 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Temporal Information and Topic Modeling for Cross-Document Event Ordering
Jun 10, 2015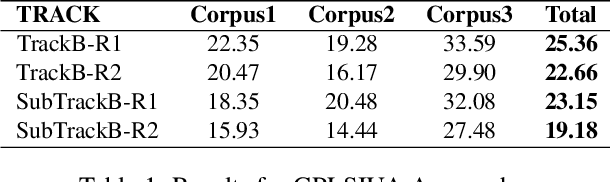
Building unified timelines from a collection of written news articles requires cross-document event coreference resolution and temporal relation extraction. In this paper we present an approach event coreference resolution according to: a) similar temporal information, and b) similar semantic arguments. Temporal information is detected using an automatic temporal information system (TIPSem), while semantic information is represented by means of LDA Topic Modeling. The evaluation of our approach shows that it obtains the highest Micro-average F-score results in the SemEval2015 Task 4: TimeLine: Cross-Document Event Ordering (25.36\% for TrackB, 23.15\% for SubtrackB), with an improvement of up to 6\% in comparison to the other systems. However, our experiment also showed some draw-backs in the Topic Modeling approach that degrades performance of the system.
* 5 pages
Enhancing QA Systems with Complex Temporal Question Processing Capabilities
Jan 15, 2014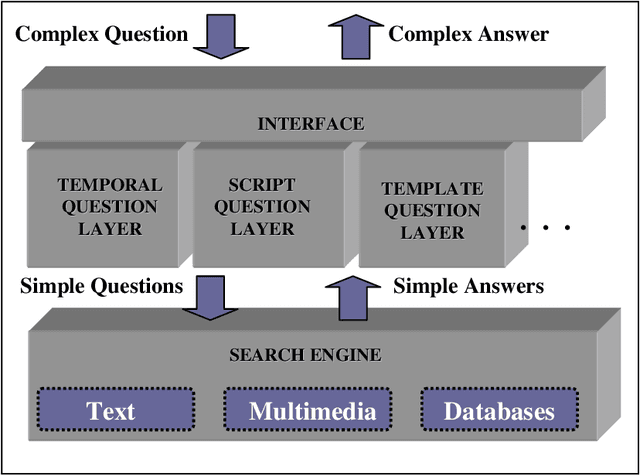

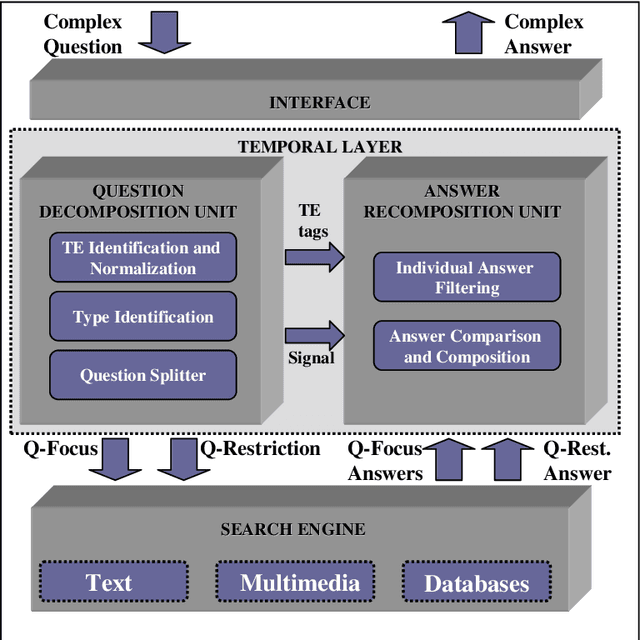

This paper presents a multilayered architecture that enhances the capabilities of current QA systems and allows different types of complex questions or queries to be processed. The answers to these questions need to be gathered from factual information scattered throughout different documents. Specifically, we designed a specialized layer to process the different types of temporal questions. Complex temporal questions are first decomposed into simple questions, according to the temporal relations expressed in the original question. In the same way, the answers to the resulting simple questions are recomposed, fulfilling the temporal restrictions of the original complex question. A novel aspect of this approach resides in the decomposition which uses a minimal quantity of resources, with the final aim of obtaining a portable platform that is easily extensible to other languages. In this paper we also present a methodology for evaluation of the decomposition of the questions as well as the ability of the implemented temporal layer to perform at a multilingual level. The temporal layer was first performed for English, then evaluated and compared with: a) a general purpose QA system (F-measure 65.47% for QA plus English temporal layer vs. 38.01% for the general QA system), and b) a well-known QA system. Much better results were obtained for temporal questions with the multilayered system. This system was therefore extended to Spanish and very good results were again obtained in the evaluation (F-measure 40.36% for QA plus Spanish temporal layer vs. 22.94% for the general QA system).
Massively Increasing TIMEX3 Resources: A Transduction Approach
Mar 22, 2012


Automatic annotation of temporal expressions is a research challenge of great interest in the field of information extraction. Gold standard temporally-annotated resources are limited in size, which makes research using them difficult. Standards have also evolved over the past decade, so not all temporally annotated data is in the same format. We vastly increase available human-annotated temporal expression resources by converting older format resources to TimeML/TIMEX3. This task is difficult due to differing annotation methods. We present a robust conversion tool and a new, large temporal expression resource. Using this, we evaluate our conversion process by using it as training data for an existing TimeML annotation tool, achieving a 0.87 F1 measure -- better than any system in the TempEval-2 timex recognition exercise.
* Proc. LREC (2012)