 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Generative Artificial Intelligence: Roadmap for Natural Language Generation
Jul 15, 2024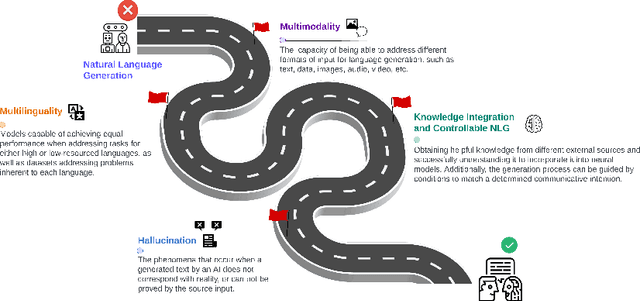



Generative Artificial Intelligence has grown exponentially as a result of Large Language Models (LLMs). This has been possible because of the impressive performance of deep learning methods created within the field of Natural Language Processing (NLP) and its subfield Natural Language Generation (NLG), which is the focus of this paper. Within the growing LLM family are the popular GPT-4, Bard and more specifically, tools such as ChatGPT have become a benchmark for other LLMs when solving most of the tasks involved in NLG research. This scenario poses new questions about the next steps for NLG and how the field can adapt and evolve to deal with new challenges in the era of LLMs. To address this, the present paper conducts a review of a representative sample of surveys recently published in NLG. By doing so, we aim to provide the scientific community with a research roadmap to identify which NLG aspects are still not suitably addressed by LLMs, as well as suggest future lines of research that should be addressed going forward.
Combining Temporal Information and Topic Modeling for Cross-Document Event Ordering
Jun 10, 2015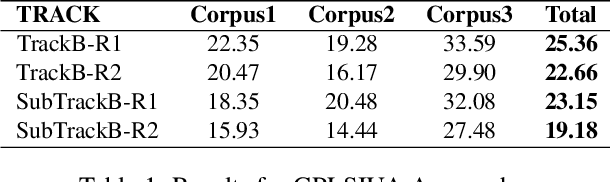
Building unified timelines from a collection of written news articles requires cross-document event coreference resolution and temporal relation extraction. In this paper we present an approach event coreference resolution according to: a) similar temporal information, and b) similar semantic arguments. Temporal information is detected using an automatic temporal information system (TIPSem), while semantic information is represented by means of LDA Topic Modeling. The evaluation of our approach shows that it obtains the highest Micro-average F-score results in the SemEval2015 Task 4: TimeLine: Cross-Document Event Ordering (25.36\% for TrackB, 23.15\% for SubtrackB), with an improvement of up to 6\% in comparison to the other systems. However, our experiment also showed some draw-backs in the Topic Modeling approach that degrades performance of the system.
* 5 pages