

Benchmarks play a crucial role in the development and analysis of reinforcement learning (RL) algorithms. We identify that existing benchmarks used for research into open-ended learning fall into one of two categories. Either they are too slow for meaningful research to be performed without enormous computational resources, like Crafter, NetHack and Minecraft, or they are not complex enough to pose a significant challenge, like Minigrid and Procgen. To remedy this, we first present Craftax-Classic: a ground-up rewrite of Crafter in JAX that runs up to 250x faster than the Python-native original. A run of PPO using 1 billion environment interactions finishes in under an hour using only a single GPU and averages 90% of the optimal reward. To provide a more compelling challenge we present the main Craftax benchmark, a significant extension of the Crafter mechanics with elements inspired from NetHack. Solving Craftax requires deep exploration, long term planning and memory, as well as continual adaptation to novel situations as more of the world is discovered. We show that existing methods including global and episodic exploration, as well as unsupervised environment design fail to make material progress on the benchmark. We believe that Craftax can for the first time allow researchers to experiment in a complex, open-ended environment with limited computational resources.
Refining Minimax Regret for Unsupervised Environment Design
Feb 19, 2024In unsupervised environment design, reinforcement learning agents are trained on environment configurations (levels) generated by an adversary that maximises some objective. Regret is a commonly used objective that theoretically results in a minimax regret (MMR) policy with desirable robustness guarantees; in particular, the agent's maximum regret is bounded. However, once the agent reaches this regret bound on all levels, the adversary will only sample levels where regret cannot be further reduced. Although there are possible performance improvements to be made outside of these regret-maximising levels, learning stagnates. In this work, we introduce Bayesian level-perfect MMR (BLP), a refinement of the minimax regret objective that overcomes this limitation. We formally show that solving for this objective results in a subset of MMR policies, and that BLP policies act consistently with a Perfect Bayesian policy over all levels. We further introduce an algorithm, ReMiDi, that results in a BLP policy at convergence. We empirically demonstrate that training on levels from a minimax regret adversary causes learning to prematurely stagnate, but that ReMiDi continues learning.
Hierarchical Kickstarting for Skill Transfer in Reinforcement Learning
Jul 23, 2022
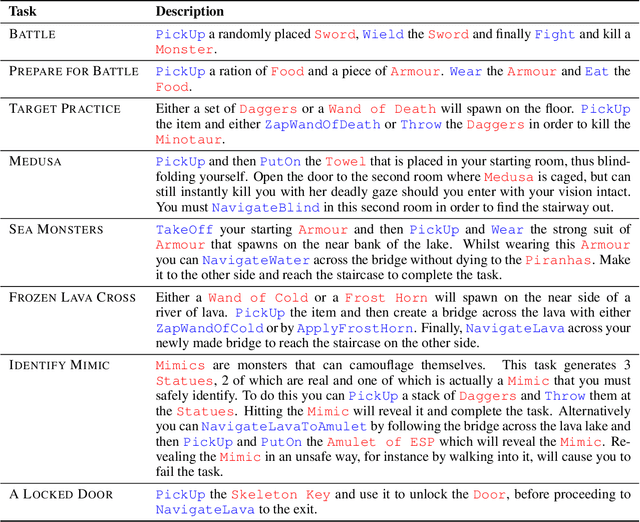

Practising and honing skills forms a fundamental component of how humans learn, yet artificial agents are rarely specifically trained to perform them. Instead, they are usually trained end-to-end, with the hope being that useful skills will be implicitly learned in order to maximise discounted return of some extrinsic reward function. In this paper, we investigate how skills can be incorporated into the training of reinforcement learning (RL) agents in complex environments with large state-action spaces and sparse rewards. To this end, we created SkillHack, a benchmark of tasks and associated skills based on the game of NetHack. We evaluate a number of baselines on this benchmark, as well as our own novel skill-based method Hierarchical Kickstarting (HKS), which is shown to outperform all other evaluated methods. Our experiments show that learning with a prior knowledge of useful skills can significantly improve the performance of agents on complex problems. We ultimately argue that utilising predefined skills provides a useful inductive bias for RL problems, especially those with large state-action spaces and sparse rewards.
TwitterPaul: Extracting and Aggregating Twitter Predictions
Nov 30, 2012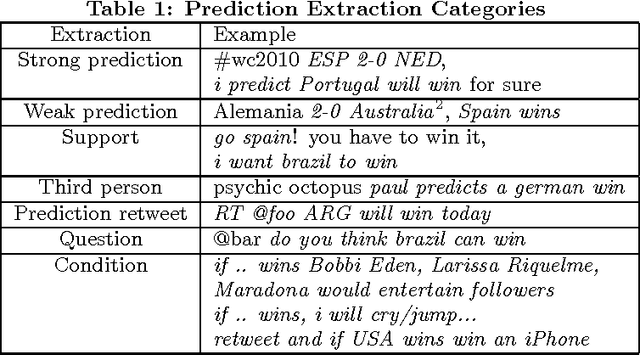
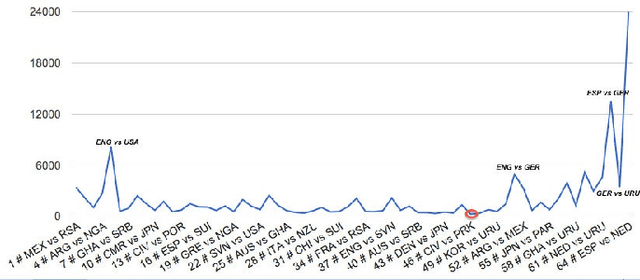
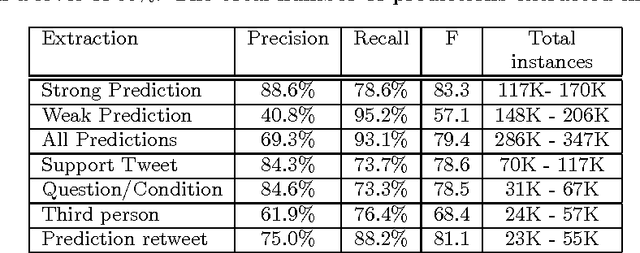
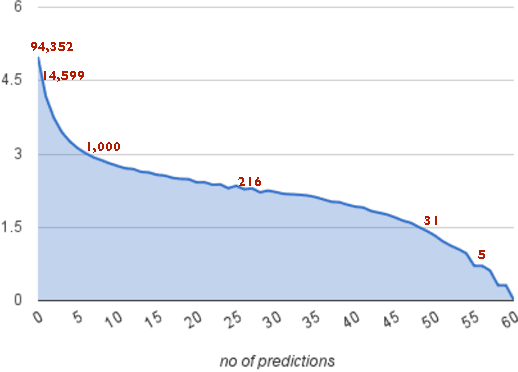
This paper introduces TwitterPaul, a system designed to make use of Social Media data to help to predict game outcomes for the 2010 FIFA World Cup tournament. To this end, we extracted over 538K mentions to football games from a large sample of tweets that occurred during the World Cup, and we classified into different types with a precision of up to 88%. The different mentions were aggregated in order to make predictions about the outcomes of the actual games. We attempt to learn which Twitter users are accurate predictors and explore several techniques in order to exploit this information to make more accurate predictions. We compare our results to strong baselines and against the betting line (prediction market) and found that the quality of extractions is more important than the quantity, suggesting that high precision methods working on a medium-sized dataset are preferable over low precision methods that use a larger amount of data. Finally, by aggregating some classes of predictions, the system performance is close to the one of the betting line. Furthermore, we believe that this domain independent framework can help to predict other sports, elections, product release dates and other future events that people talk about in social media.