 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempEval-3: Evaluating Events, Time Expressions, and Temporal Relations
May 25, 2014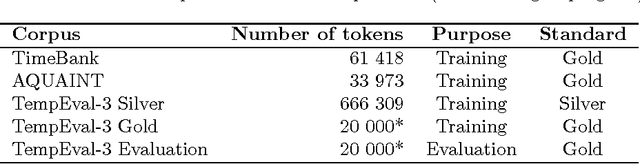
We describe the TempEval-3 task which is currently in preparation for the SemEval-2013 evaluation exercise. The aim of TempEval is to advance research on temporal information processing. TempEval-3 follows on from previous TempEval events, incorporating: a three-part task structure covering event, temporal expression and temporal relation extraction; a larger dataset; and single overall task quality scores.
Enhancing QA Systems with Complex Temporal Question Processing Capabilities
Jan 15, 2014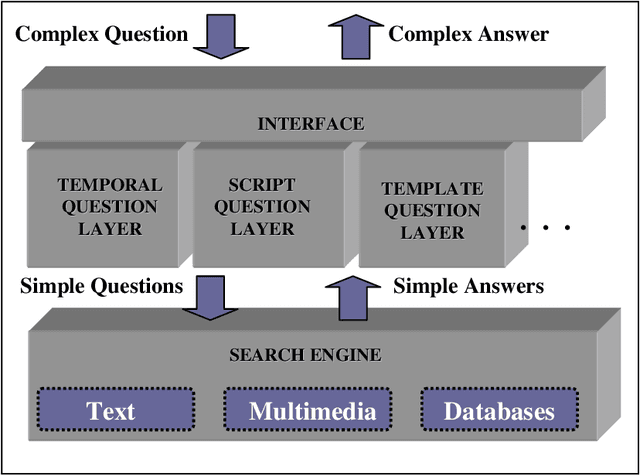

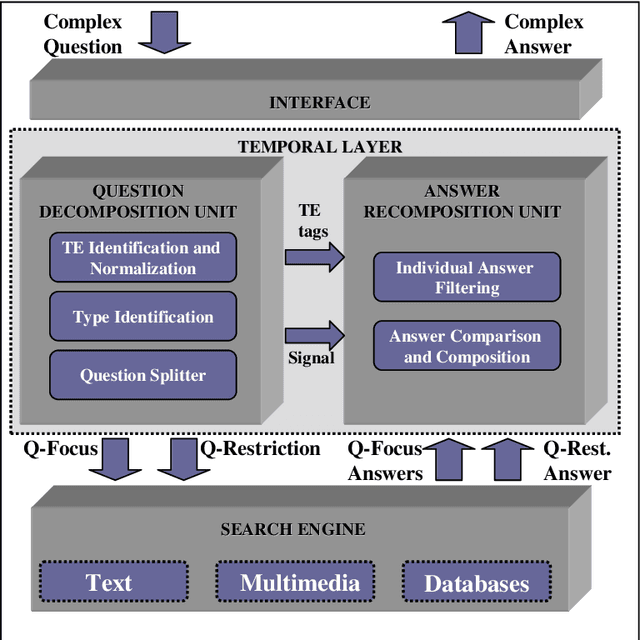

This paper presents a multilayered architecture that enhances the capabilities of current QA systems and allows different types of complex questions or queries to be processed. The answers to these questions need to be gathered from factual information scattered throughout different documents. Specifically, we designed a specialized layer to process the different types of temporal questions. Complex temporal questions are first decomposed into simple questions, according to the temporal relations expressed in the original question. In the same way, the answers to the resulting simple questions are recomposed, fulfilling the temporal restrictions of the original complex question. A novel aspect of this approach resides in the decomposition which uses a minimal quantity of resources, with the final aim of obtaining a portable platform that is easily extensible to other languages. In this paper we also present a methodology for evaluation of the decomposition of the questions as well as the ability of the implemented temporal layer to perform at a multilingual level. The temporal layer was first performed for English, then evaluated and compared with: a) a general purpose QA system (F-measure 65.47% for QA plus English temporal layer vs. 38.01% for the general QA system), and b) a well-known QA system. Much better results were obtained for temporal questions with the multilayered system. This system was therefore extended to Spanish and very good results were again obtained in the evaluation (F-measure 40.36% for QA plus Spanish temporal layer vs. 22.94% for the general QA system).
TimeML-strict: clarifying temporal annotation
Apr 26, 2013TimeML is an XML-based schema for annotating temporal information over discourse. The standard has been used to annotate a variety of resources and is followed by a number of tools, the creation of which constitute hundreds of thousands of man-hours of research work. However, the current state of resources is such that many are not valid, or do not produce valid output, or contain ambiguous or custom additions and removals. Difficulties arising from these variances were highlighted in the TempEval-3 exercise, which included its own extra stipulations over conventional TimeML as a response. To unify the state of current resources, and to make progress toward easy adoption of its current incarnation ISO-TimeML, this paper introduces TimeML-strict: a valid, unambiguous, and easy-to-process subset of TimeML. We also introduce three resources -- a schema for TimeML-strict; a validator tool for TimeML-strict, so that one may ensure documents are in the correct form; and a repair tool that corrects common invalidating errors and adds disambiguating markup in order to convert documents from the laxer TimeML standard to TimeML-strict.